
Caviar’s Food Recommendation Platform
By Christopher Skeels
Intro
At Caviar, Square’s food ordering app, one way we connect diners with great food is our home feed of recommendations. We have a large variety of recommendations to make, and we want to constantly test and evaluate them. To support this, we’ve created a flexible, powerful recommendation platform using our knowledge of great food and local markets. We want to do for food what companies like Netflix and Spotify have done for movies and music. In this post, I break down the design and highlight the most interesting features of the platform.
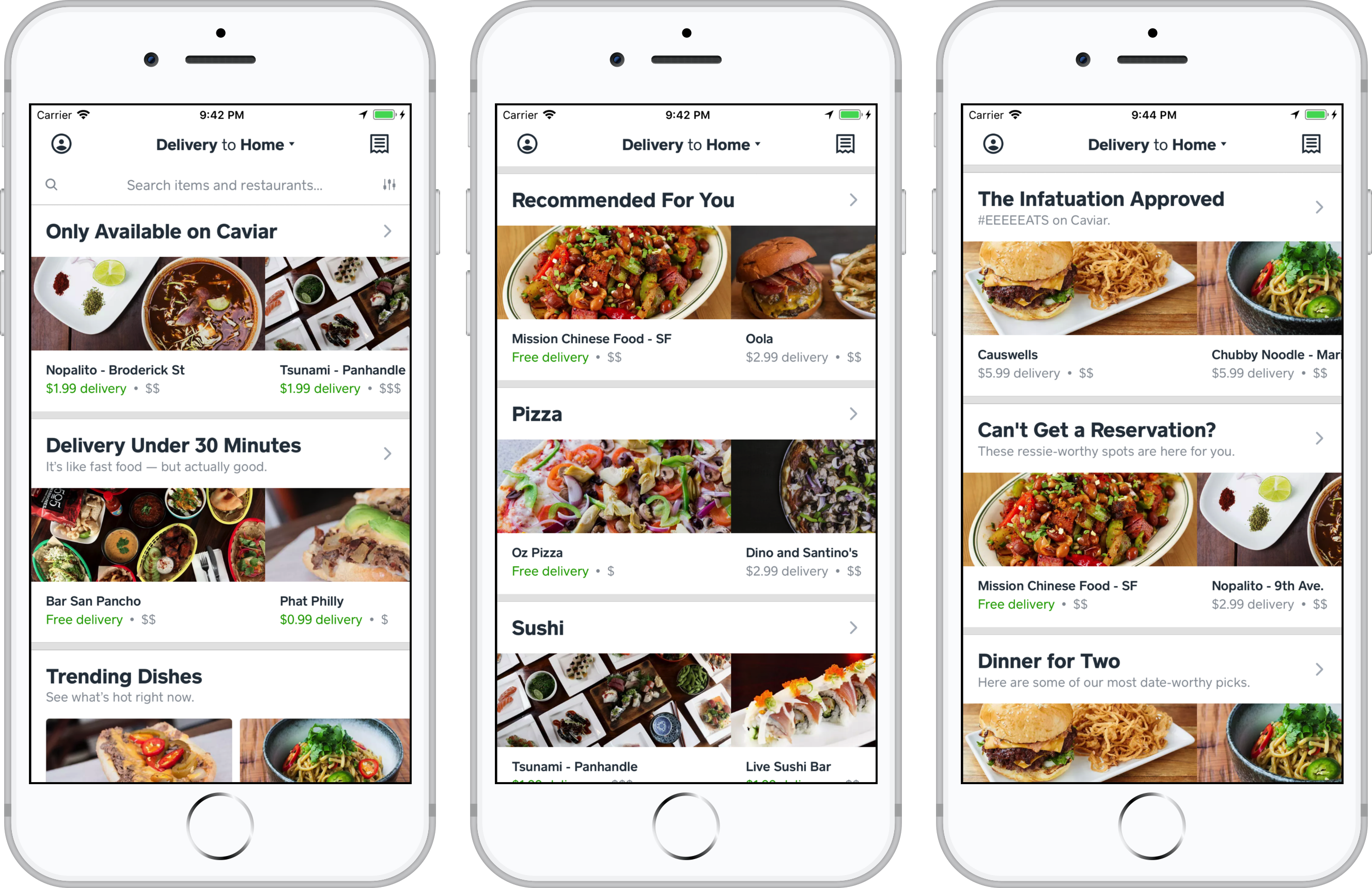 Caviar’s home feed of recommendations.
Caviar’s home feed of recommendations.
Recommendation Collections
Fundamental to our platform design is the concept of a recommendation collection. Rather than presenting a single overwhelming stream of recommendations, we segment them into distinct collections, each characterized by a common theme and powered in various ways. While the term “recommendation” is often used by others as shorthand for “machine-learning-generated recommendation,” we take a more liberal view by treating a recommendation as any suggestion we make to our diners regardless of human or machine sourcing.
