
Caviar’s Word2Vec Tagging For Menu Item Recommendations
By Christopher Skeels and Yash Patel
Background
Recommendation Collections
At Caviar, Square’s food ordering app, one way we connect diners to great food is with restaurant and menu item recommendations. Rather than presenting a single overwhelming stream of recommendations, we segment them into distinct recommendation collections, each characterized by a common theme (e.g., “Delivery Under 30 Minutes”, “Pizza”, and “Recommended For You”). Individual collections are powered in various ways, including category taggings like cuisine type and dietary restriction, editorialized “best of” lists, custom algorithms, and machine learning:
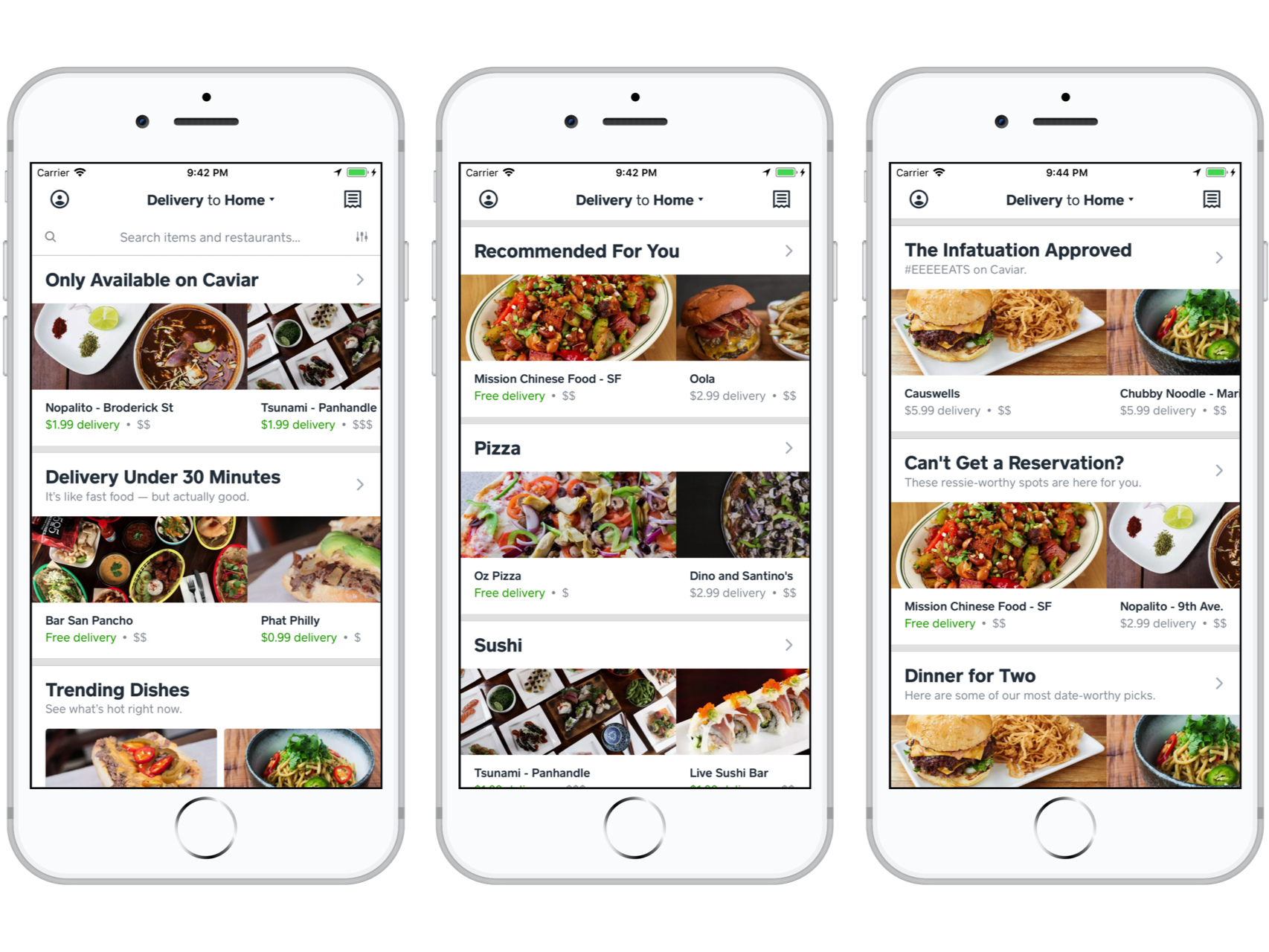 Current restaurant-focused Caviar home feed recommendation collections.
Current restaurant-focused Caviar home feed recommendation collections.
Tagging
Of the collection sources, category taggings (e.g., “Pizza”, “Vegetarian”, and “Family Style”) are a simple yet intuitive and powerful way to segment content for use in a collection. The primary issue is in collecting and maintaining useful, accurate taggings. We’ve had success at manually tagging our restaurants, but as we’ve grown, we’ve been challenged to do the same for the greater than two orders of magnitude more menu items we have associated with our restaurants. As we continue to grow, hand-tagging our restaurants will also become impractical. To head this off, we are investing in automated methods of tagging, starting first with menu items.
Who’s Got Time To Supervise?
While automated methods like string matching and text classification are the typical paths to more scalable tagging, they have some non-trivial costs. Regular expressions and literal string matching are generally brittle, and the rules have to be hand-crafted and evolve over time as exceptions are found. Supervised text classification is less brittle but still requires hand-crafting a training set. A notable challenge is selecting the training examples. For example, if you want to train a pizza classifier, do you need to provide a negative example for all menu items that aren’t pizza? How many examples do you need for each type of “not pizza”? Is “dessert pizza” a positive or negative example? Et cetera.
Not So Fast...
In an attempt to avoid these costs, we’ve explored the viability of unsupervised machine learning methods such as clustering and similarity search. So far, we’ve found clustering and topic modelling to be insufficient alone. One problem is that clustering algorithms produce a single set of clusters, to each of which we must manually decide what tag to assign. An additional problem is that we have to provide the algorithm with a subjective number of expected clusters. While we may be able to estimate the upper bound on the number of cuisine types or dietary restrictions possible and supply that to the algorithm, we have no guarantee that the output clusters will conform to the kinds of intuitive groupings we want to tag our menu items with. We’ve found similarity search, in contrast, more promising.
Searching For A Free Lunch
At its simplest, similarity search compares a query item against a set of candidate items using an appropriate metric to determine which candidates are most similar to the query. If we can treat both our menu items and tags of interest as comparable items, then we can use similarity search to automatically classify our menu items with the tags most similar to them. Ideally, we can transform our tags’ and menu items’ text-based representations into fixed-length numeric vectors that can be meaningfully compared using a simple metric like cosine similarity (e.g., where the vector for tag “Sandwich” would be cosine-similar to the vectors for menu items like “Reuben” and “Grilled Cheese”) using a method such as Word2Vec, GloVe, or TF-IDF. Note that the use of curated tags here is a subtle, interesting departure from the typical use of similarity search in recommender systems where items are only compared with each other. Below, we walk through our recent efforts using Word2Vec-based similarity search to classify menu items for use in recommendation collections.
Walkthrough
Approach
As mentioned above, our approach was to recast what would typically be a classification problem as a similarity search problem. The basic steps followed were:
-
Train a Word2Vec model using Caviar’s restaurant menus as the corpus.
-
Convert each menu item into a vector using the Word2Vec model.
-
Curate a set of candidate tags and perform the remaining steps for each distinct set.
-
Convert each candidate tag into a vector using the Word2Vec model.
-
For each menu item vector, compare with each candidate tag vector and classify the menu item as the candidate tag that was most similar.
-
Optionally, filter out menu items whose most similar candidate tag was below a minimum threshold.
-
Validate the classification results via cluster visualization.
-
Select menu items for a given tag and display as a recommendation collection in the Caviar app.
