
Remodeling Cash App Payments
Before we could partition our database we needed to prepare our data model. Here’s how we turned a simple normalized data model into one…
Before we could partition our database we needed to prepare our data model. Here’s how we turned a simple normalized data model into one that could be partitioned for scale.
Normalized Data is Beautiful
The Cash App started as a simple service for sending money. Our MySQL database tracked customers, their linked debit cards, and the payments between them.
Customers
| id | display name | identity verified |
|---|---|---|
| 101 | Lex Murphy | true |
| 102 | Ellie Sattler | true |
| 103 | Ray Arnold | false |
Cards
| id | customer id | kind | expiration | last four | vault token |
|---|---|---|---|---|---|
| 204 | 101 | VISA | 11/17 | 3456 | ed6cf9c8706a7ac7 |
| 205 | 102 | MC | 02/18 | 4849 | 9352d00cf043b139 |
| 206 | 102 | VISA | 10/19 | 7471 | b191a4884d216ea4 |
| 207 | 101 | VISA | 03/20 | 3456 | 281267764156054a |
Payments
| id | from id | from card id | to id | to card id | amount | state |
|---|---|---|---|---|---|---|
| 308 | 101 | 207 | 102 | 205 | $11.00 | COMPLETE |
| 309 | 102 | 205 | 103 | NULL | $20.00 | VALIDATING |
| 310 | 101 | 207 | 103 | NULL | $23.00 | VALIDATING |
Using a normalized persistence model was great! It made it easy for us to iterate on our service. We built many potential features and launched the best ones.
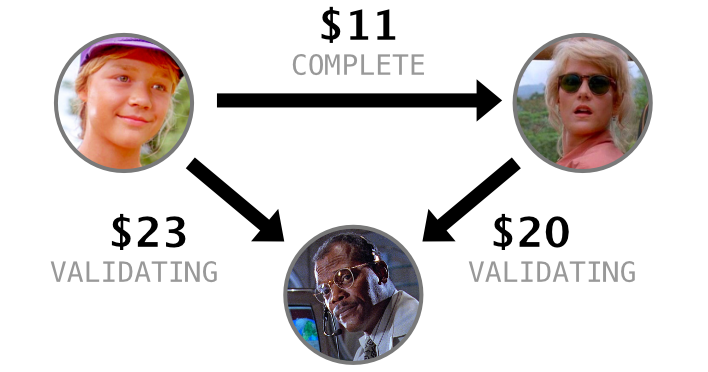 3 customers + 3 payments
3 customers + 3 payments
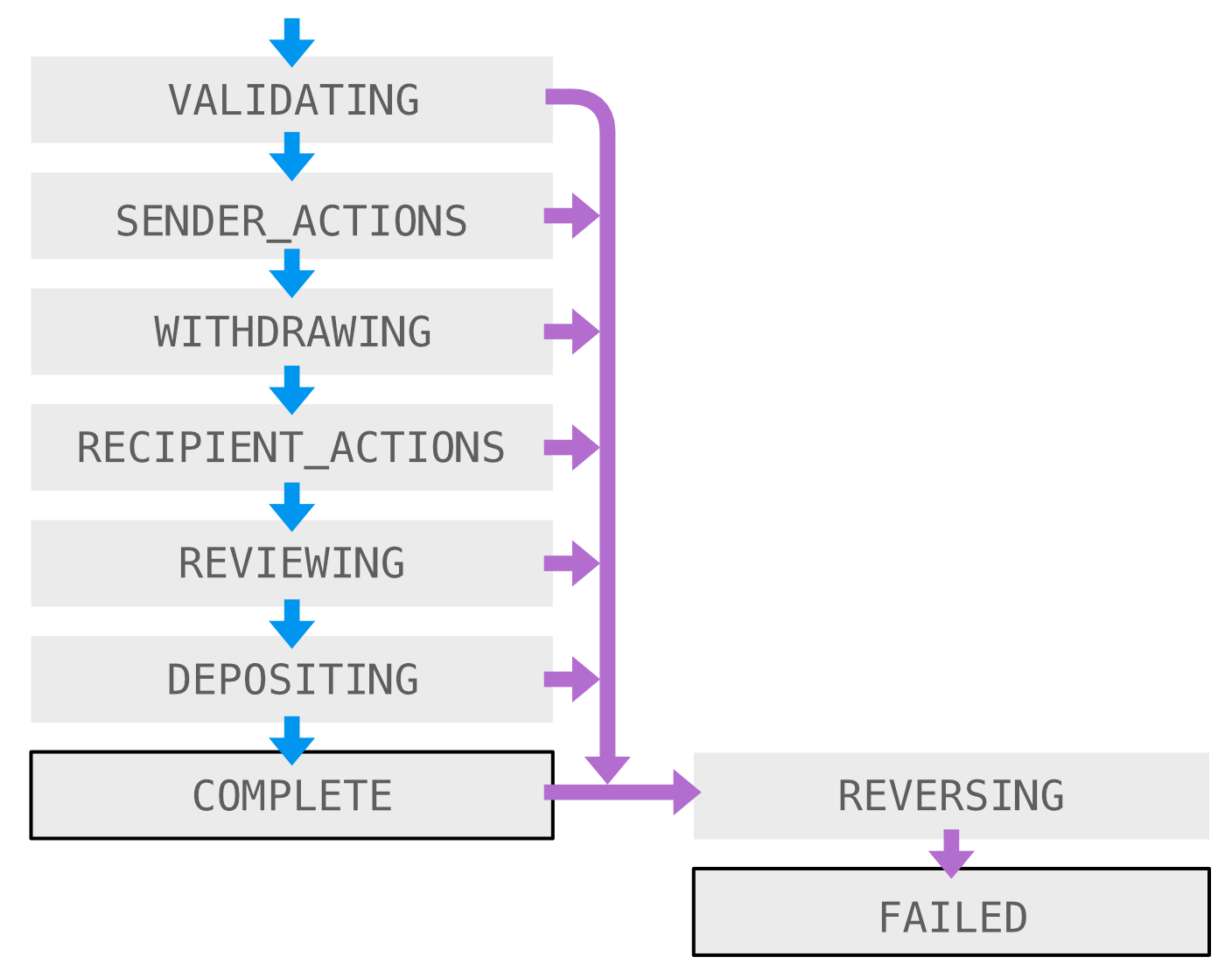