We find that no one type of recommendation performs equally well for all diners. For example, while our more advanced machine-learning-based “Recommended For You” collection performs well, so too does the simpler “Order Again” collection, which just shows the restaurants you’ve ordered from before. Similarly, the “Delivery Under 30 Minutes” collection based on past restaurant performance analytics does best by catering to diners wanting fast options. For diners with classic tastes, simple categorical collections like “Pizza” and “Chinese” are popular. Finally, human-curated collections like “The Infatuation Approved” perform well with diners because of the as-of-yet-not-automatable expert aesthetic tastes and branding they contain.
As these examples show, there are many ways recommendation collections are powered including machine learning, custom algorithms, category taggings, and curated lists. Collections are additionally characterized by whether they recommend restaurants or menu items, how their recommendations are sorted for display, which diners they are shown to, and in what order each collection appears in the home feed. The platform supports this level of variation and functionality by being both pluggable (similar to plugin systems like Google Chrome browser extensions and Adobe Photoshop image filters) and configurable (similar to content management systems like Drupal and Wordpress). The following diagram highlights the important pluggable and configurable components:
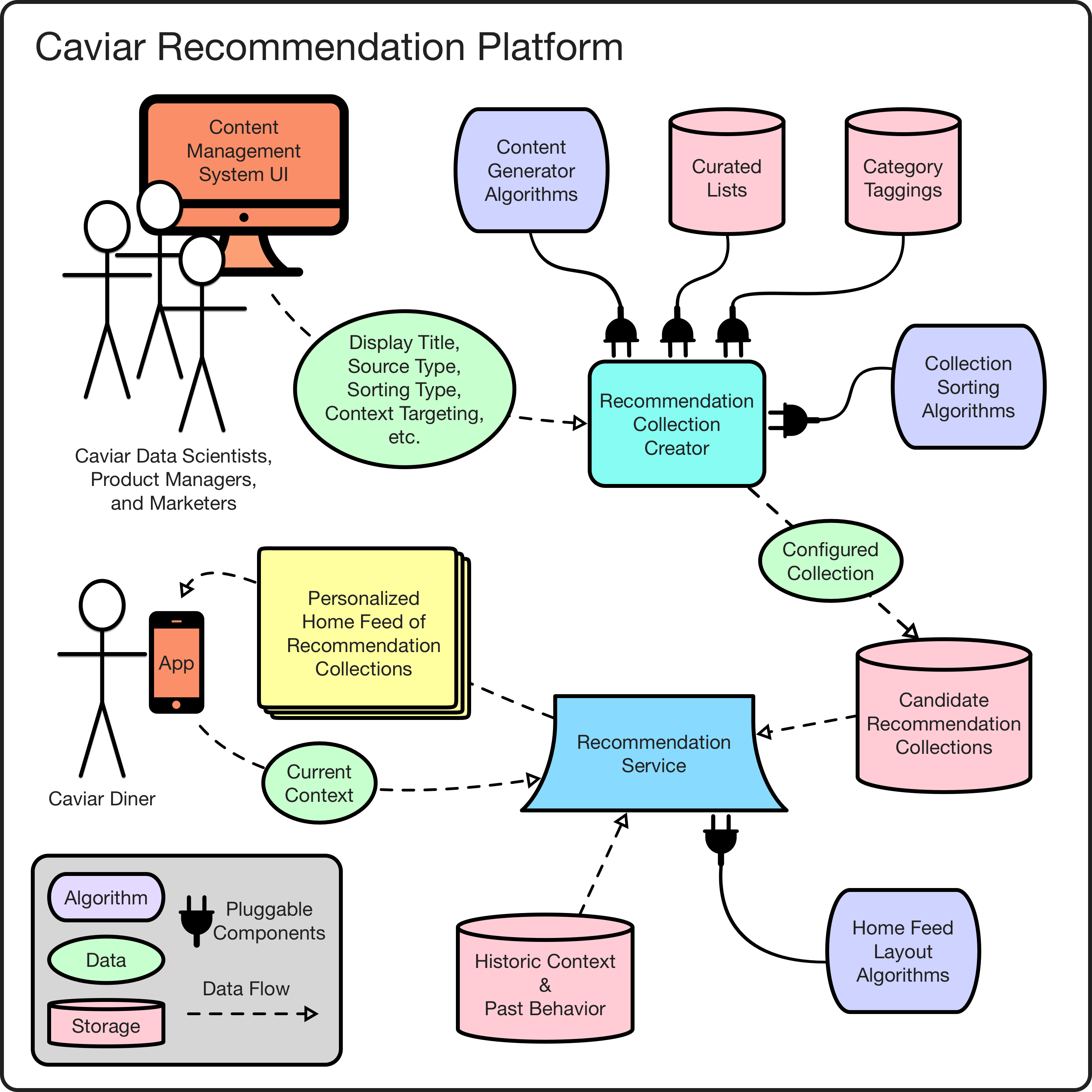 Overview of configurable and pluggable platform components.
Overview of configurable and pluggable platform components.
Collection Source Types
The platform allows for recommending collections to be powered in different ways through the use of pluggable collection source types. This abstracts away the underlying source of the collection content from the home feed processing pipeline. As long as the collection implements the expected interface, it can be used in the home feed, leveraging all the features and services of the platform for little extra development cost. We currently support three collection source types (curated, categorical, and algorithmic) but could easily expand to more thanks to this pluggable approach.
