
Topic Modeling
Optimizing for Human Interpretability
Problem
Have you ever skimmed through a large amount of text and wanted to quickly understand the general trends, topics, or themes that it contains? This ranges from that book you never finished for book club to parsing through user feedback and comments at work. Well, rest-assured you’re not alone and there are tools out there to help you accomplish this feat, such as* topic modeling*.
Topic modeling is a type of unsupervised machine learning that makes use of clustering to find latent variables or hidden structures in your data. In other words, it’s an approach for finding topics in large amounts of text. Topic modeling is great for document clustering, information retrieval from unstructured text, and feature selection.
Here at Square, we use topic modeling to parse through feedback provided by sellers in free-form text fields. One example is pictured below — a comment section for sellers to leave feedback about why they’ve decided to leave the product and how we can better serve them and other customers like them in the future.
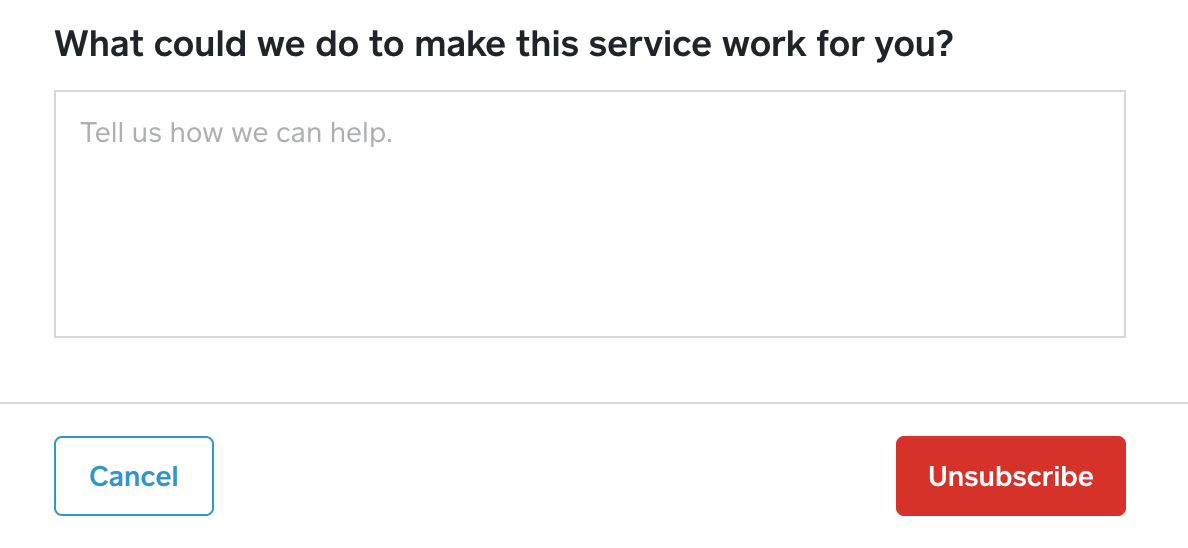 Figure 1: Comment box asking for seller feedback when they unsubscribe
Figure 1: Comment box asking for seller feedback when they unsubscribe
Although topic modeling is a powerful statistical method, it can be difficult to evaluate the effectiveness of a topic model or interpret the results. Two major questions data practitioners ask when using topic modeling are:
1.) What is the best way to determine the number of topics (𝜅) in a topic model?
2.) How do you evaluate and improve the interpretability of a model’s results?
In this article, I’ll walk through a few techniques that can help you answer the above questions.
Data & Methods
When implementing a topic model, it’s important to clean your text data to ensure you get the most precise and meaningful results. This includes common data pre-processing techniques such as tokenization, removing stopwords, and stemming/lemmatization. These are ways to segment documents into their atomic elements of words, remove words that provide little to no meaning, and ensure that root words similar in meaning get their proper weightage of importance in the model.
