
Making AI Interpretable with Generative Adversarial Networks
Authors: Juan Hernandez | @damienrj
Authors: Juan Hernandez | @damienrj
AI has made tremendous advances in technology, business, and science in the past decades, and this progress continues to accelerate today. Many of our experiences in daily life are influenced by AI and machine learning. For example, music is recommended to us by artificially intelligent systems. Our eligibility for financial services is driven by credit-scoring machine learning models. Automobiles are speedily moving toward full autonomy, and many production vehicles are now equipped with AI-based driving assistance. Even medical diagnosis relies on complex statistical algorithms for identifying medical conditions in patients. Criminal courts also use statistical models to estimate the risk of recidivism when they are determining sentences.
Some of the best performing models, however, are very hard to explain. This usually has to do with the complexity of the algorithm. While simpler algorithms are easier to interpret, their performance is lacking compared to more opaque and complex algorithms. Since we, as data scientists, want to use these better-performing, complex models, it is up to us to make these model decisions more interpretable so we can explain model predictions to partners and consumers, diagnose what went wrong in cases where we get false predictions, and keep consumers informed about the rationale behind automated decisions.
At Square, we are proud of our fraud prevention system that relies heavily on machine learning models to detect high risk and potentially fraudulent behavior to help us stop it before it happens. In this post, we share a framework we use for expanding the interpretability of our complex machine learning models.
A little more about reason codes
As stated above, relatively simple models tend to have comprehensible explanations. There are standard practices to inspect model decisions and to generate “reason codes”, i.e. statements that describe the reason for a model’s decision. For example, the value of coefficients of a linear model tell us about the relative importance of each factor in the decision. Among the flaws of this approach is that it assumes a simple model architecture and assumes the ability to isolate the importance of a factor from that model architecture. However, these assumptions are rarely satisfied when attempting to generate reason codes for more complex models, such as a Random Forest, where we can’t isolate the importance of a feature in an individual decision.
Fortunately, there are some approaches that have been designed to generate reasons for individual predictions from more complex models. One such approach includes fitting local simple models to approximate regions of the model decision boundary and then applying standard interpretation techniques to those simple models. However, fitting local models around individual decisions is a relatively expensive approach, especially when an organization is generating millions or more decisions per day.
If reason codes are thought of as “things that would need to change to produce an alternative decision,” then another way to approach reason codes is to find minimum changes to an input that would produce these alternative decisions. For example, if a seller’s account is suspended after a model determines that their activity looks very suspicious, then the question becomes, “What would that same seller have to look like (with regard to model input signals) in order not to have been suspended?” If we could do this, then we could generate model decisions that are clear and could even provide proactive recommendations.
A simplistic approach would be to permute the input values until the model produces an alternative decision. However, randomly permuting signals independently of one another could produce unrealistic, impossible, or even contradictory results. For example, if two signals are correlated in reality, it would make no sense to permute one independently and form reason codes on that basis. Simply put, we want to be able to generate realistic perturbations.
Why does it matter for the perturbations on the input data to be realistic? That is outlined in detail here. Essentially, it is surprisingly easy for an attacker or malicious user to create “adversarial examples” to fool a machine learning model. For example, here is a random perturbation of pixel values on an image of a panda. In the first case, the model correctly identifies the image as that of a panda. In the second case, noise has been added to the pixels. We humans can tell that it is still a picture of a panda, but the model is now convinced that it is a gibbon.
Example of how a seemingly random permutation can produce a false prediction with very high confidence
So how can a model be robust against these kinds of errors? Especially if we want to use a model for reason codes based on feature permutations, how would our model be able to evaluate the “reasonableness” of synthetic nearest neighbors? An existing framework we thought to try was the Generative Adversarial Network (GAN).
Why GANs might be useful
With GANs, we should be able to generate synthetic sellers that appear to be from the real distribution of Square sellers. This framework operates as follows: A generator model creates fake data from random noise. The discriminator is trained to determine whether the example was generated or real. And a feedback cycle allows the generator weights to be updated by the training of the discriminator. In other words, the discriminator becomes more and more robust against fake data because the generator is updated to produce more and more realistic examples. In the end, you have well-trained models to distinguish real data from fake data and to generate realistic new data.