Steps 1 & 2: Word2Vec Model + Vector Averaging
Word2Vec is neural network word embedding technique that learns a vector space model from a corpus of text such that related words are closer in the space than non-related words. This allows for interesting operations like similarity comparisons and vector algebra on concepts. For our purposes, we’d like to see a vector space model similar to the following:
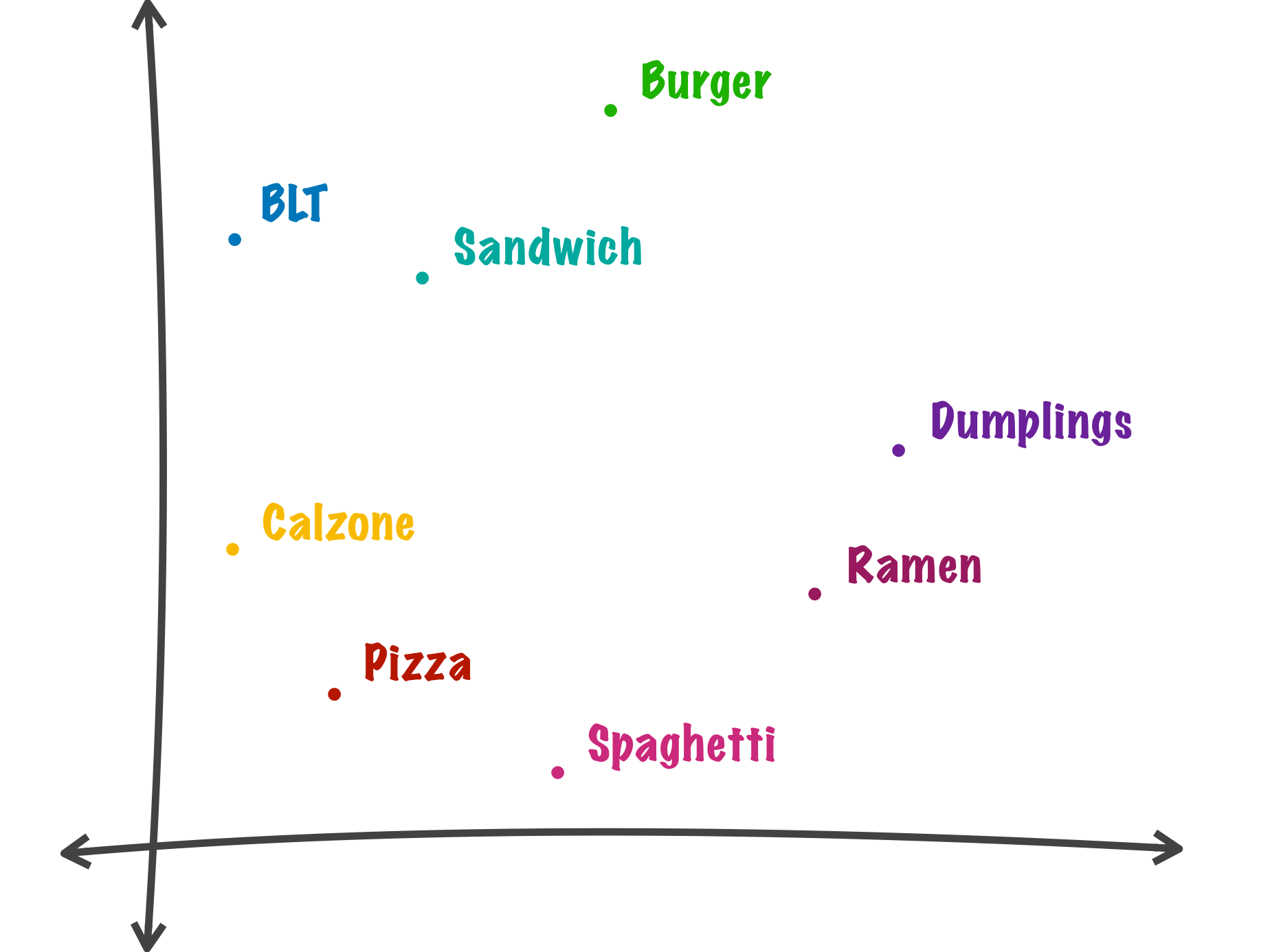 Example Word2Vec vector space trained with menu data where similar foods are closer to each other.
Example Word2Vec vector space trained with menu data where similar foods are closer to each other.
We used the Gensim package to train a Word2Vec model on a corpus of Caviar restaurant menus. While there are a number of good pre-trained Word2Vec models based on large corpuses such as Wikipedia and Google News that we tried first, we found they did not perform as well as our custom model trained on Caviar’s restaurant menus alone. It appears that food language in menus is qualitatively different than food language in general sources like encyclopedias and news. This is something we plan to explore more in the future.
One limitation of Word2Vec for our purposes is that it only deals with individual words. For our formulation to work, we need to be able to create fixed-length vectors for the many multi-word tags and menu items that we have (e.g., the tag “Indian Curry” and the menu item “Big Bob’s Chili Sombrero Burger”). There are advanced techniques for this such as Doc2Vec, but we found that simply averaging the vectors for each word in a phrase worked well in practice.
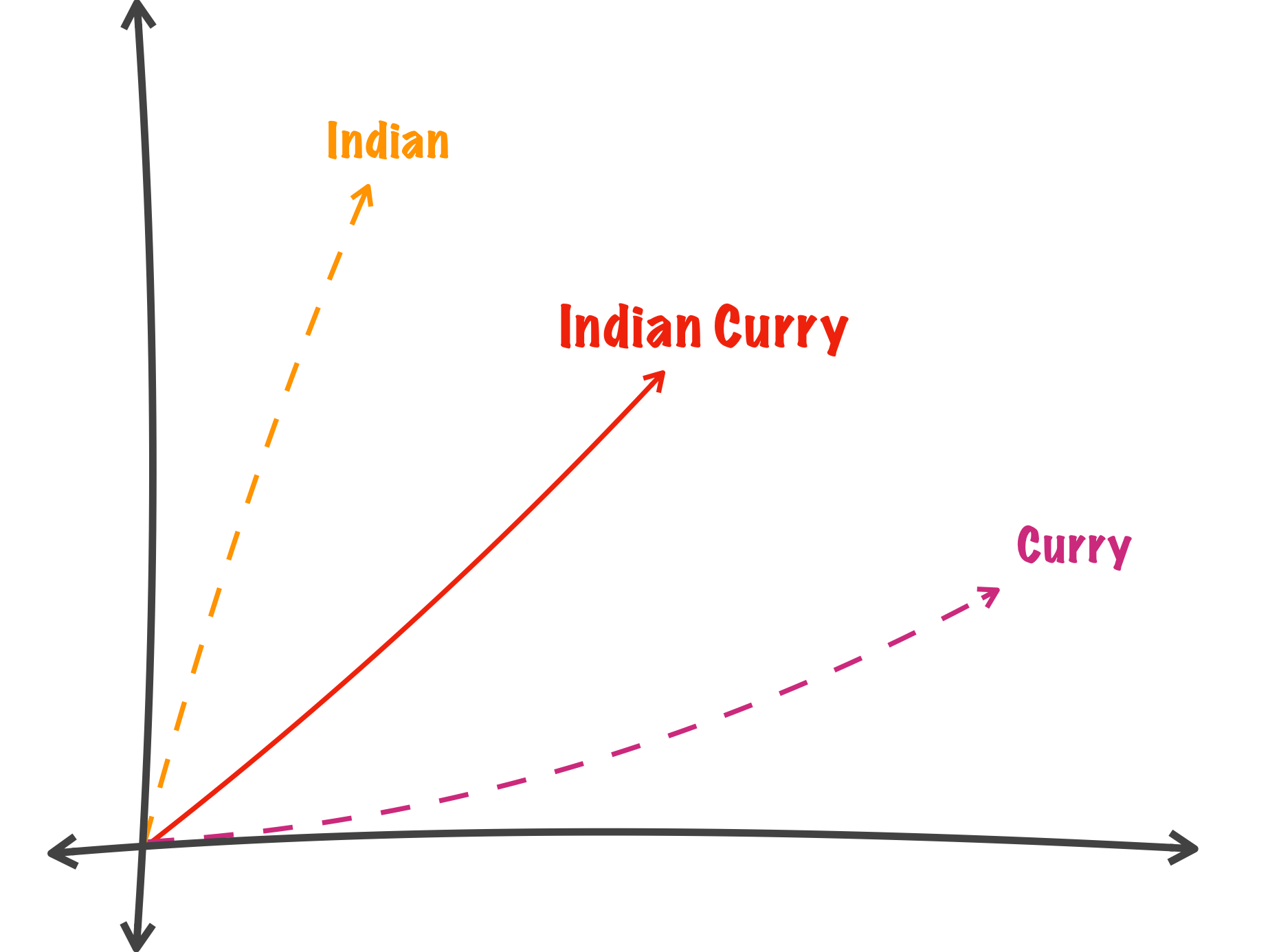 Example vector averaging of “Indian Curry”.