The next step after adequately cleaning and preparing your corpus is to construct a document-term matrix and train your model on it. This is where the first question of number of topics (𝜅) to choose arises since 𝜅 is a common model parameter for topic models.
Number (𝜅) of Topics
When determining how many topics to use, it’s important to consider both qualitative and quantitative factors. Qualitatively, you should have domain knowledge of the data you’re analyzing and be able to gauge a general ballpark of clusters your data will separate into. There should be enough topics to be able to distinguish between overarching themes in the text but not so many topics that they lose their interpretability. In the case of evaluating our sellers’ text responses, from a qualitative perspective, 10 topics seemed like a reasonable place to start because it gives enough room to capture actionable topics such as functionality and cost without getting to granular.
From a quantitative perspective, some data practitioners use perplexity or predictive likelihood to help determine the optimal number of topics and then evaluate the model fit. Perplexity is calculated by taking the log likelihood of unseen text documents given the topics defined by a topic model. A good model will have a high likelihood and resultantly low perplexity. Usually you would plot these measures over a spectrum of topics and choose the topic that best optimizes for your measure of choice. But sometimes these metrics are not correlated with human interpretability of the model, which can be impractical in a business setting.
Another quantitative solution you can use to evaluate a topic model that has better human interpretability is called* topic coherence*. Topic coherence looks at a set of words in generated topics and rates the interpretability of the topics. There are a number of measures that calculate coherence in various ways, but Cv proves to be the measure most aligned with human interpretability (see Figure 2 below).
Figure 2: Coherence measures and their correlations to human ratings
Because Cv is generally the most interpretable, I used this coherence measure to refine my qualitative selection of 10 topics for our sellers’ text responses using Latent Dirichlet Allocation (LDA).
LDA is a generative statistical topic model used to find accurate sets of topics within a given document set. The model assumes that text documents are comprised of a mix of topics and each topic is comprised of a mix of words. From there, using probability distributions the model can determine which topics are in a given document and which words are in a given topic based on word prevalence across topics and topic prevalence across document. Looking at the topic coherence across a number of topics ranging from 0 to 15, seven was the optimal number of topics to use for this model to maximize topic coherence.
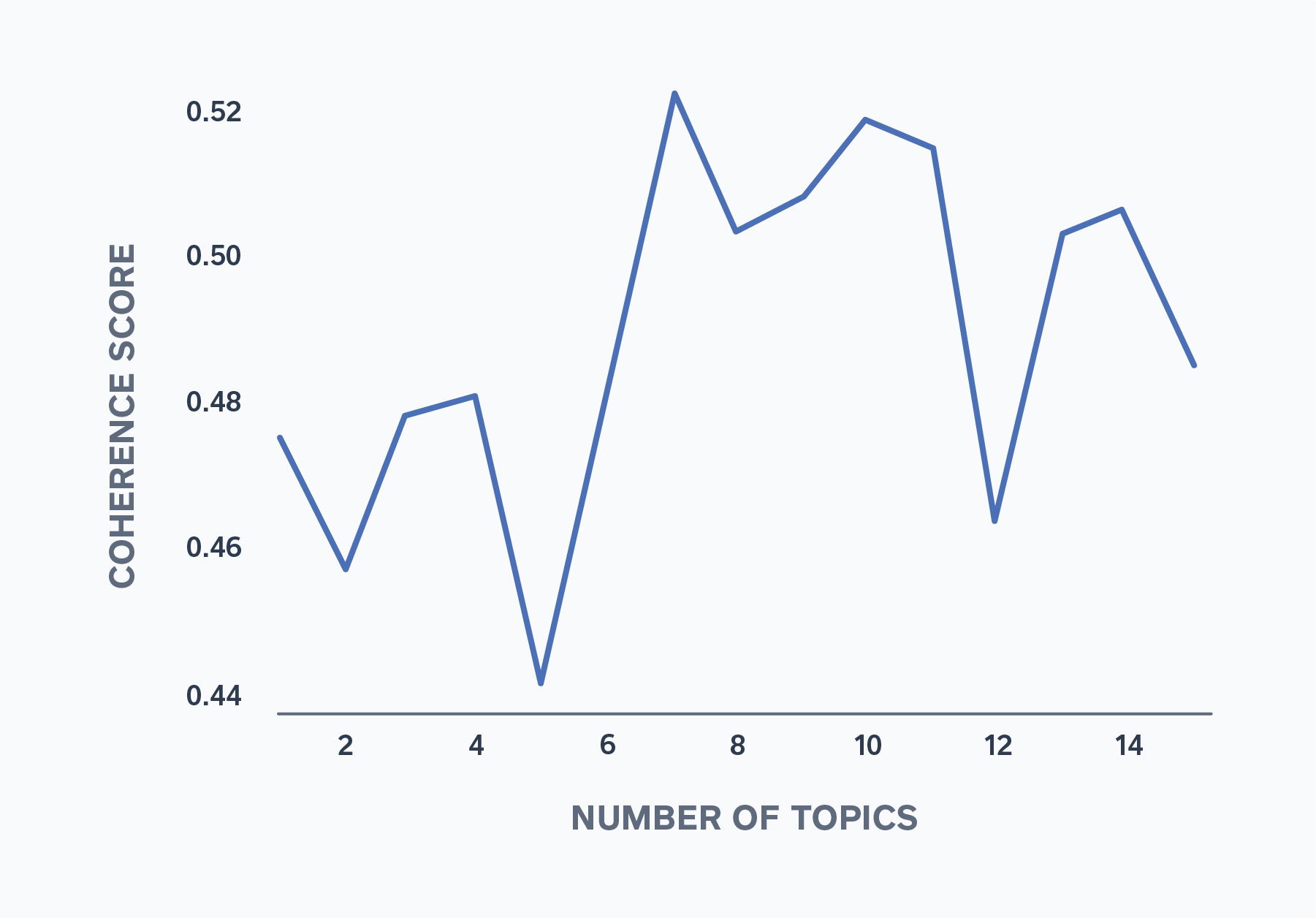 Figure 3: Coherence Score Across Number of Topics
