
Reliable Webhooks Using Serverless Architecture
How we made our webhooks more reliable using SQS and Lambda
For those who are already Square Developers, you probably already heard our announcement of webhooks being more reliable. If you haven’t: in October, we released more robust and reliable webhooks to better serve events to developer’s applications. Today, we’re sharing how we achieved that.
In most cases, webhook events will arrive within 30 seconds of the associated event and failed deliveries will be retried for up to 72 hours. If you’re interested in how our Webhooks API works, make sure to check out our documentation.
We were able to improve our webhooks by moving a portion of our webhooks infrastructure to Amazon Web Services (AWS) and leveraging their SQS and Lambda services. Let’s take a brief look into our architecture and how we made the transition.
Before we start, here’s a list of terms that will be useful to understanding this post:
-
Webhook — (also known as web callbacks or push APIs) are HTTP calls or snippets of code that are triggered by specific events. With a typical API, you have to make calls at regular time intervals to detect changes to your data. Webhooks replace regular API calls with instant, real-time notifications.
-
Serverless Architecture — A design pattern based on using configurable third party backend services instead of in-house servers. A good summary can be found here.
-
Amazon Web Services (AWS) — A cloud computing platform from Amazon that provides a myriad of generic services on a per-use basis.
-
Lambda — AWS service that runs code in response to events and automatically manages the computing resources required by that code.
-
SQS — AWS service that provides a distributed message queue.
A Brief History on our Webhooks
From a high level, our webhooks architecture follows the publish-subscribe pattern: there is a set of producers, a message bus, and a set of consumers. A typical webhook event would be pushed by a producer into the publish feed, processed by the message bus by looking at the webhook subscription data, and forwarded to the appropriate consumer feed. The consumer feed will proceed to issue a POST notification to the subscribed endpoint and handle any errors that may occur.
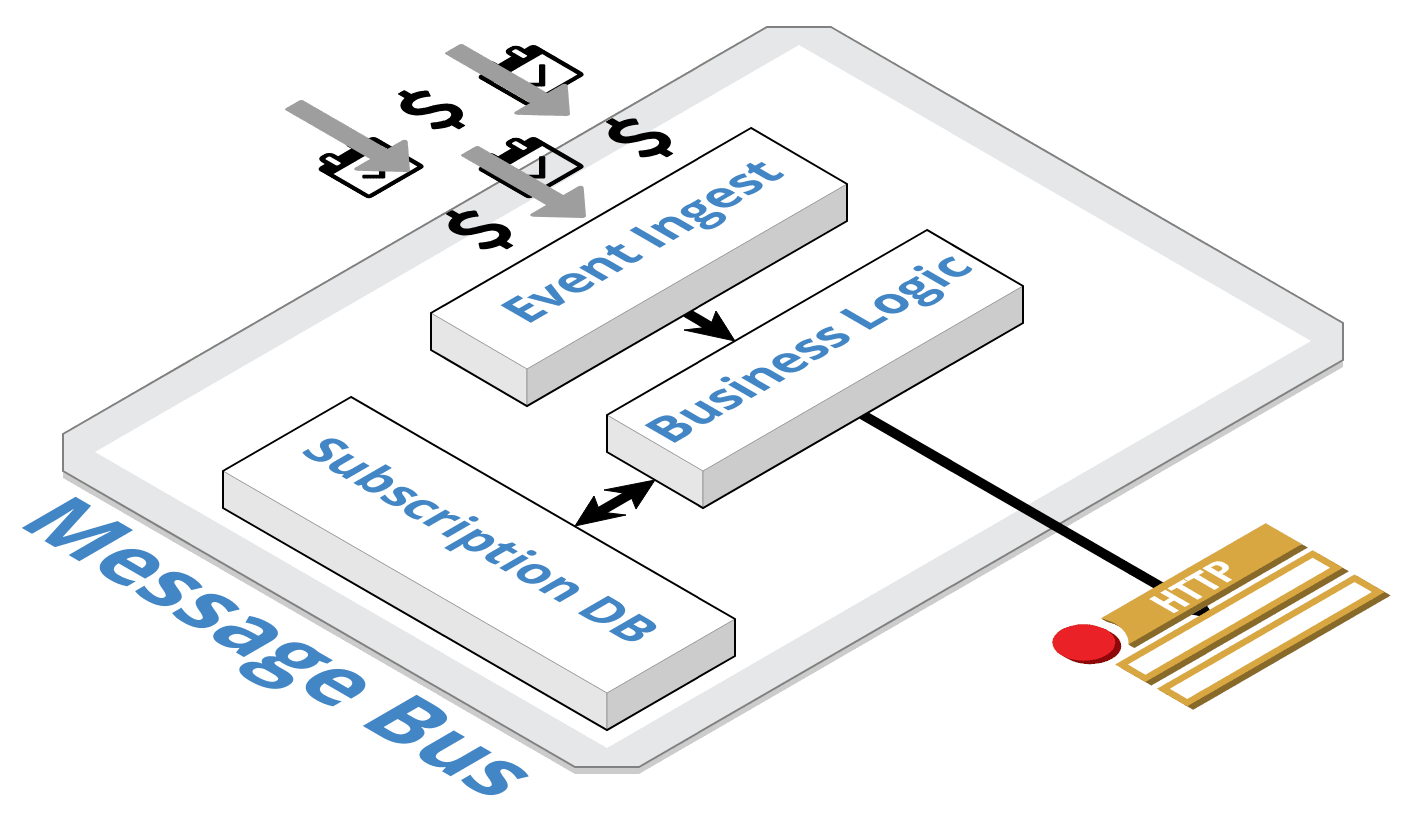
Thousands of subscribers are served millions of webhooks per day with this model. The previous system, implemented in-house at Square, was stretched beyond what it was originally designed to handle. This became increasingly apparent as obscure bugs surfaced and code complexity continued to increase. Unsurprisingly, it is not trivial to build a custom distributed messaging system. The result was that developers who were subscribed to webhooks had to suffer with less-than-ideal reliability and a limited feature set.