Example vector averaging of “Indian Curry”.
Steps 3 & 4: Candidate Tag Selection
A key step in our approach is selecting the candidate tags. Our primary method is to compile sets of related tags such as cuisine types(e.g., “Pizza”, “Burger”, and “Thai Curry”) and dietary restriction (e.g., “Vegetarian”, “Vegan”, and “Gluten Free”) where we expect most menu items to be best classified by only one of the tags in the set. We used cluster visualization to demonstrate this approach with cuisine types. An additional promising method is crafting individual multi-word tags that capture a broader concept (e.g., “Cake Cookies Pie”) and match menu items beyond just those listed in the tag (e.g., match cupcake and donut items for “Cake Cookies Pie”). Crafting these types of tags is more of an iterative process akin to coming up with a good search engine query. We explored this approach with a couple of in-app collections as shown in a later section.
Looking ahead to Step 7: Validation via Cluster Visualization
As mentioned in the introduction, we wanted to avoid the cost of supervised methods, specifically the creation of a ground truth set for training and validation. However, we still needed a way to validate our tags, so as a compromise, we leveraged interactive cluster visualization to do ad hoc manual validation instead. We adapted the Tensorflow Embedding Projector for this purpose:
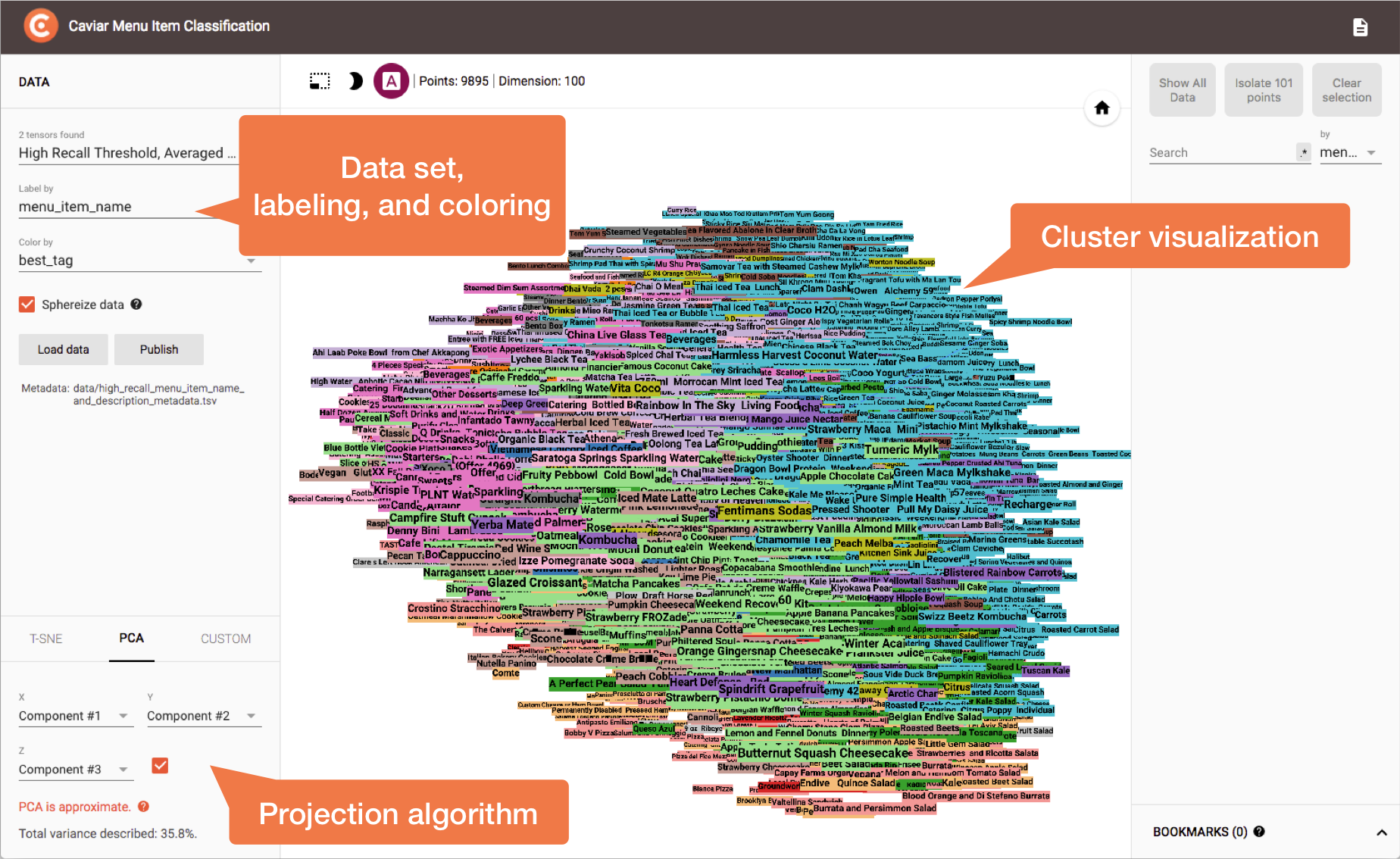 Caviar Menu Item Classification Projector.
Caviar Menu Item Classification Projector.
 Caviar Menu Item Classification Projector with menu item selected.
Caviar Menu Item Classification Projector with menu item selected.
Steps 5–7: Cuisine Type Visualization
By following the outlined steps for every menu item with cuisine types as the candidate tag set, we obtained a cosine similarity score for each of the tags. We classified each menu item as the cuisine type with highest similarity score. The following sequence of figures highlights the explorations and validations we performed on the resulting data.
In the following figure, clusters are colored by most similar tag with no minimum similarity threshold set. This is our “high recall” scenario. It’s quite noisy, and we see a number of misclassified menu items. In some cases, this is because the menu item is just hard to classify. In many cases, though, it is because the menu item’s true cuisine type is not present in our cuisine type candidate tag set (e.g., we didn’t include tags for “Kombucha”, “Cheesecake”, or “Coconut Water”), and with no minimum similarity threshold set, an incorrect naive classification is made.
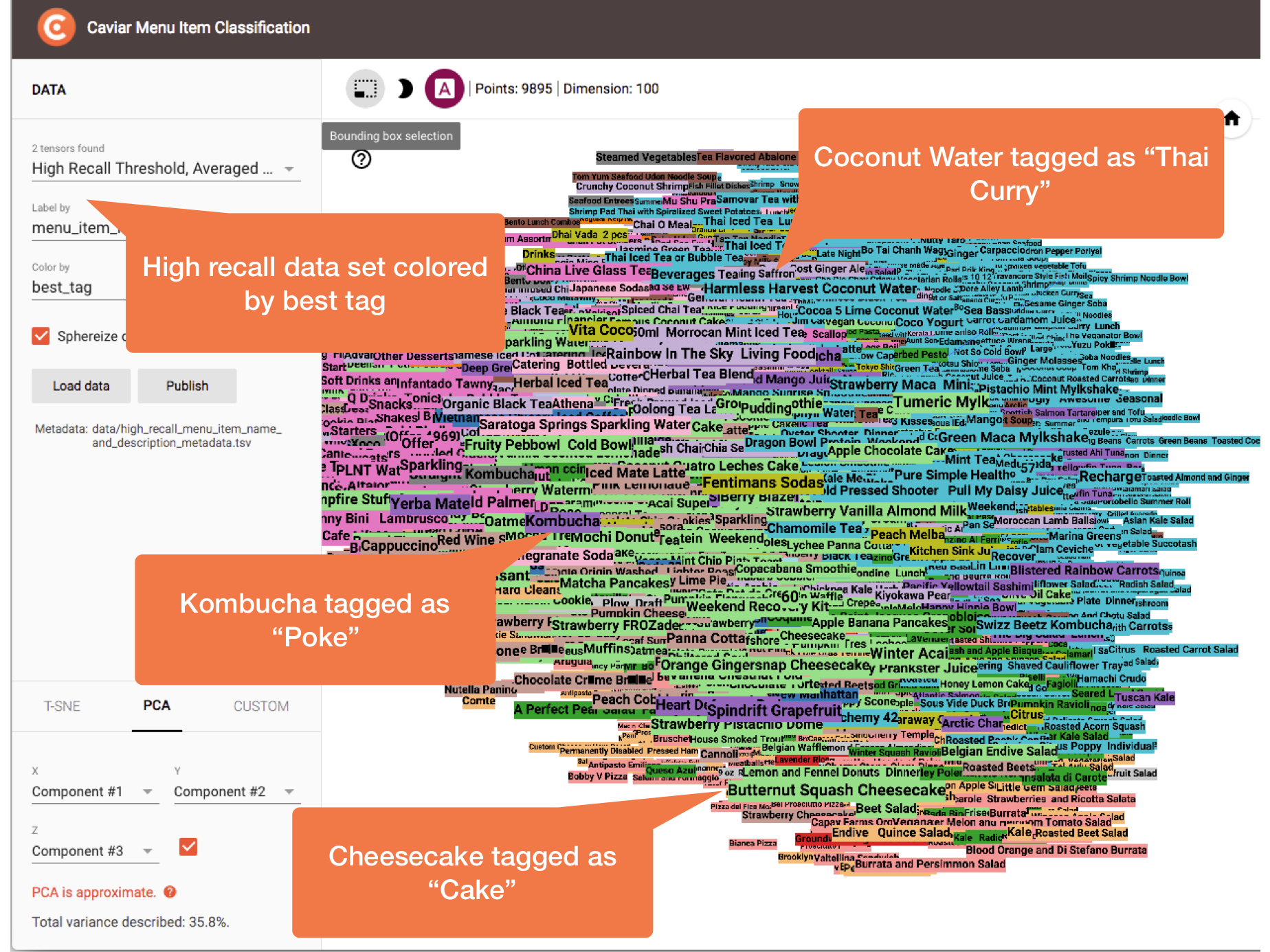 Colored by most similar tag with no minimum similarity threshold set, our “high recall” scenario.