We use a robust state machine to manage the payment lifecycle. The state column changes as the payment advances through this state machine.
The schema is ready for both programmed and ad-hoc queries. For example, if a card is reported lost we can find the payments sent from it even if it was linked by multiple customers.
SELECT
p.id,
p.amount
FROM
payments p,
cards c
WHERE
p.sender_card_id = c.id AND
c.vault_token = 'b191a4884d216ea4';
The schema let us operate atomically across our customers and their payments. If Ellie linked a new debit card we could advance all of her payments in the state machine.
Developing for the Cash database was great! But we anticipated trouble operating it at scale.
Partitioned Data is Scalable
To scale our system across multiple MySQL nodes we had to first partition it. But how? Our data model is a graph with customer nodes and payment edges. Our code ran atomic transactions across customers and their payments. It also expected to do SQL joins across these tables.
Our insight was to borrow from messaging systems. They solve the problem by duplicating each message: one copy for the sender and one for the recipient. We could do likewise as long as we could find a solution for shared payment state.
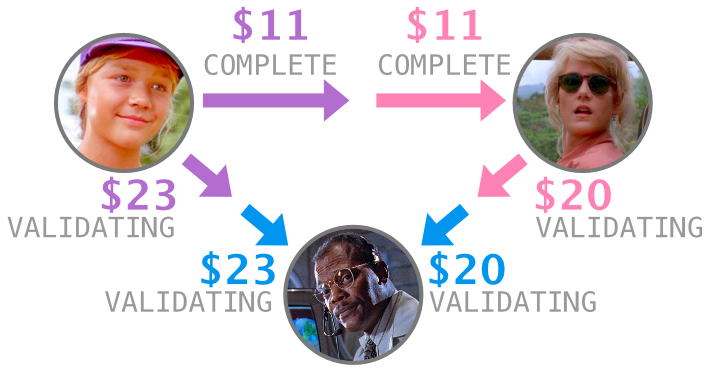 3 customers + 6 movements
3 customers + 6 movements
Each payment in the Cash App moves money twice: withdrawing from the sender to Square, and depositing from Square to the recipient. We named half of a payment a “movement” and began our big schema remodel.