Figure 3: Coherence Score Across Number of Topics
Evaluate & Improve Interpretability
Once you choose the optimal number of topics, the next question to tackle is how to best evaluate and improve the interpretability of those topics. One approach is to visualize the results of your topic model to ensure that they make sense for your use case. You can use the pyLDAvis tool to visualize the fit of your LDA model across topics and their top words. If the top words for each topic are not coherent enough to pass a word intrusion test ( i.e., if you cannot identify a spurious or fake word inserted into a topic), then your topic model can still benefit from interpretability improvements.
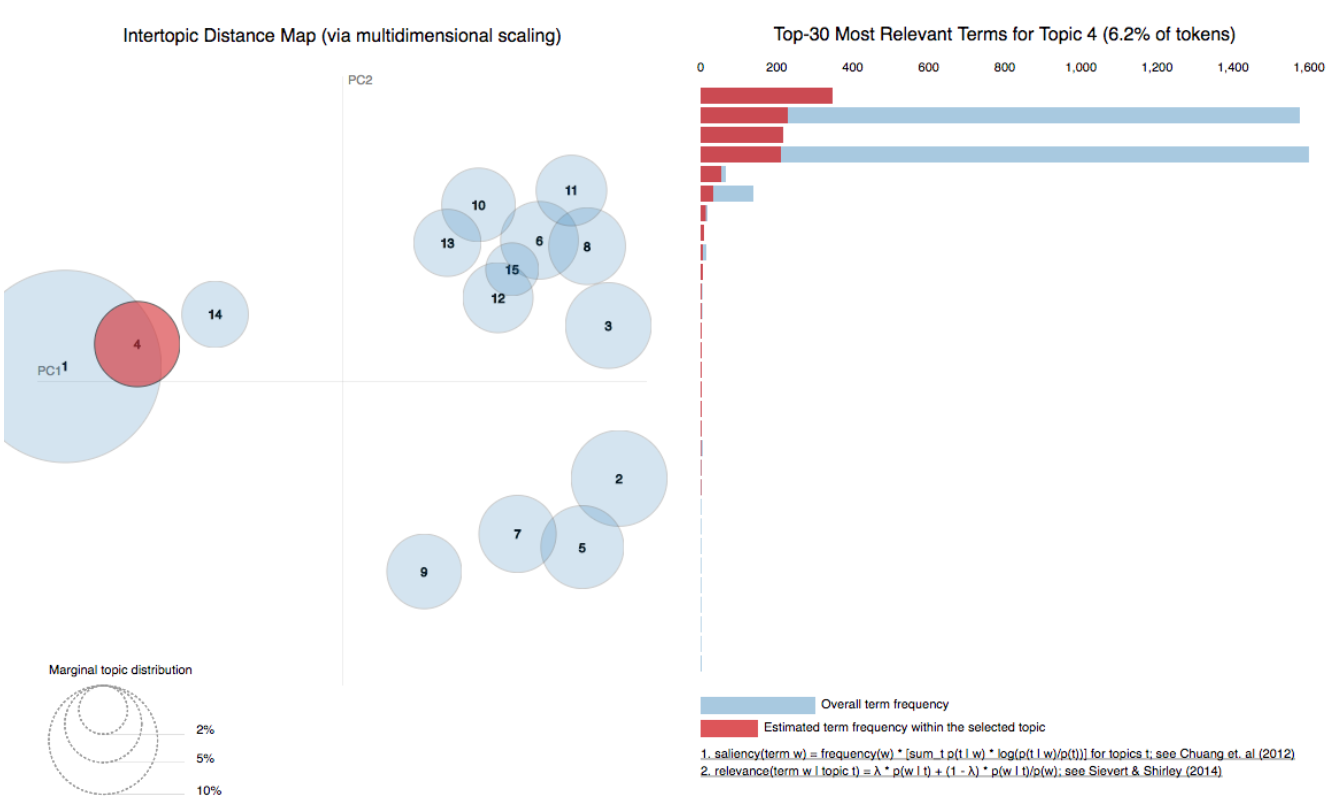 Figure 4: Visualization of topics and relevant terms using pyLDAvis
Figure 4: Visualization of topics and relevant terms using pyLDAvis
Another approach is to look at the topic coherence across different models. For my analysis, I looked at how LDA performed in comparison to other topic models such as Latent Semantic Indexing (LSI), which gives you ranking order of topics using singular value decomposition, and Hierarchical Dirichlet Process (HDP), which uses posterior inference to determine the number of topics for you. Overall LDA performed better than LSI but lower than HDP on topic coherence scores. However, upon further inspection of the 20 topics the HDP model selected, some of the topics, while coherent, were too granular to derive generalizable meaning from for the use case at hand.
