
Inferring Label Hierarchies with hLDA
The Problem: Organizing Square Support Center Articles
The Problem: Organizing Square Support Center Articles
At Square, we get businesses up and running quickly. We also work hard to make sure sellers get their questions answered quickly. When Square sellers encounter a problem with a Square product, one of the first lines of defense is Square’s Support Center, which has hundreds of articles to help sellers find answers to their questions.
Square’s Content team routinely adds articles to the Support Center. This set of articles has been growing organically so far; they’ve been written and published as sellers need them, and, as such, they were not written with any specific hierarchical structure a priori.
Now that we have hundreds of articles covering all topics across Square products, we’d like to know whether there’s a quick way to organize and tag them by topic so we can track how well groups of articles help sellers find answers to their questions. For example, how helpful are all the articles related to Square Capital? If we can understand article performance at the group level, we can figure out which topics’ content we should focus on improving.
While there is some structure to the Support Center (as seen under “Popular Topics” on the Square Support home page), organizing and tagging articles is a manual process. Given that our library changes all the time, it would be nice to have an automated way of handling the labeling.
We decided to give topic modeling a quick try to see if we could find commonalities between Support Center documents that could let us group and label them in a sensible way.
hLDA: A model for grouping documents by hierarchies of topics
One of the most commonly used techniques for topic modeling is latent Dirichlet allocation (LDA), which is a generative model that represents individual documents as mixtures of topics, wherein each word in the document is generated by a certain topic. However, LDA has some constraints. The number of topics must be chosen a priori, and all topics are assumed to have a flat hierarchy. We could imagine a scenario where it would be useful to have an unsupervised model infer a hierarchy of topics. For example, perhaps we would like to group all articles about Square hardware and then, within that group, organize the articles based on whether they are about magstripe readers, chip/contactless readers, Square Register, or other Square hardware.
The *hierarchical LDA* (hLDA) model extends LDA to infer a hierarchy of topics from a corpus of documents. We were interested in seeing whether we could use this technique to automatically organize Square’s Support Center articles.
hLDA makes it possible for us to assume that our topics are arranged in a tree-like structure where the tree has L levels and every node is a topic. With LDA, we choose topics using a mixture model with *K *random mixing proportions (where K is the number of possible topics), denoted by the K-dimensional vector θ. With hLDA, we instead choose a path in the L-level tree from root to leaf, choose a vector θ of topic proportions from a Dirichlet distribution of L dimensions, then use a mixture of the topics from root to leaf to generate the words that make up each document, using mixing proportions θ.
An issue with this approach is that there are many possible tree structures that we could choose from, even when we fix the number of tree levels at L, because we haven’t fixed the branching factor (the number of children at each node) at any of the levels of the tree. It would be nice to not have to determine the entire tree structure *a priori and have the structure be learned from the data instead. One method of choosing a tree structure is to build a hierarchy as data are fed into the model using the so-called nested Chinese restaurant process (nCRP). This is an extension of the *Chinese restaurant process (CRP); we won’t go into details here, but the CRP is useful when there is uncertainty around the number of mixture components in a mixture model¹.
Applying hLDA to a small data set
We tried hLDA with a subset of the IMDb Large Movie Review Dataset to see if it gave results that we might expect. We took 1,000 positive movie reviews and categorized them using an existing Python implementation of hLDA.
A sample of our raw data appears as follows:

We removed stopwords and tokenized so that the data became:

Running hLDA gave us the following (partial) results:
Figure 1. A sample of the representative words for a subset of nodes in a label tree that was learned via hLDA using positive IMDb movie reviews
The root of our tree includes general words like “film”, “movie”, and “great”, which seems like a reasonable outcome. From examining the words in the two nodes at the level below the root, we see that they may indicate a divergence in genre (“classic” and “insane” vs. “mother” and “daughter”). When we re-examine our now-labeled data set, we see that at least one review of “Nurse Sherri” (a 1978 horror film), “Apocalypse Now” (a classic movie about the Vietnam War), and “Driving Lessons” (a coming-of-age story starring Rupert Grint) were assigned to the left, middle, and rightmost leaves, respectively. Our model’s results seem to make intuitive sense.
Applying hLDA to Square Support articles
We then ran this algorithm on our corpus of Square Support Center documents.