Payments
| id | from id | from card id | to id | to card id | amount | state |
|---|---|---|---|---|---|---|
| 308 | 101 | 207 | 102 | 205 | $11.00 | COMPLETE |
| 309 | 102 | 205 | 103 | NULL | $20.00 | VALIDATING |
| 310 | 101 | 207 | 103 | NULL | $23.00 | VALIDATING |
Movements
| id | role. | payment id | customer id | card id | amount | state |
|---|---|---|---|---|---|---|
| 411 | SENDER | 308 | 101 | 207 | $11.00 | COMPLETE |
| 412 | RECIPIENT | 308 | 102 | 205 | $11.00 | COMPLETE |
| 413 | SENDER | 309 | 102 | 205 | $20.00 | VALIDATING |
| 414 | RECIPIENT | 309 | 103 | NULL | $20.00 | VALIDATING |
| 415 | SENDER | 310 | 101 | 207 | $23.00 | VALIDATING |
| 416 | RECIPIENT | 310 | 103 | NULL | $23.00 | VALIDATING |
For every row in the payments table we created two rows in the movements table: one for the sender and another for the recipient. There was a lot of code that would be impacted by this migration!
The Cash App uses Hibernate for most of our interaction with MySQL. We use a Db prefix in our entity classes, like DbCustomer, DbCard, and DbPayment. In addition to creating a DbMovement for our new table, we also needed an abstraction that would bridge the two models. I called it DaPayment and entertained my teammates with goofy questions like “where da payments at?” when they asked about the name.
Calling DaPayment.setState() would update either the DbPayment, two DbMovements, or everything, depending on our migration phase. The migration had four phases.

-
PAYMENTS_ONLY: the payments table is the only table we use. -
READ_PAYMENTS: payments is the source of truth; echo all writes to movements also. -
READ_MOVEMENTS: movements is the source of truth; echo all writes to payments also. -
MOVEMENTS_ONLY: the movements table is the only table we use.