Colored by most similar tag with no minimum similarity threshold set, our “high recall” scenario.
The following figure demonstrates one of the many correct classifications:
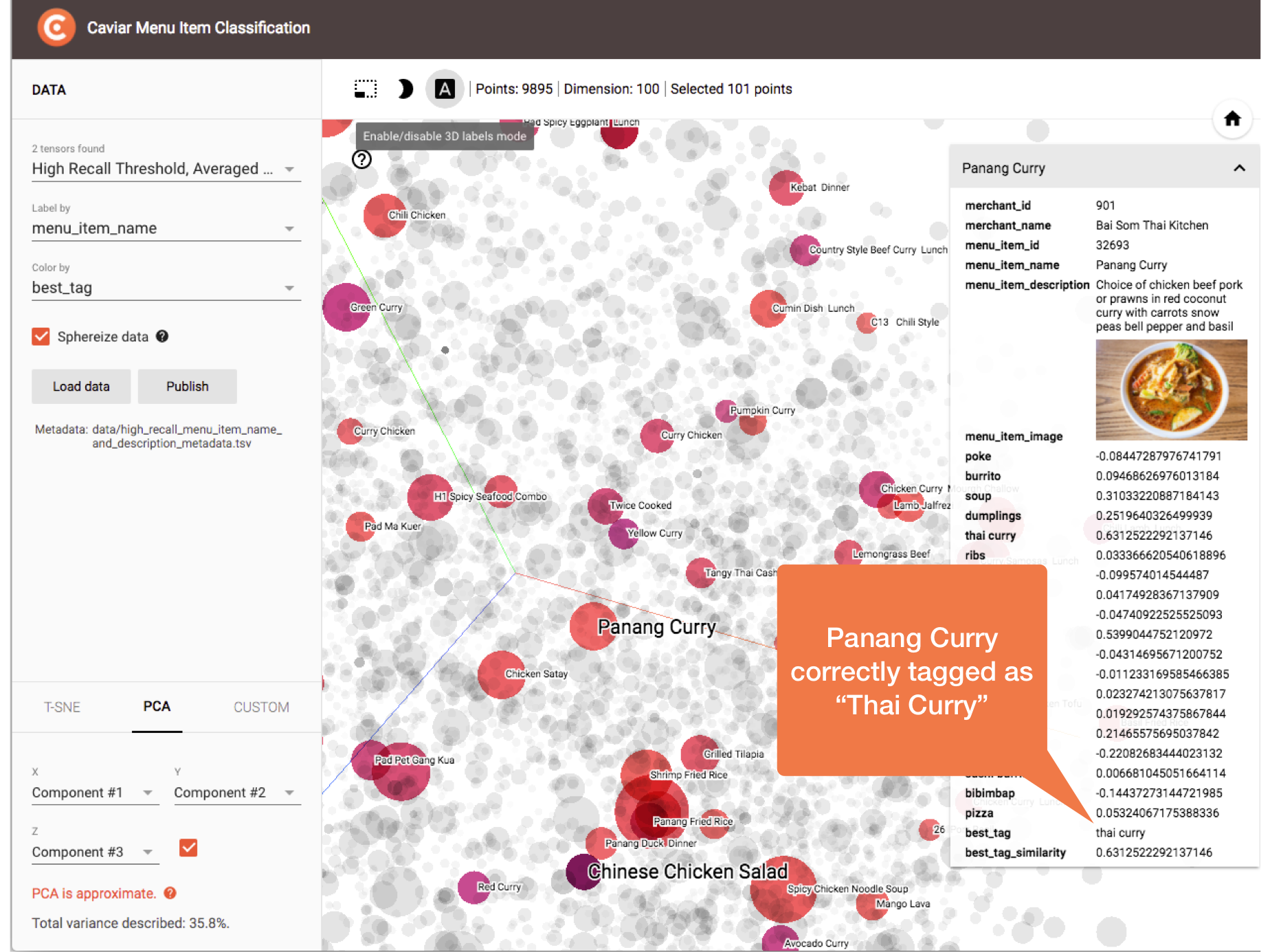 Panang Curry correctly classified as “Thai Curry”.
Panang Curry correctly classified as “Thai Curry”.
The following figure demonstrates one of our misclassification scenarios. In this case, Tom Yum Noodle Soup is incorrectly classified as “Thai Curry”. This is harder to classify correctly due to Tom Yum being more closely related to Thai cuisine than to typical soups like chicken noodle and minestrone:
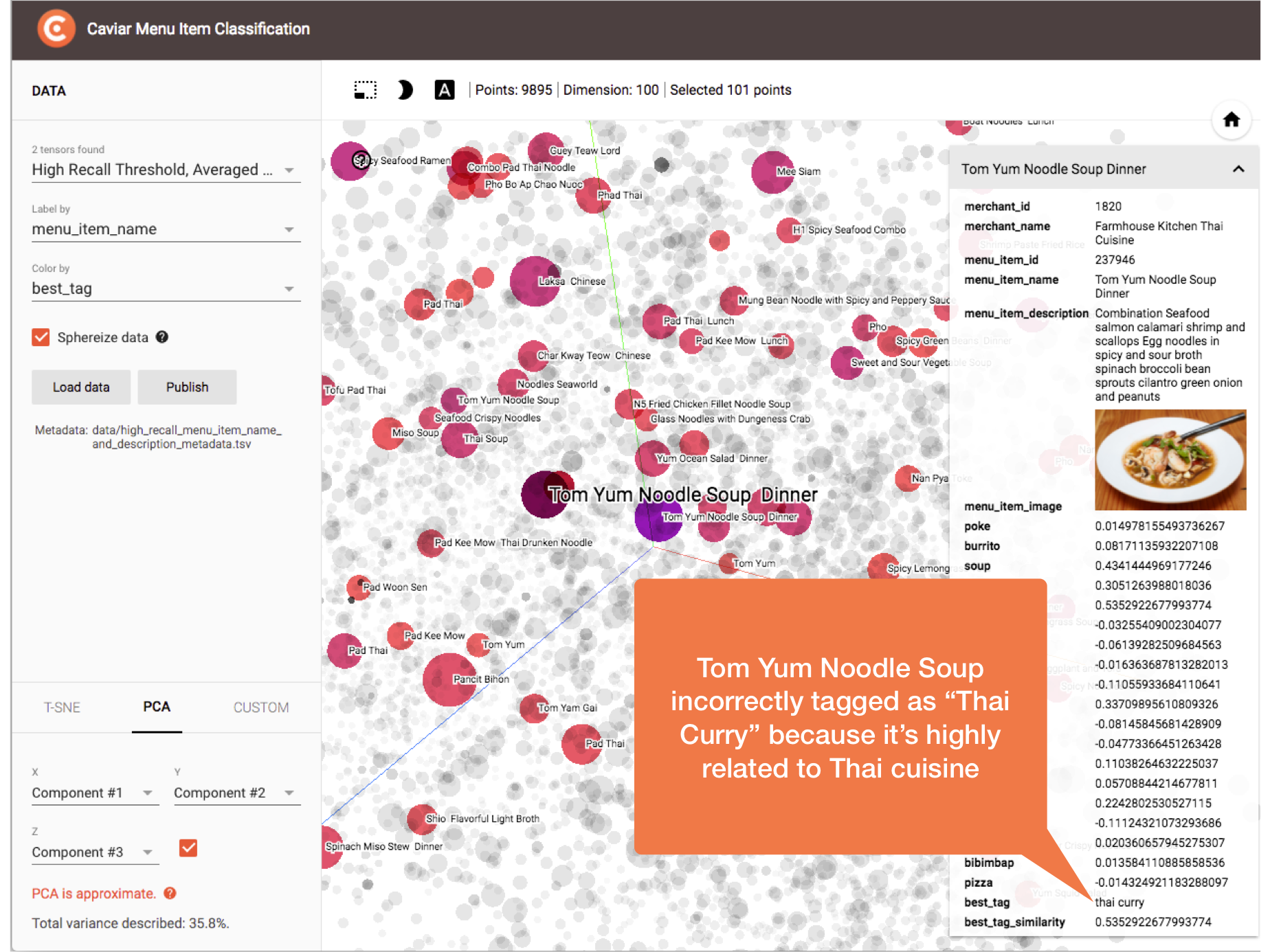 Tom Yum Noodle Soup incorrectly classified as “Thai Curry” because of closer association with Thai cuisine than soup.