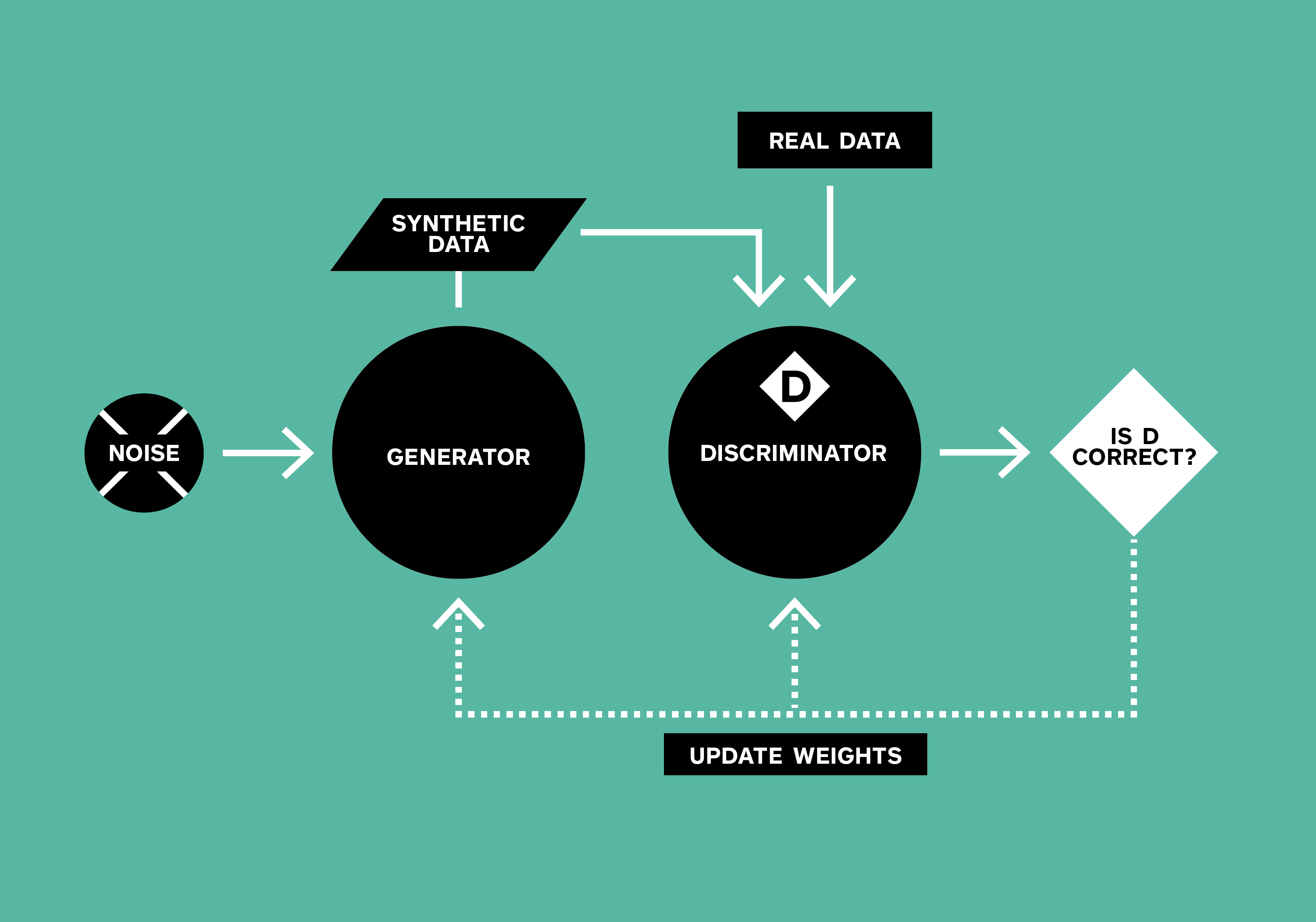 Generative Adversarial Network Framework
Generative Adversarial Network Framework
GAN Framework. The Generator tries to create data from random noise. The Discriminator tries to distinguish generated from real data. The weights of both networks are updated through the process, so that the generator gets better at deceiving the discriminator and the discriminator gets better at identifying fake data.
