
Abstracting Sharding with Vitess and Distributed Deadlocks
One of the main reasons Vitess was such a success for Cash App is that it abstracts database sharding away from the application code. This…
One of the main reasons Vitess was such a success for Cash App is that it abstracts database sharding away from the application code. This allowed us to shard our database without rewriting thousands of transactions in our application.
When the application issues write operations on two entity groups that are on different shards, Vitess will automatically open transactions on all shards that are necessary to complete the operation.
Here’s an example. Suppose Alice lives on shard 1 and Bob lives on shard 2:
| Application SQL | Vitess Shard 1 | Vitess Shard 2 |
|---|---|---|
begin; |
||
update customersset last_payment = now()where name = 'Alice'; |
begin;update customersset last_payment = now()where name = 'Alice'; |
|
update customersset last_payment = now()where name = 'Bob'; |
begin;update customersset last_payment = now()where name = 'Bob'; |
|
commit; |
commit; |
commit; |
This feature has two notable drawbacks:
-
Atomicity: the second transaction isn’t guaranteed to commit if the first one does. The default is a best-effort approach. We still had to rewrite any transaction code that deals with money movement, as we could not afford any loss in consistency. See Jesse’s post on movements for how we solved that problem.
-
All shards commit together, so any locks taken on one shard will be held until all the other shards also commit.
We decided the tradeoff was worth it as we were reaching our capacity limit and wanted to shard as soon as possible.
Shortly after our first shard split, we saw a couple of brief outages in our service. All requests would hang for a minute, then fail, but everything would go back to normal afterwards. Our metrics showed us three facts: the Vitess transaction pool was full, QPS fell to zero, and MySQL thread count spiked. From our logs we also saw that Vitess was killing transactions after a minute. Once the pool was full no requests could be serviced for the whole minute, causing an outage.
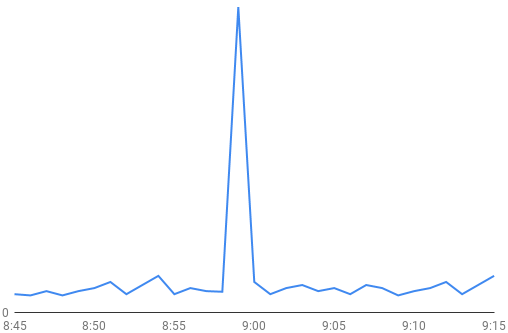 Example MySQL thread count spike during an outage.
Example MySQL thread count spike during an outage.
There were more pressing capacity concerns, so everyone was focused on splitting into more shards, and we hoped having more shards would alleviate the problem. By the time we got to 16 shards, the outages were much more frequent, and this became my top priority.
When queries hang the first instinct is to look at locking. MySQL provides several useful tables in itsinformation_schema, notably innodb_lock_waits and innodb_trx. Since the issue was intermittent, we started investigating by setting up a pt-stalk process to watch our databases and trigger when the MySQL thread count exceeded a certain threshold.
We used this query to see what transactions were running and what they were blocked on:
SELECT
TIMESTAMPDIFF(SECOND, rt.trx_wait_started, NOW()) AS wait_time,
rt.trx_query AS waiting_query,
w.blocking_trx_id,
bt.trx_query AS blocking_query
FROM information_schema.innodb_lock_waits w
JOIN information_schema.innodb_trx rt
ON w.requesting_trx_id=rt.trx_id
JOIN information_schema.innodb_trx bt
ON w.blocking_trx_id=bt.trx_id;
And the result was hundreds of insert and update queries like the following:
wait_time: 11
waiting_query: update notifications set ...
blocking_trx_id: 253762323865
blocking_query: NULL
The innodb_lock_waits table shows the blocking transaction, but since the blocking transaction was idle we could never see what query it was running and unfortunately MySQL doesn’t show us the previously executed statement for a transaction.
Since Vitess holds transactions open until all shards are ready to commit, I had a hunch that the idle transactions were ones being held open but waiting on work to complete on another shard. This could cause a distributed deadlock between two shards if the shards are updated in opposing orders. Consider this scenario:
| App level transaction A | App level transaction B |
|---|---|
begin;insert to shard1.notifications |
|
begin;insert to shard2.notifications |
|
insert to shard2.notifications(this hangs, waiting for transaction B to commit) |
|
insert to shard1.notifications(this hangs, waiting for transaction A to commit) |
Due to locks held by the insert queries, A waits for B and B waits for A, which is a deadlock. For normal deadlocks, MySQL provides deadlock prevention by detecting a cycle in the locks held in two transactions and aborting one of the transactions. In the case of distributed deadlocks, however, each database is unaware of locks held on other shards, so it can’t know there is a deadlock, and the queries wait until they time out.
Since inserts lock the end of the table, no other transactions could insert into these tables on both shards and all requests would quickly snowball, filling up the transaction pool and locking up the whole service.
The fix was to split app level transactions into one transaction per shard. The above example would now look like:
When we fixed the most frequent app level transactions to avoid cross shard writes, we immediately saw a big improvement in MySQL lock wait time and the outages went away.
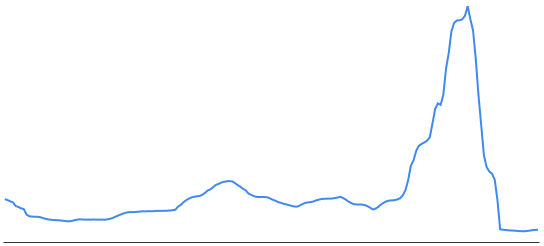 MySQL lock waits increasing with shard count over a few months, then dropping off after the fix.
MySQL lock waits increasing with shard count over a few months, then dropping off after the fix.
We were blinded by the abstraction that Vitess provides and missed that there is no deadlock detection for locks held between shards. This highlights the danger of abstracting sharding from the application and not thinking carefully about how locking will work under the hood.
It now makes sense why having more shards exacerbated the issue: the probability of having to use multiple shards increases and it takes more time to execute an update on a big set of customers, holding the locks for more time.
We still think the tradeoff was worth it: the deadlocks were a small price to pay to shard months earlier and avoid much bigger outages.
This post is part of Square’s Vitess series.
Authored By