Tom Yum Noodle Soup incorrectly classified as “Thai Curry” because of closer association with Thai cuisine than soup.
The following figure demonstrates our primary misclassification scenario. In this case, Gyros Plate is incorrectly classified as “Fries” due to the menu item’s cuisine type (e.g., “Mediterranean” or “Gyros”) not being present in our cuisine type candidate tag set:
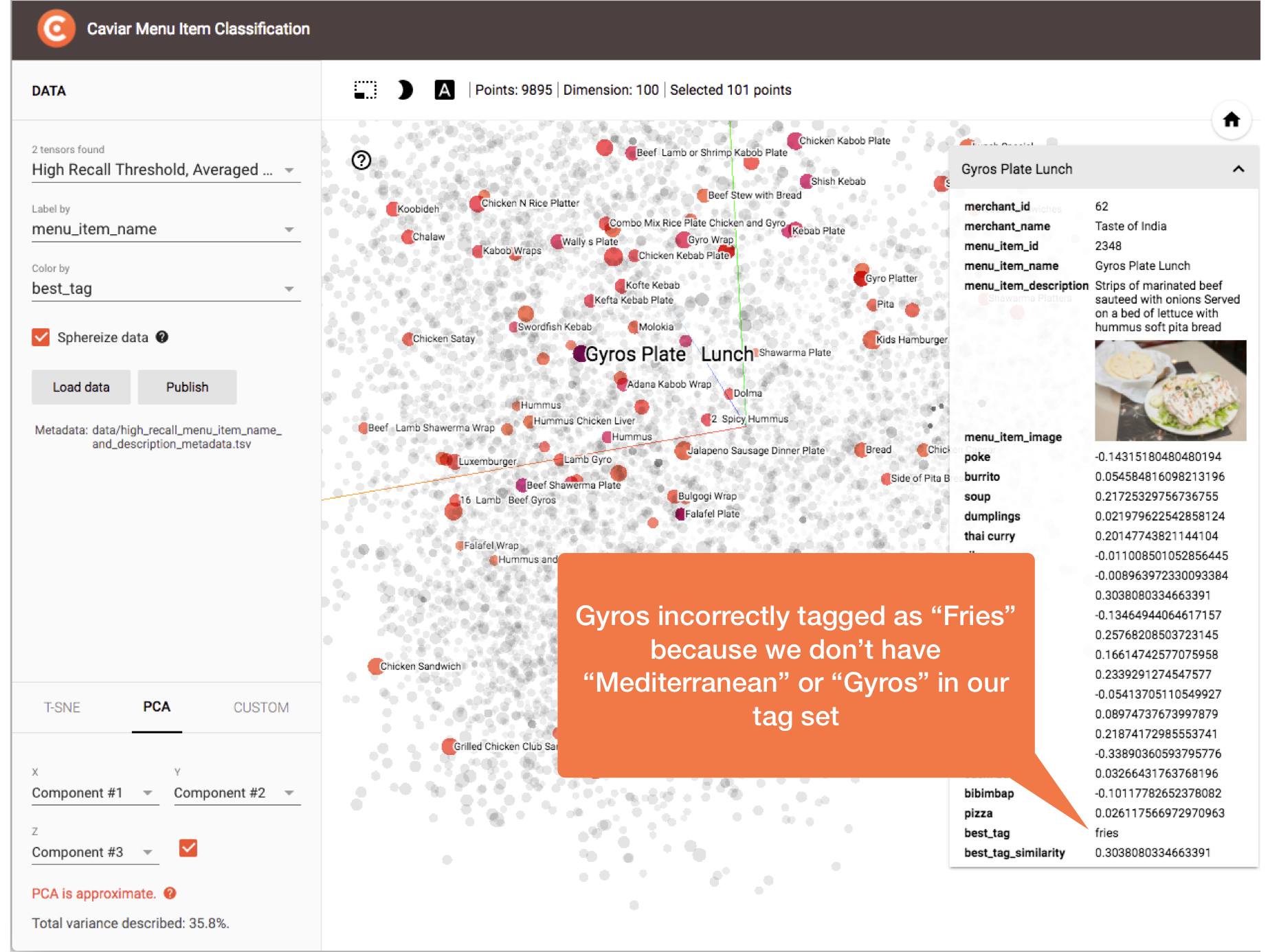 Gyros Plate incorrectly classified as “Fries” due to missing tag.
Gyros Plate incorrectly classified as “Fries” due to missing tag.
In the following figure, clusters are colored by most similar tag with a minimum similarity threshold set (i.e., only classifications of 0.7 cosine similarity or greater are kept). This is our “high precision” scenario and it is much better! We see good visual separation via inspection, and we find almost no misclassified menu items beyond the ambiguous cases we discuss next:
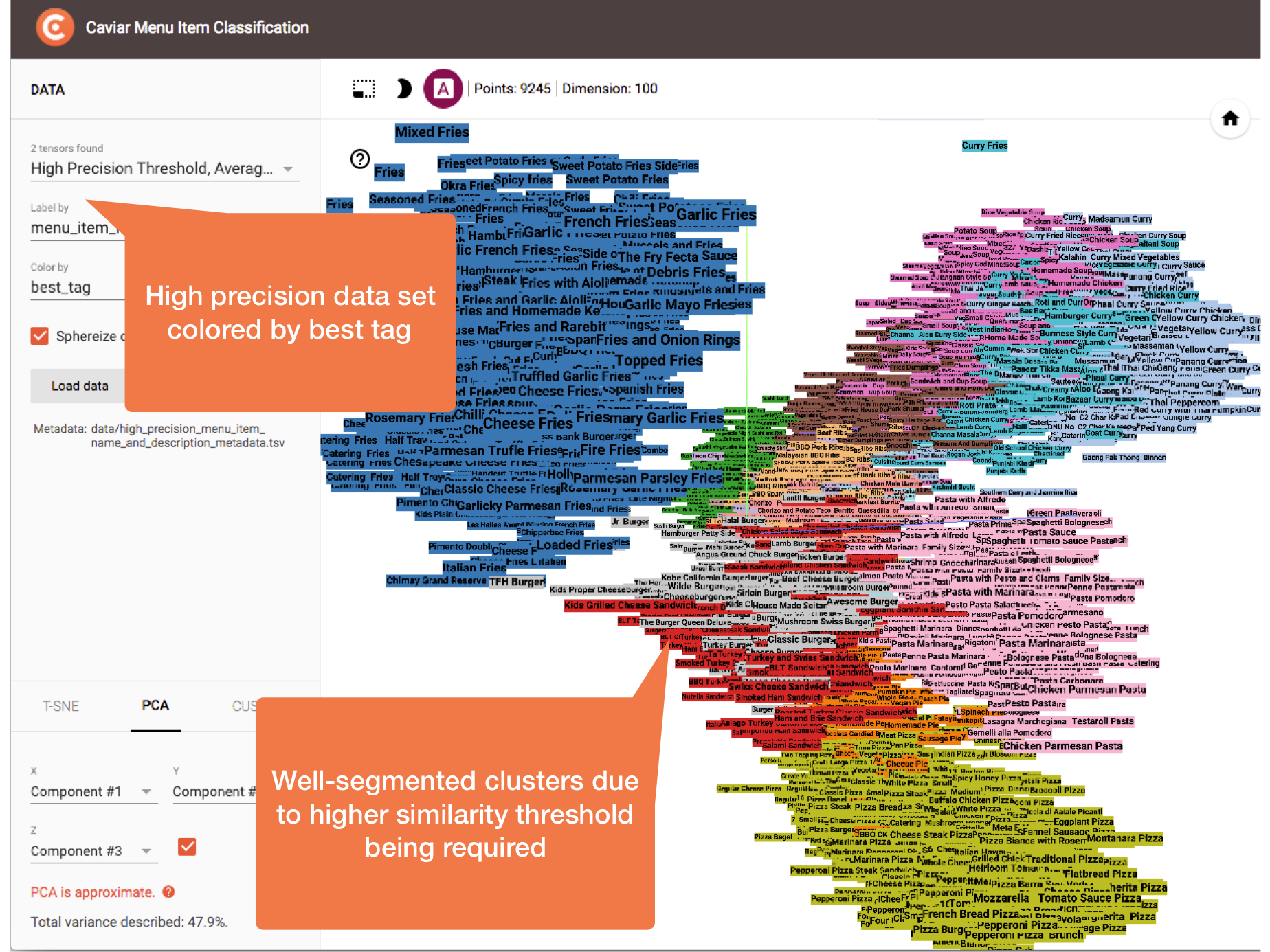 Colored by most similar tag with a minimum similarity threshold set, our “high precision” scenario.