Abstracting over the entity class was good but not enough. We also needed abstractions on our queries and the projections they yielded. Every line of code that accessed payments needed indirection to toggle between payments or movements. Since our project’s primary concern is payments this was a lot of lines of code!
We wrote backfill tools to create movements rows for the payments that didn’t have them (run during phase 2) and another to delete payment rows that were obsolete (run during phase 4).
Having a comprehensive test suite was essential to making the migration safe. Early on in the migration we built confidence when a few tests ran to completion in the new world. We annotated these tests @WorksOnMovements and configured our build infrastructure to run these tests twice, once under phase 1 and again under phase 4. We made progress by finding unannotated tests and filling out the movements codepaths until they passed. Later we replaced the @WorksOnMovements allowlist with a @DoesNotWorkOnMovements denylist and started to count down to a fully-ready system. Once all of the tests worked on movements we were ready to migrate.
Over the spring of 2017 we proceeded through the phased migration in production. Entering phase 2 was stressful because the total load on the database was exacerbated by extra writes. What if our database couldn’t handle the extra load? Would we be stuck? I bit my fingernails and pushed through.
Here’s queries to movements spiking as we entered phase 3:
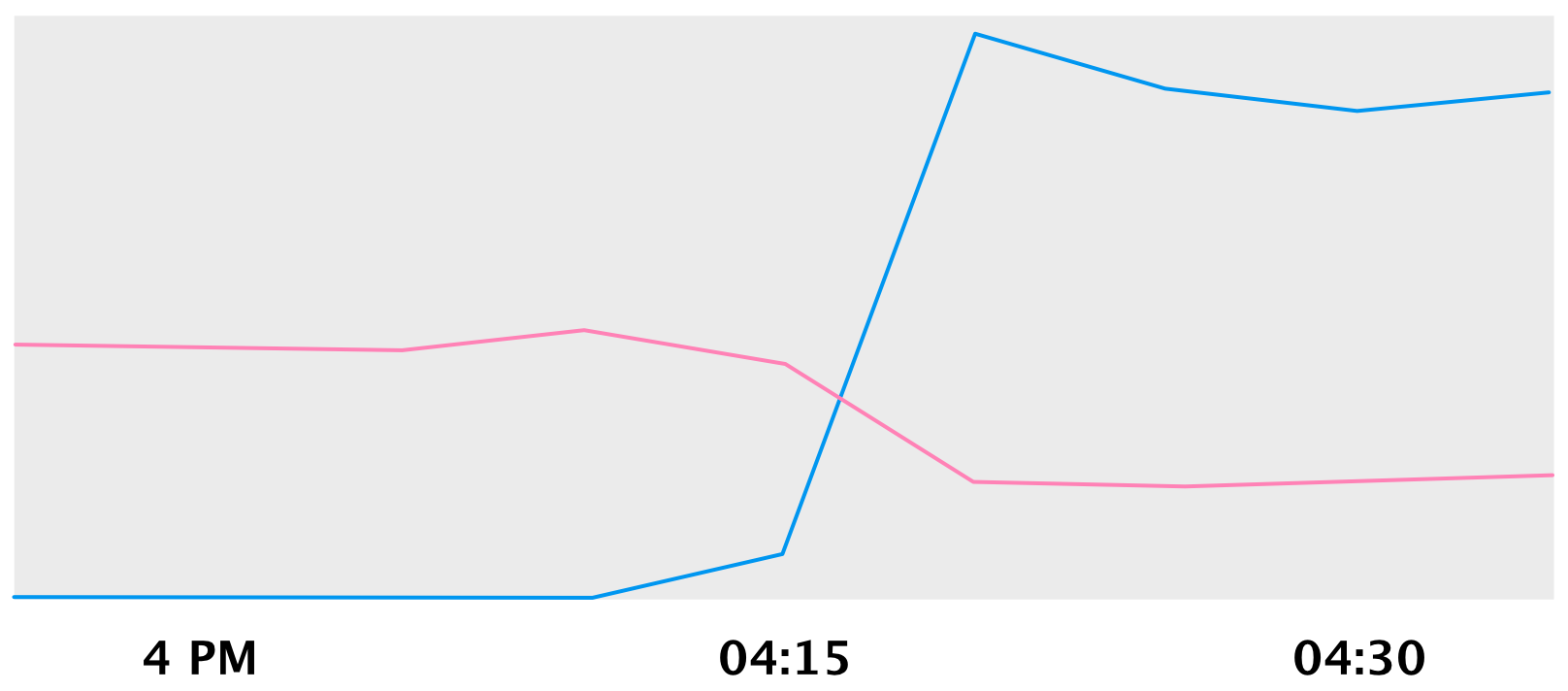 Movements (blue), Payments (pink) QPS
Movements (blue), Payments (pink) QPS
And here’s payments writes dropping off as we entered phase 4.
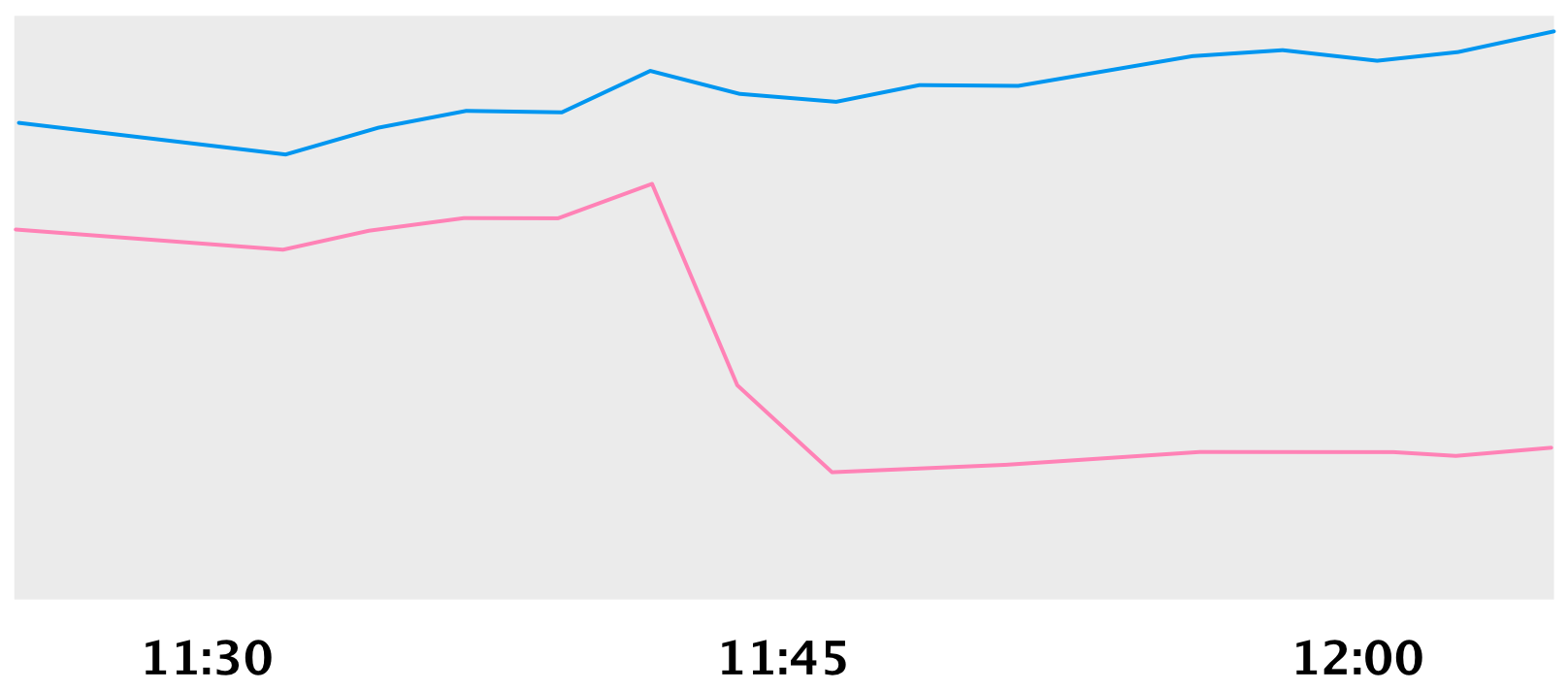 Movements (blue), Payments (pink) QPS
Movements (blue), Payments (pink) QPS