With this in mind, we went back to the drawing board and identified our goals as:
-
Accelerate the pace we deliver features to our customers.
-
Lower system complexity and operational burden.
-
Improve reliability by using well documented, commonly used, and proven infrastructure.
-
Support thorough monitoring and analytics.
To achieve these goals, the team concluded that the producer portion could stay as-is because it is built on top of technology that the rest of Square uses, but the consumer portion that was custom made for webhooks would benefit from being rebuilt. Given the goals we had, reimplementing it in the cloud made the most sense; development velocity would be quicker and the end product would be more reliable than another internal iteration.
Moving to the cloud
After prototyping on major cloud services, we decided to go with AWS because it offered the simplest and most elegant solution thanks to a new feature that allows us to configure Lambdas to pull from SQS automatically. Another benefit was our existing familiarity with AWS and its support of Go, one of our preferred programming languages.
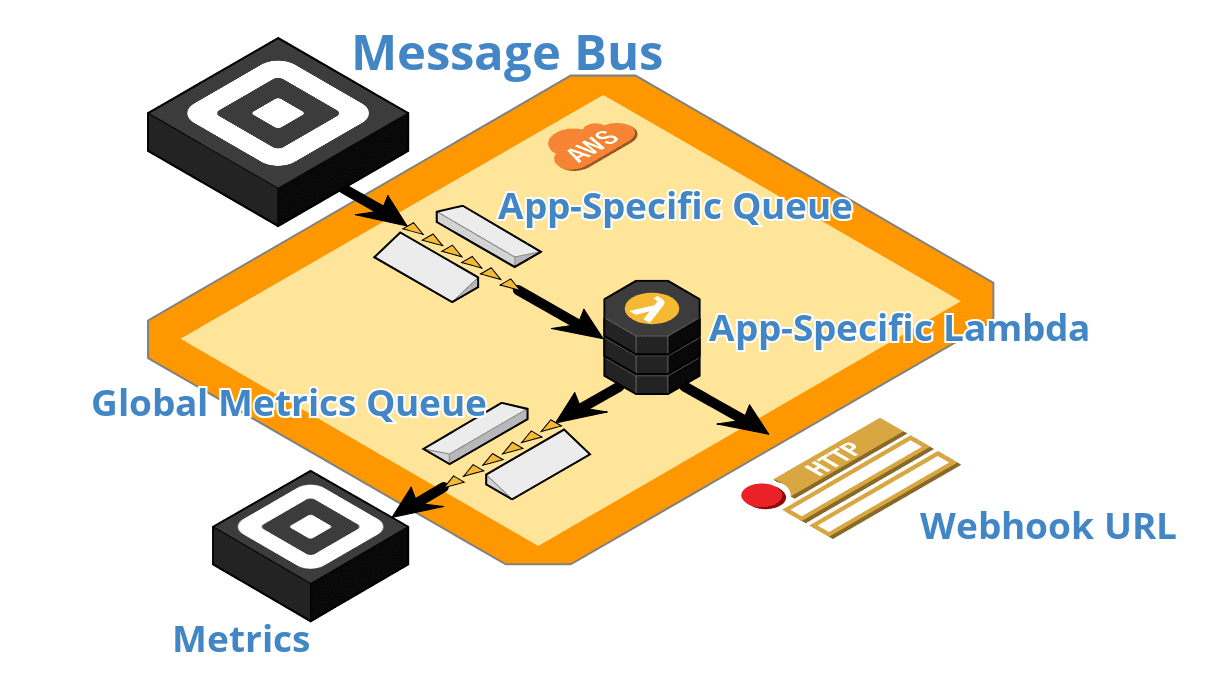
The architecture diagram shows our final design: for each application, we provision an SQS queue that is polled by Lambdas, backed by a single shared dead letter queue and metrics queue. This provides us with the flexibility of management per application, such as updating and deleting messages in-flight, and rate limiting the throughput by setting the maximum number of concurrent Lambda executions. The dead letter queue (DLQ) is an AWS feature for handling messages that are unprocessable for any reason that will be parked in this separate queue for diagnoses. The shared metrics queue holds informational metrics such as status codes, timestamps, and delivery results.
Traffic flow is simple and straightforward in this new system. Once the message bus has computed the event and the subscriber, it forwards the information to AWS where it is enqueued in an SQS queue. A Lambda running our custom logic pulls from the queue automatically and attempts to send the event to the designated subscriber. If the send succeeds, the message is marked as completed and is deleted from the system. If the send fails, the message is requeued into SQS with a configuration that sets the appropriate retry backoff time.
The beauty of the system lies in its simplicity. Scaling, rate limiting, error handling, and basic monitoring are all done through configuration using existing tools provided by Amazon. For extra data points, we implemented additional custom metrics that are created in the Lambdas and forwarded to the metrics queue to be pulled at regular intervals for monitoring, alerting, and analysis.