Colored by most similar tag with a minimum similarity threshold set, our “high precision” scenario.
In the next figure, we wonder, “Is it pizza or is it fries?” The answer is “Both!” The Pizza Fries menu item has high scores for both the “Pizza” and “Fries” tags, with “Pizza” edging out “Fries”. That the menu item is located equidistantly from the two distinct clusters demonstrates one of the intuitive strengths of this method. There is no reason we couldn’t classify items like this with multiple best tags:
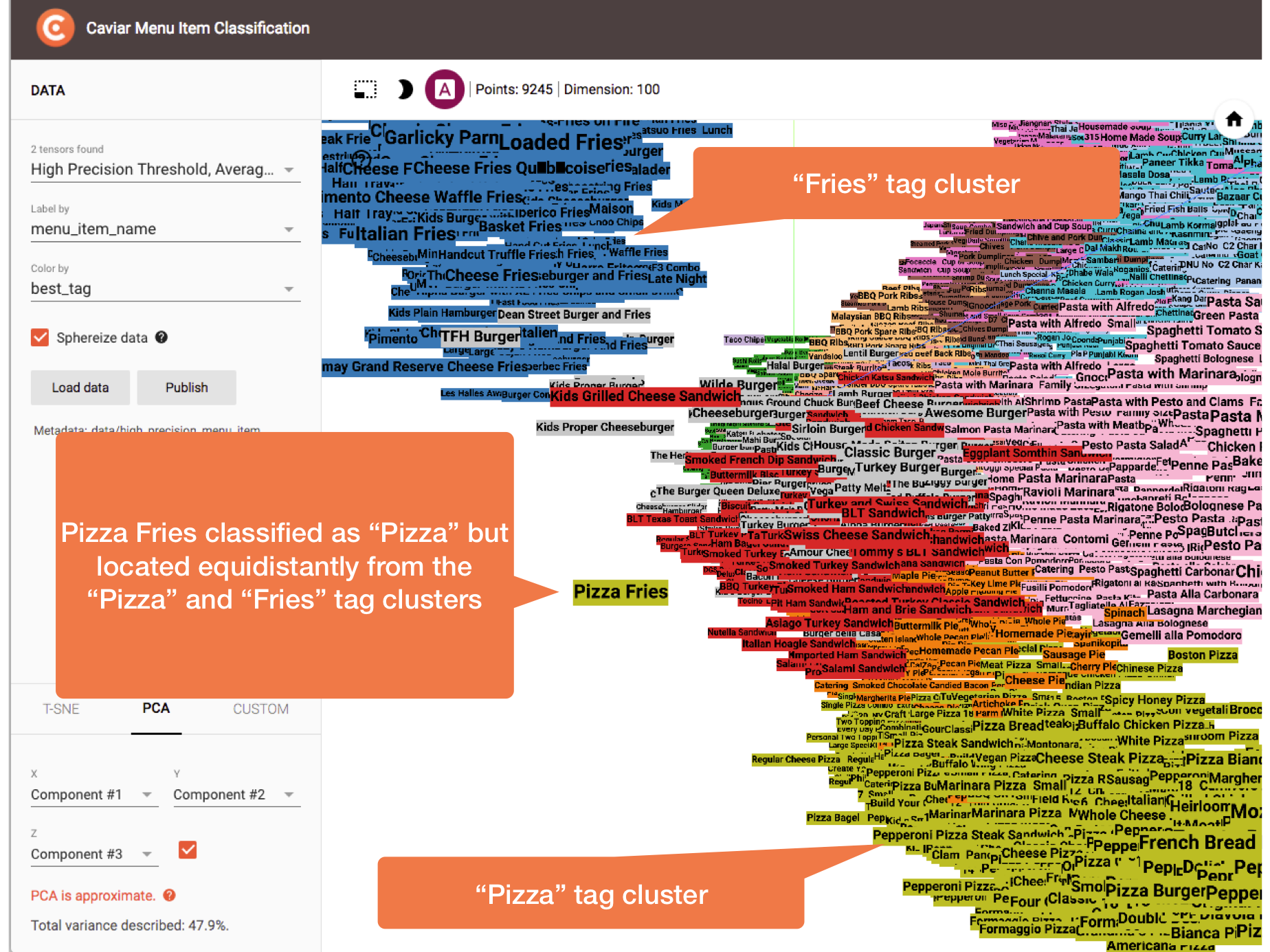 Is it pizza or is it fries? Answer: both! The Pizza Fries menu item has high scores for both the “Pizza” and “Fries” tags, with “Pizza” edging out “Fries”.
Is it pizza or is it fries? Answer: both! The Pizza Fries menu item has high scores for both the “Pizza” and “Fries” tags, with “Pizza” edging out “Fries”.