Whew, it worked. I slept soundly that night!
Distributed Systems Are Asynchronous
Though we’d replaced our partition-resistant payments table with the partition-friendly movements table we still weren’t ready to split. We still needed to keep shared mutable fields like the payment’s state in sync.
We built a mechanism called “Twinlock” to keep pairs of movements consistent and in sync. At any time one movement holds the lock and can change mutable fields that the two movements share. The twin is updated asynchronously, and is eventually consistent. In practice “eventually” is under a second.
TwinLock uses 3 columns in each of the two movements:
-
lock_state: eitherDEFINITELY_MINEorPROBABLY_YOURS. -
lock_version: only the lock holder increments this. If a movement has a lowerlock_versionthan its twin then it may have been given the lock. -
twin_stale_at: non-null if the twin needs to sync its fields.
MySQL lets us atomically update the movement with its twinlock columns in a single transaction. But as partitioning puts different movements in different databases we can’t update multiple movements in the same transaction.
Edits that change two movements require three sequential transactions:
-
Update one movement, making sure we hold the lock first. Alongside the data changes we also increment the
lock_versionand settwin_stale_atto the current time. This happens in the first transaction. -
Sync the changes over to the twin movement. This includes the
lock_versionfield. -
Finally, clear
twin_stale_aton the original movement.
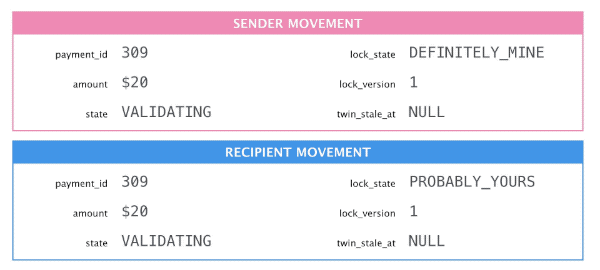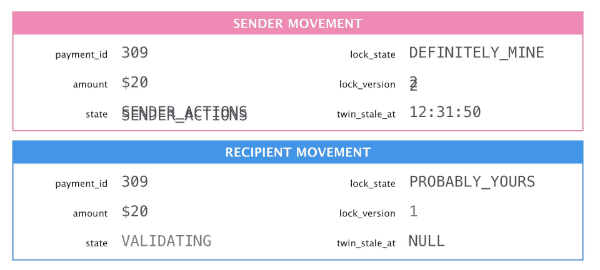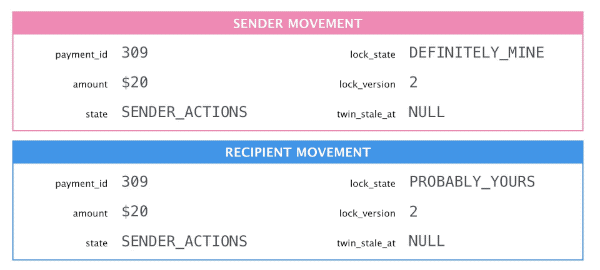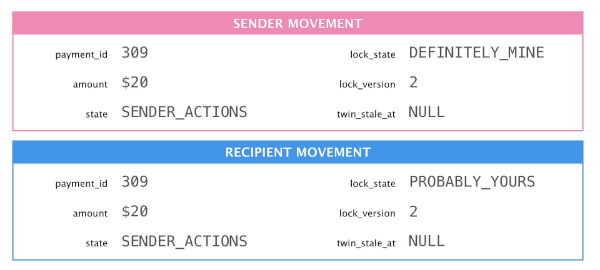 Change the sender movement, sync the change, and acknowledge sync success.