When training our model, we found that an Actor-Critic Framework worked best to generate synthetic data from our training set. At first, we trained using a binary Generator-Discriminator approach but found that our GAN suffered from “mode collapse”, a phenomenon in which the generator learns to generate data within a small range of possible values — specifically, in a range of values where the discriminator does poorly to accurately classify the data as real or synthetic. The Actor-Critic framework solved this problem by evaluating the Wassertstein distance between the real and synthetic data rather than evaluating binary cross-entropy.
Methods
Data Collection / Population
We applied our framework to a modeling population related to fraud risk. Specifically, we wanted to see if we could use GANs to provide reasons for model decisions to review accounts that are flagged as potentially fraudulent.
Modeling/Reason Code Framework
The framework:
-
Develop a generator function to create “synthetic” sellers from random noise.
-
Train a discriminator to distinguish between synthetic sellers and real sellers.
-
Iteratively improve the generator using the discriminative learning of the discriminator, while also improving the discriminator, which learns to classify increasingly difficult observations. Eventually, this yields a well-trained generator that is able to generate synthetic sellers that are “realistic”.
-
Use trained generator to create a large store of synthetic sellers. To generate reason codes, compare against synthetic sellers: For a threshold, t, and a seller m, if m’s model score >= t, then which synthetic seller, s, whose model score < t is the nearest neighbor to m? The difference between s and m is the set of reason codes for the model decision.
One of the advantages of this method is the relative ease of implementation. Since the GAN model training and generating of the synthetic sellers all takes place offline, the synthetic sellers can be stored in a database that is accessible from the production environment.
Evaluating Synthetic sellers
Different supervised models typically have clear evaluation metrics. For a GAN, it’s a bit tricker to evaluate based on mere classifier performance, since we are training two coupled models with competing goals. One way we chose to evaluate the model was to compare the correlation matrix of the synthetic data to the correlation matrix of the real data. For reference, here’s the correlation matrix of the real data.
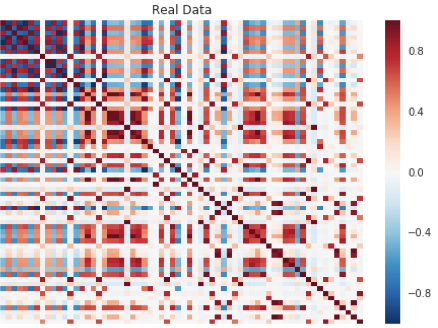 Correlation Matrix of Real Data
Correlation Matrix of Real Data
Since the generator starts by generating essentially random data at first, that randomness is exhibited by the correlation matrix. Here’s the correlation of some generated data before training has taken place.
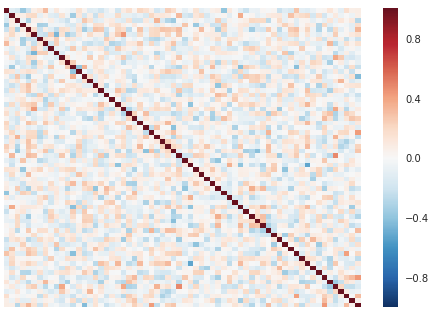 Correlation matrix at 0 epochs
Correlation matrix at 0 epochs
As the model trains, the correlation matrix starts to take a non-random form.