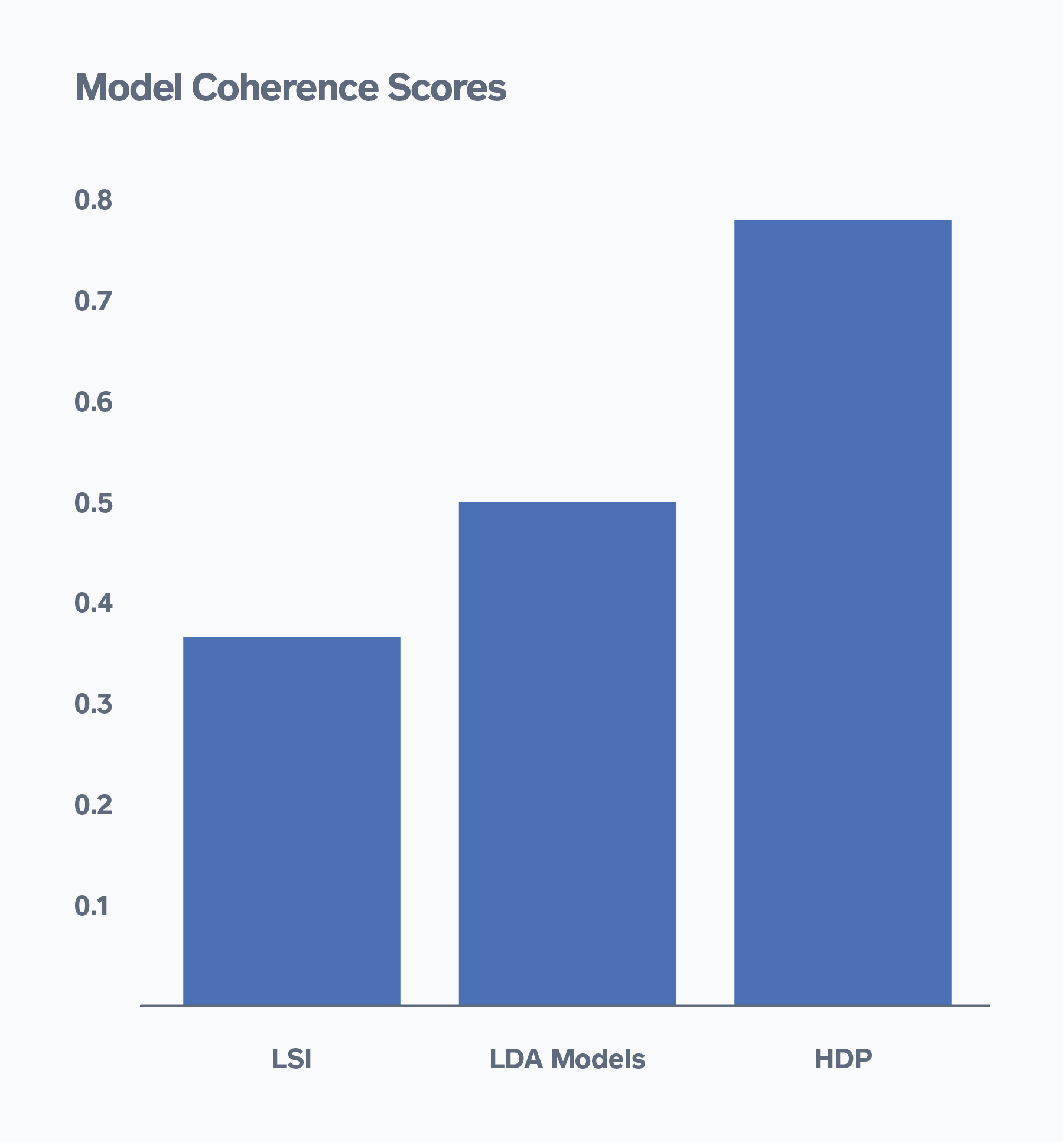 Figure 5: Model Coherence Scores Across Various Topic Models
Figure 5: Model Coherence Scores Across Various Topic Models
Conclusion
Overall, when choosing the number of topics and evaluating the interpretability of your topic model, it is important to look at both qualitative and quantitative factors. It’s also important to balance interpretability with other quantitative metrics, such as accuracy and perplexity, that help you gauge the model’s performance.
This also holds true for how you evaluate the results of the model. In our use case of evaluating our sellers’ text responses, it’s quantitatively useful to have topic categories to understand general trends in how our sellers’ needs are growing and how we as a company can evolve to meet those needs. It’s also qualitatively useful to drill into those topics and understand the nuances of each of our sellers’ individual requests.
No matter how you choose to use topic modeling, keeping these tips in mind will help you to best optimize your model and get results that are valid, useful and applicable for whatever your business needs may be.
Authored By