Change the sender movement, sync the change, and acknowledge sync success.
The most interesting feature of Twinlock is that it’s asymmetric: you can be certain that you hold the lock but you can’t be certain that you don’t! If both movements’ lock state is PROBABLY_YOURS, then the one with the lower lock_version is the actual lock holder. It should sync, take the higher lock version, and change its lock state to DEFINITELY_MINE.
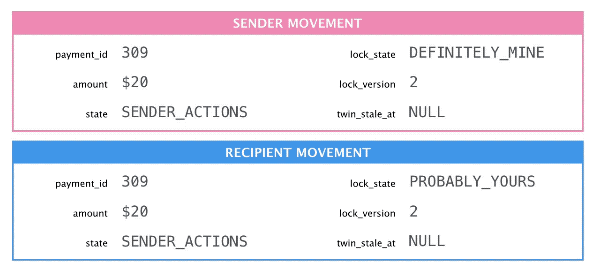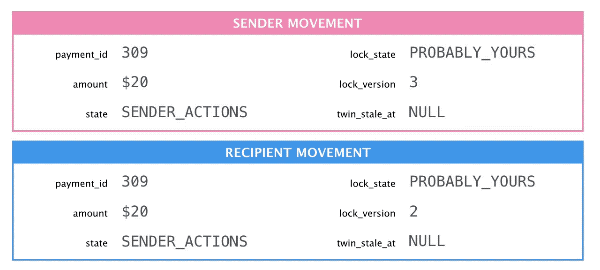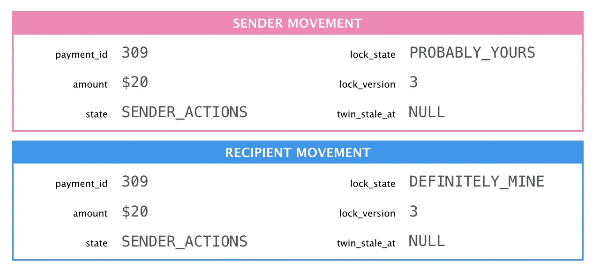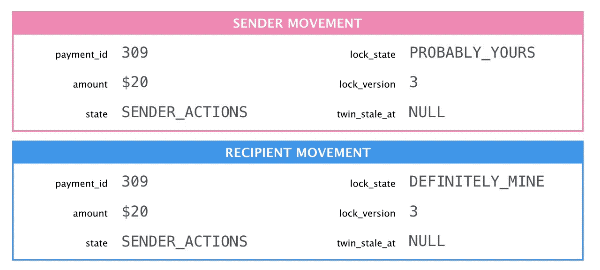 The sender released the lock so the recipient must acquire it.
The sender released the lock so the recipient must acquire it.
When the lock holder releases the lock it changes its own state to PROBABLY_YOURS and increments the lock_version so that there’s a unique lowest version. This design allows us to release the lock in one transaction and acquire it in a separate one.
If two operations attempt conflicting edits we detect the race and force the race’s loser to rollback & retry. We’ve built our database access APIs to make sure that these recoveries are always automatic and safe. They lean on Hibernate’s fantastic @Version feature, which detects concurrent edits without contention or ceremony.
Ready for Vitess
The movements table was ready to be partitioned and the Twinlock was keeping pairs of movements consistent and up-to-date. We were ready for Vitess to split our database into two, then four, eight, sixteen, and many more!
This post is part of Square’s Vitess series.