In the next two figures, clusters are labeled with the classified tag rather than menu item name. The first figure is colored by the classified tag and the second figure is colored by similarity to the “Pizza” tag. In the first figure, we see “Pasta” and “Pie” items are closer to “Pizza” than other less similar items like “Sushi” or “Dumplings”. In the second figure, thanks to the similarity gradient, we can easily see a range from “Pizza” to “Not Pizza”. This is another demonstration of the intuitive mapping between the spatial arrangements and the Word2Vec-based similarities that allowed us to perform ad hoc validations on our results:
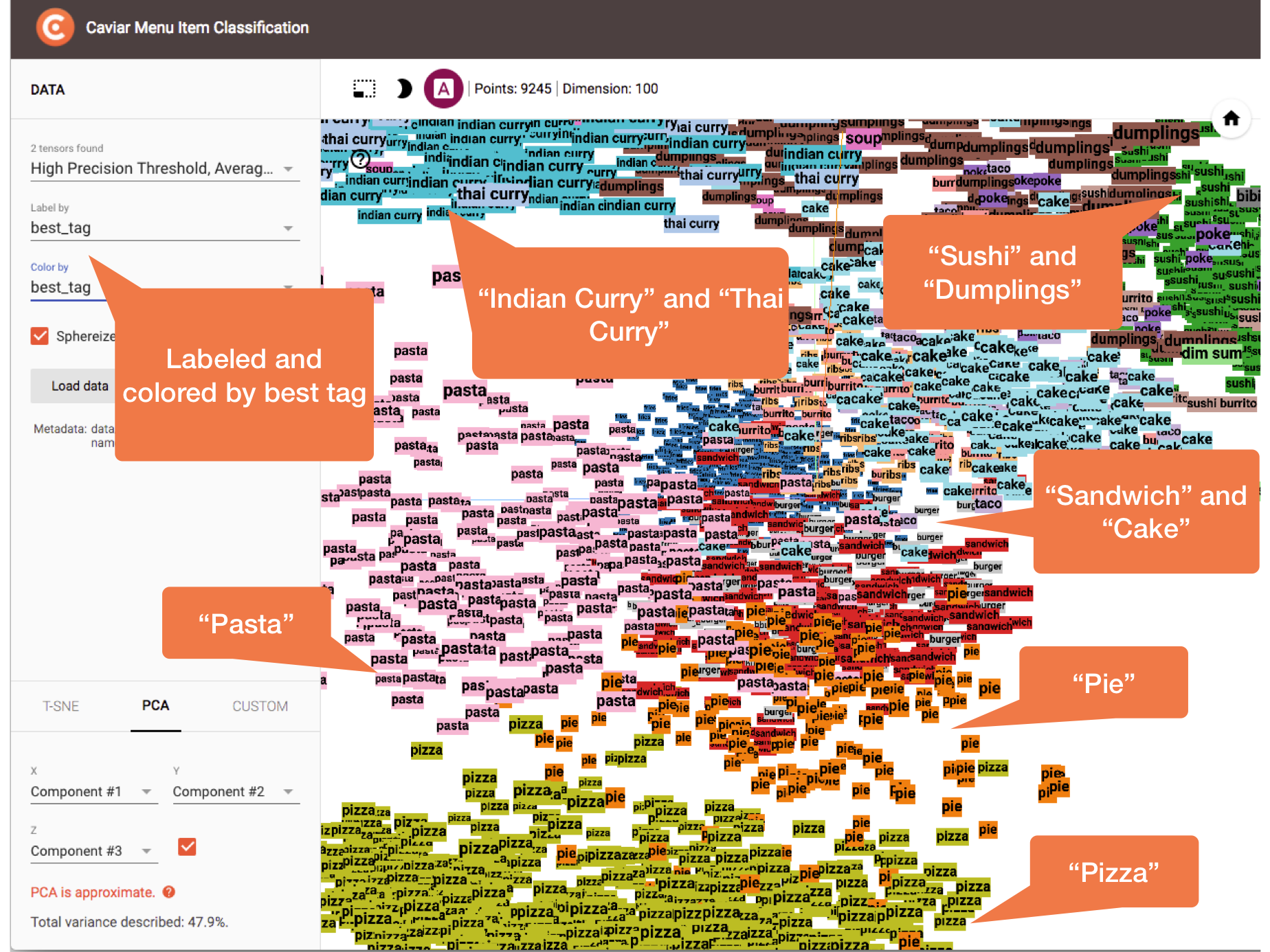 Colored and labeled by best tag, this view demonstrates the intuitive spatial arrangements we get from Word2Vec similarities such the “Pizza” items being near the “Pasta” items.
Colored and labeled by best tag, this view demonstrates the intuitive spatial arrangements we get from Word2Vec similarities such the “Pizza” items being near the “Pasta” items.
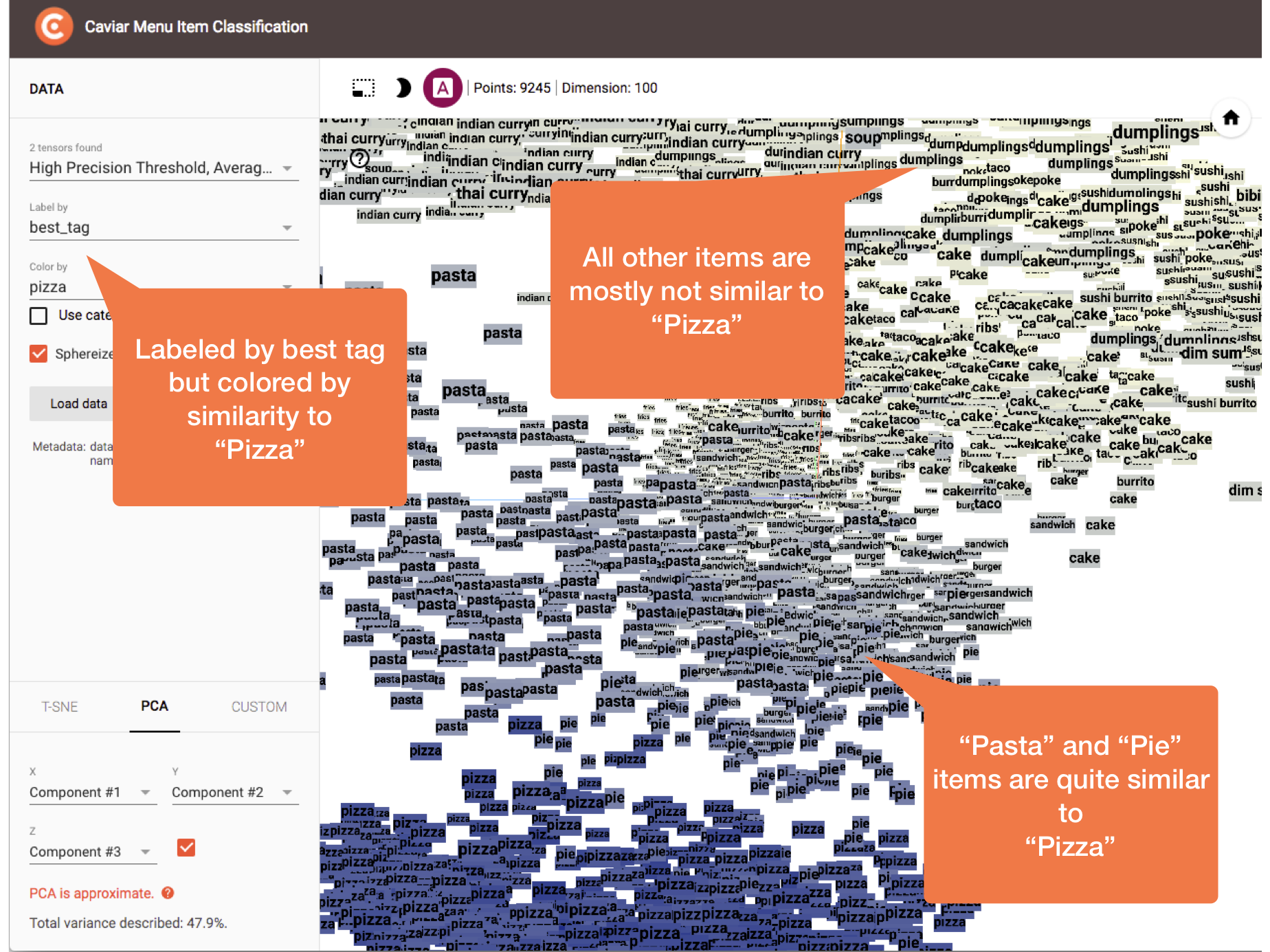 Colored by similarity to “Pizza” tag, we see a similarity range from “Pizza” to “Not Pizza” further demonstrating the intuitive spatial arrangements we get from Word2Vec similarities.
Colored by similarity to “Pizza” tag, we see a similarity range from “Pizza” to “Not Pizza” further demonstrating the intuitive spatial arrangements we get from Word2Vec similarities.
Step 8: Automated Recommendation Collections
Our ultimate goal with this work was to automate menu item recommendation collections from the Word2Vec-based taggings, and we’ve already implemented a few examples. The following figures demonstrate collections for both simpler cuisine type tags and more advanced multi-word concept tags.