After removing stopwords and numbers, then tokenizing, this article on FAQs about deposit options turns into a document where the first several words look like:

We obtain a hierarchical topic structure. We illustrate a small portion of the topics in the hierarchy below:
Figure 2. A sample of the representative words for a subset of nodes in a label tree that was learned via hLDA using the Square Support Center corpus.
As we might expect, words that refer to general use of Square, like account, payment, and card, are representative of our root topic. The algorithm has picked up on a few disparate aspects of the Square ecosystem that are reflected in the tree.
We also have visibility into the entire root-to-leaf path of the label structure, which helps us to understand why certain articles would be grouped into separate leaves on the tree even if they had similar keywords. We can see two sets of hardware-related topics within the tree — one with representative terms *ipad, usb, *and android, and the other with terms information, security, and services. Within their root-to-leaf path, these topics share terms like reader and *device, *but we expect the *ipad, usb, and android topic to also be related to updates. Devices Compatible with Square Contactless and Chip Card Reader *is within this topic. The text of this article describes which devices are compatible with Square Stand and also recommends installing updated versions of iOS and the Square app. Meanwhile the topic on the rightmost path (as mentioned above) is related to hardware, but also to security; the Privacy and Security and the Secure Data Encryption articles can be found within this leaf. Thus, even if a set of articles shares several keywords, having a hierarchy of topics may allow us to separate article groups from each other in a logical manner; to an extent, we can even trace the logic that the model used to separate the articles by following the root-to-leaf paths of the tree.
While the above topic paths seem sensible, we also see an alarming number of model results that don’t make much sense. Edit Your Shipping Address is grouped together with Best Practices for Square Invoices, for example, and Update your Taxpayer Identification Number is lumped in with Deposit Option FAQs. In fact, from a quick manual check of the model output, we see that the model has a large number of erroneous classifications and certainly does not work out of the box. We also see that the topic tree can change drastically from one model run to the next.
How, then, can hLDA be useful to us? We can use it to get a running start on annotating our articles by running the model, then working with content experts to tweak the annotations until they align with our own expectations of what the tree should look like. With the size of our Support Center (several hundred articles), this is not an unreasonable task.
Hierarchical Topic Modeling: Some Lessons Learned
From this foray into Square’s Support Center data, we can see that hLDA does a passable job of classifying articles at a high level, but on its own, it doesn’t have the accuracy we would require for implementation to be practical. We’ll likely get the most ROI out of building a first pass at a model, then asking content experts to tweak the model results until we have a sensible hierarchy of tagged articles. In the process of building this model, we came up with some general questions that we think would be useful to ask when considering using an unsupervised model to solve a document classification problem.
What is our purpose in running this model? Before using an unsupervised learning technique like hLDA to classify text in a corpus, we should know in advance how we plan to use the results. Say we want to use topic labels from hLDA to visualize our corpus. Or say that we want to use the topics as input features to a supervised learning model. In these cases, running hLDA out-of-box is probably sufficient. Alternatively, say we want to classify a large body of documents once, then use that classification for the foreseeable future. And say we have a strong preconception of what our tree structure should look like. In this case, we can use hLDA to do a first pass at discovering the topics within the dataset, then ask human content experts to tweak the results.
What is the ROI of building a model versus manual tagging? We will not get perfect results by running an unsupervised ML algorithm out of the box. But we also don’t want to ask content experts to manually tag hundreds of articles from scratch. How should we balance time spent on modeling with time spent on manual tagging? This varies by use case, but a sensible place to start is to run a quick hLDA to kick-start our corpus organization, then ask content experts to build off of those results. If a day of modeling can save a week or two of manual tagging, then we’ve achieved a decent ROI on the modeling work.
Does hierarchical clustering make sense for my corpus? hLDA is complex, and is only really worth doing if: 1) There is reason to believe a latent hierarchy exists within the dataset, and 2) That hierarchy can be* used* in some way. Developer work is required even for an out-of-box model run; there are hyperparameters to tune, and the user needs to specify the depth of the hierarchy beforehand. Consider the structure of the corpus, too: For our IMDb example, the vocabularies that describe different movies were disparate enough that our model was easily able to pick out individual movies. However, with Square Support Center articles, the topic trees varied from run to run. This suggests that Square’s Support Center corpus is not as modular as IMDb movie reviews, and we may need to rely on content experts for final annotations.