Deploying Lambdas
We believe deployment should follow the best practice set by our existing workflows. This means new code is committed to a staging environment first and builds are thoroughly verified to be production ready by automated (and when appropriate, manual) acceptance tests. Access rights are enforced through internal systems and AWS’ IAM roles.
We built a powerful set of tools on top of the AWS SDK to assist local development, troubleshooting, rollouts, and remediation. For example, updating Lambdas would involve uploading the code to AWS S3, calling the ListLambda API to obtain all the Lambdas, and then the UpdateLambda API.
These tools enable the following typical workflow:
-
Independently test new AWS dependencies.
-
Create a new feature change locally.
-
Provision a subsystem in AWS to verify end-to-end scenarios manually.
-
Write tests.
-
Open a PR and, once approved, commit the changes.
-
Deploy the changes to the staging environment. Acceptance tests have to be green for the deployment to complete.
-
Deploy the changes to the production environment.
Monitoring and Testing
Monitoring is one of the core tenants of ensuring a successful service in production. We collect quantifiable, anonymous data to ensure our services are optimal and operational.
We have the following means of monitoring:
-
CloudWatch Logs. CloudWatch is an AWS service that provides active monitoring. Logging statements are printed by both the system and Lambda logic. We usually print informational and error messages for debugging purposes.
-
SignalFx Dashboards and Alerts. Square uses SignalFx, a SaaS-based monitoring and analytics platform. for internal monitoring and it is comprehensive — all API calls to AWS are monitored, and all traffic in AWS are monitored through either SignalFx’s direct integration with CloudWatch, or from the data we pull from the metrics queue. All the dashboards are backed by alerts that will trigger once certain conditions are met.
Unit tests are written for either individual functions or a small group of functions. They are located alongside production code following the Go testing conventions. They must pass before code can be pushed into master.
Integration and CI tests are similar to unit tests just with expanded scope. They test multiple systems or end to end systems and are gatekeepers for builds going into staging.
This is just the start! Interested in joining us? Check out our available jobs here.
To build with Square, sign up for an account at https://squareup.com/developer join our Slack community, and/or sign-up for our newsletter.
Authored By