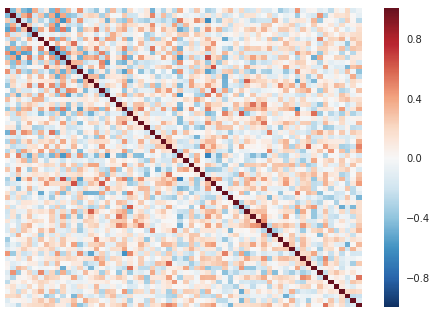 Correlation matrix at 400 epochs
Correlation matrix at 400 epochs
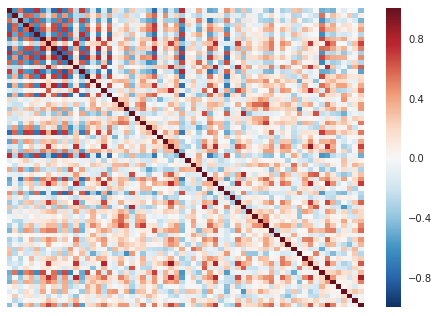 Correlation matrix at 500 epochs
Correlation matrix at 500 epochs
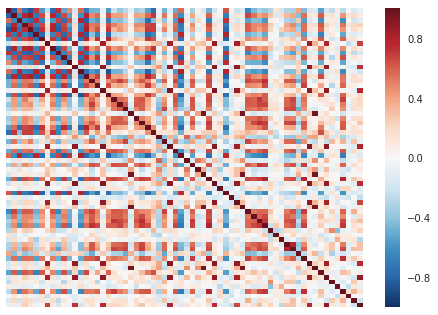 Correlation matrix at 800 epochs
Correlation matrix at 800 epochs
At one point, the model overshoots and starts producing too-strongly correlated output. If we compare this chart to the correlation matrix of the original data, we see that the generated data has more and stronger correlations than the real data does.
 Correlation matrix at 1000 epochs
Correlation matrix at 1000 epochs
And eventually, we get a correlation matrix very similar to that of the real data, which the reader can see by, again, comparing to the original correlation matrix of the real data.
 Correlation matrix at 2000 epochs
Correlation matrix at 2000 epochs
After about 2000 epochs, we found that our model performance stabilized, meaning that the correlation matrix of the synthetic data didn’t change much from one epoch to the next.
When comparing univariate distributions of the real and generated data side by side, we see that the output values of the generator consistently fall within reasonable ranges. This is shown by plotting the distribution (using kernel density estimation) for the real and synthetic sellers side by side. The reader can see that the synthetic data doesn’t map precisely to the real data, but it does well. The synthetic data unsurprisingly follows a smoother, more Gaussian-looking distribution but with more outliers. One interesting thing to note was that we reduced the magnitude of mode collapse, a phenomenon that results in generating synthetic data within narrow concentrated bands. This was due to our use of the Actor-Critic framework.
A subset of signal histograms comparing generated seller distribution to real sellers.
Finding Neighbors and Computing Reason Codes
Once the model is trained, we use it to generate an arbitrarily large database of synthetic sellers. Given these synthetic sellers, we can now compare a “bad” real seller (one that was suspended by the model, for example) to “good” synthetic sellers (ones that the model would have cleared). In order to make the comparison, we specifically compare them to the K most similar “good” synthetic sellers. The reason for using K-nearest neighbors is to reduce possible noise in the comparison by averaging the value of those *K *neighbors and comparing the real seller to the average of those K values.
* Comparative Framework. A real seller whom the model has classified as “bad” is compared to the population of synthetic sellers classified by the model as “good.” Among those synthetic sellers, the K most similar to the input seller are returned as its neighbors and used to generate reasons based on their differences from the input seller.*
There are many approaches for computing pairwise similarity. We chose to use cosine similarity of normalized signals, but other metrics could be substituted depending on the type of data.
Generating Reason Codes
Once a seller’s K neighbors are found, computing reason codes is straightforward: We determine which signals are similar to and which signals differ from the seller’s neighbors. The ways in which the seller most differs from its neighbors constitute the most likely reasons for the decision.
We found this to be the case when reviewing sellers that were suspected of fraudulent activity by the model. For example, for one of our high-risk sellers, the top contributing signals were related to their transaction behavior and association with other known bad actors. For other sellers, we were able to generate similarly intuitive reason codes. It is important to note that the reason codes created by this method did not just tell us how a seller differed from the whole population, but these reason codes were able to tell us specifically *what stands out *about a seller, i.e. what makes them look different from otherwise similar sellers.
Conclusion
In our example, we applied this technique to a single domain, i.e. fraud, to explain individual model decisions and predictions in terms of input features. In this example, we were able to generate codes that could be used to explain to a seller what exactly it is about them that looks suspicious. This could be extremely useful in applications of automation that result in adverse decisions for a customer in other domains.
Square’s purpose is economic empowerment. We think that there is an opportunity for AI to help create a fair and sustainable environment for seller and customers to connect. Taking this big step toward interpretability of machine learning models can help achieve greater fairness and transparency.