In the following figure, we show recommendation collections for the “Pizza” and “Thai Curry” tags. These are very promising, showing a range of items from the standard (e.g., Cheese Pizza and Panang Curry) to the exciting (e.g., Calabria Pizza and Chicken Pumpkin Curry):
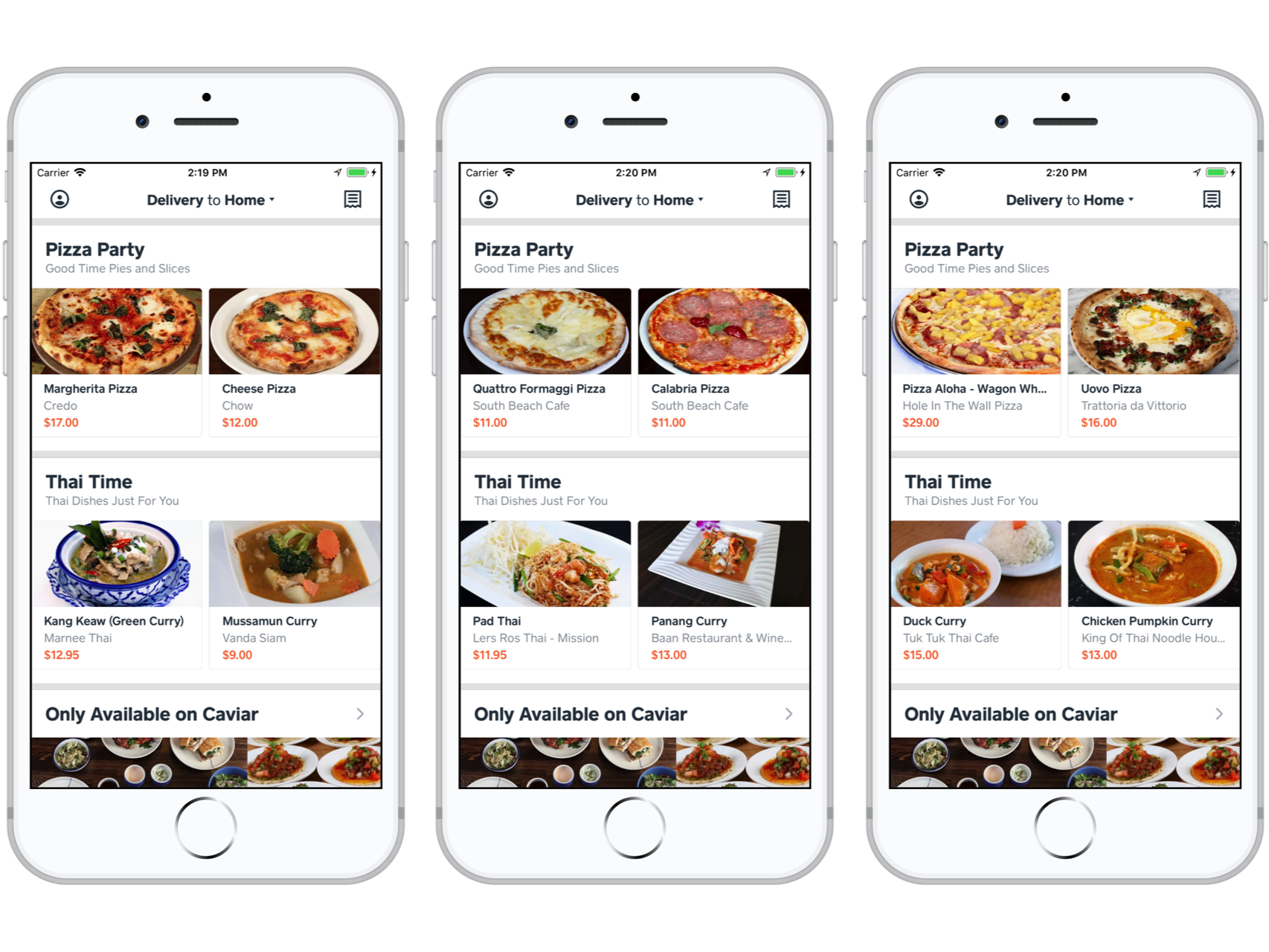 Cuisine type menu item recommendation collections for the “Pizza” and “Thai Curry” tags.
Cuisine type menu item recommendation collections for the “Pizza” and “Thai Curry” tags.
In the following figure, we show recommendation collections based on the interesting approach of crafting multi-word concept tags. We used “Cake Cookies Pie” as the tag for the “For Your Sweet Tooth” concept collection and “Tikka Tandoori Biryani” as the tag for the “North Indian Fare” concept collection. These too are very promising. In the “For Your Sweet Tooth” collection, we see items beyond the “Cake Cookies Pie” tag such cupcakes, donuts, ice cream, and even an ice cream scoop. In the “North Indian Fare” concept collection, we see items beyond the “Tikka Tandoori Biryani” tag such as Saag Paneer and Itsy Bitsy Naan Bites:
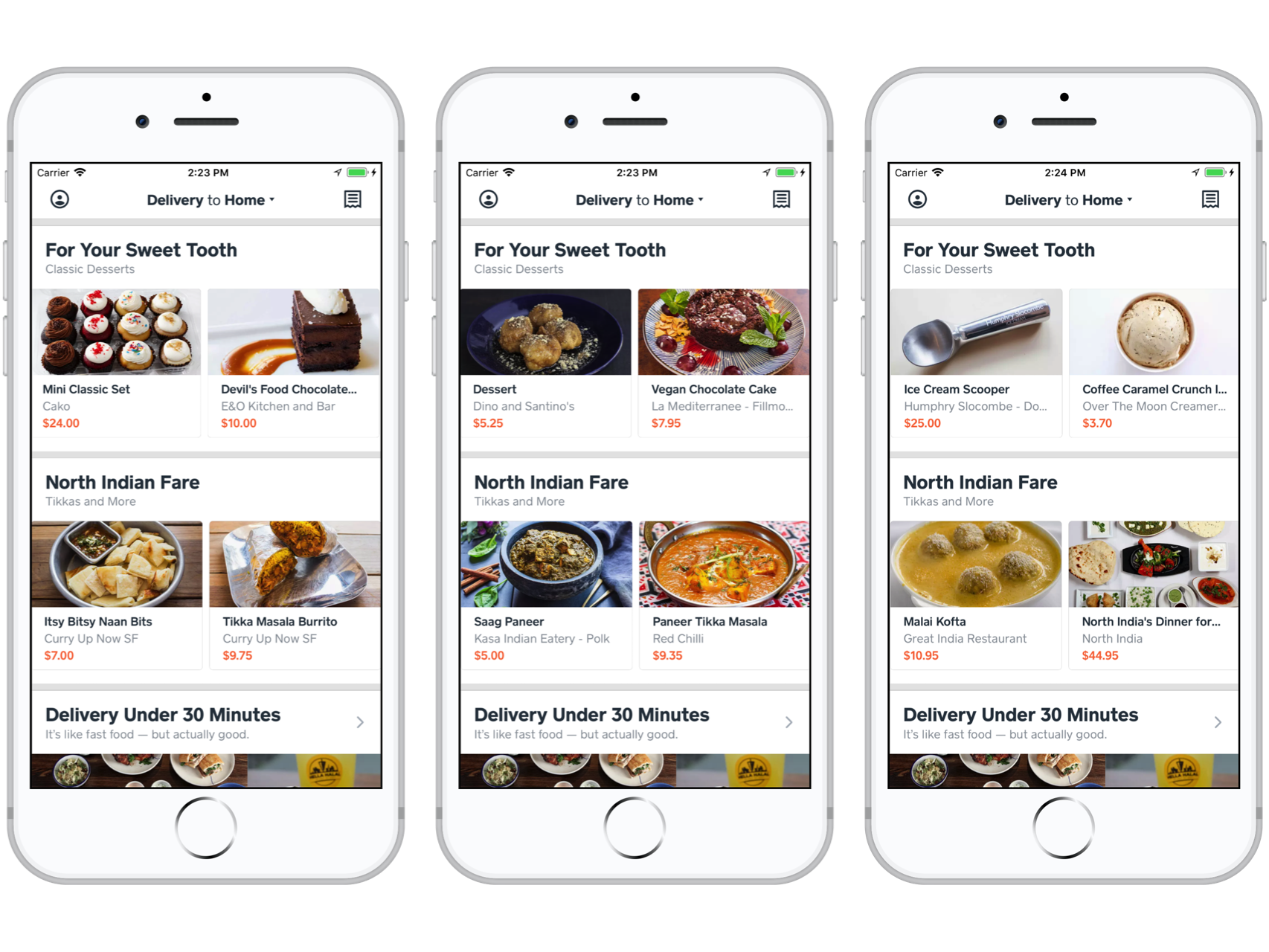 Recommendation collections for the concepts “For Your Sweet Tooth” and “North Indian Fare”.
Recommendation collections for the concepts “For Your Sweet Tooth” and “North Indian Fare”.
Wrap-up
We think Word2Vec-based similarity search is a simple yet powerful method to aid our expansion into automated tagging and menu item recommendation collections. It gives us an immediate path to fielding these types of collections while buying us time to follow up on more time-consuming methods like string matching and supervised text classification. Longer term, we will develop a means of automated validation of the taggings as well as compare other vectorizations like TF-IDF and GloVe. We’d also like to explore embeddings augmented with menu item features such as price and photos.
Questions or discussion? Interested in working at Caviar? Drop me a line at [email protected] or check out jobs at Square!
Authored By