Using the Label Hierarchy
By applying hLDA to our Support Center data, we obtain an estimate of the Support Center hierarchy that, if we choose, we can improve through human restructuring and annotation.
Once we do have a high quality set of annotations, we can use them to answer many interesting questions about our dataset. Are certain topics within our Support Center overrepresented or underrepresented (in terms of the number of articles)? Does a certain topic have far more page views than others — perhaps meaning that we need our content team to pay extra attention to that topic in the future?
Say we’d like to predict the number of page views that a specific Support Center article will have in the next month. In addition to text features, we can include categorical features indicating which topic (at every level in the hierarchy) the article falls into.
Whether we use hLDA to kick-start the annotation process, or do all of our tagging by hand, annotations on our Support Center articles can bolster our current efforts to track Support Center articles, with the goal of ensuring that Support Center is getting Square sellers to their answers as quickly and efficiently as possible.
Appendix: A brief primer on LDA
The nuts and bolts of LDA have been covered well elsewhere, but the general idea is that there exists an unobserved collection of topics each of which uses a small set of words frequently. The LDA paradigm assumes each observable document is made up of a mixture of these unobserved topics.
LDA models each document as being created by drawing words from each topic with a certain probability. During the learning phase, it tries to determine which topics were used to generate the document.
To put it more concretely, we can assume that we have a data set comprised of a corpus of documents, wherein each document is a set of words that comes from a set vocabulary. We can additionally assume that we have a set of word distributions (topics), and that each document was generated via a mixture model with random mixing proportions. As introduced here, the mixture distribution for any individual word can be described with
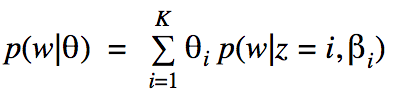
where p is the probability of drawing a word w given a K-dimensional vector θ which indicates document-specific random mixing proportions, z is a multinomial variable with a different distribution of topics for each value of z, β is a matrix (treated as fixed for now) wherein βij indicates the probability of a specific word wi being within a specific topic zj, and K is the number of topics in the corpus (Blei, Griffiths, Jordan, Tenenbaum 2003). When the distribution p(θ|⍺) (where ⍺ is a global parameter) is chosen to be a Dirichlet distribution, then we are effectively running an LDA model.
As mentioned earlier, LDA has some constraints; the number of topics needs to be chosen beforehand, and we have no sense of hierarchy within the groups. For the hLDA example that we built using IMDb movie reviews, one could argue that the layer right below the root node constitutes a set of “genre” groups, and each leaf might roughly correspond to a specific movie. LDA can cluster the reviews by movie, but we lose the genre groupings.
References
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent Dirichlet allocation. Journal of machine learning research, 3(Jan), 993–1022.
Frigyik, B. A., Kapila, A., & Gupta, M. R. (2010). Introduction to the Dirichlet distribution and related processes. Department of Electrical Engineering, University of Washington, UWEETR-2010–0006.
Griffiths, T. L., Jordan, M. I., Tenenbaum, J. B., & Blei, D. M. (2004). Hierarchical topic models and the nested chinese restaurant process. In Advances in neural information processing systems (pp. 17–24).
Maas, A. L., Daly, R. E., Pham, P. T., Huang, D., Ng, A. Y., & Potts, C. (2011, June). Learning word vectors for sentiment analysis. In *Proceedings of the 49th annual meeting of the association for computational linguistics: Human language technologies-volume 1 *(pp. 142–150). Association for Computational Linguistics.
Pitman, J. (2002). Combinatorial stochastic processes. Technical Report 621, Dept. Statistics, UC Berkeley, 2002. Lecture notes for St. Flour course.
Footnotes
(1) The CRP is related to the Dirichlet process in that the CRP is a specific kind of stochastic process, and the Dirichlet process is a stochastic process wherein each observation is a probability distribution. The CRP can be used to construct a Dirichlet process sample. Section 5.1 of Introduction to the Dirichlet Distribution and Related Processes describes this in some detail.
Authored By

- The Problem: Organizing Square Support Center Articles
- hLDA: A model for grouping documents by hierarchies of topics
- Applying hLDA to a small data set
- Applying hLDA to Square Support articles
- Hierarchical Topic Modeling: Some Lessons Learned
- Using the Label Hierarchy
- Appendix: A brief primer on LDA
- References
- Footnotes