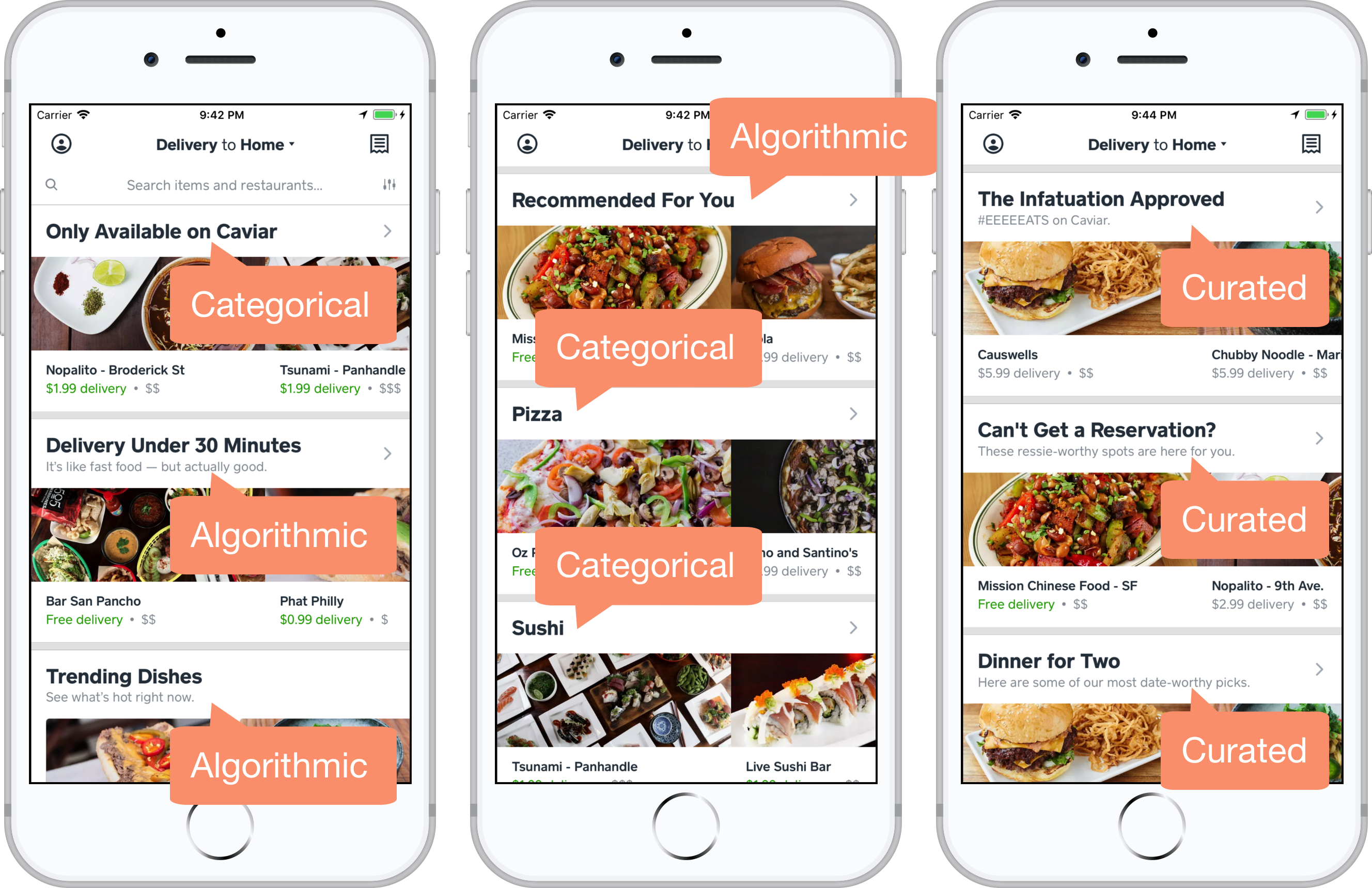 Collection source type examples.
Collection source type examples.
Curated collections leverage our knowledge of food and local markets by allowing Caviar staff to hand-create themed recommendation lists. In general, these aren’t as scalable as categorical and algorithmic collections, but that’s okay since we use them primarily for niche collections that are hard to automate or only run for a limited time period, e.g., “This Weekend’s Pop-ups”, “Valentine’s Date Night At Home”, and “Oakland Restaurant Week”. A curated collection is created with the platform’s content management system UI (which we talk more about later) by manually picking the desired restaurants and menu items.
Categorical collections are a simple yet powerful way to segment content via categories such as cuisine type, menu item type, and dietary restriction. Example collections include “Chinese”, “Tacos”, and “Vegetarian”. Content can be tagged with relevant categories both manually and via automation. See Caviar’s Word2Vec Tagging For Menu Item Recommendations for an example of automation with machine learning. A categorical collection is created via the content management system UI by choosing a category from a list.
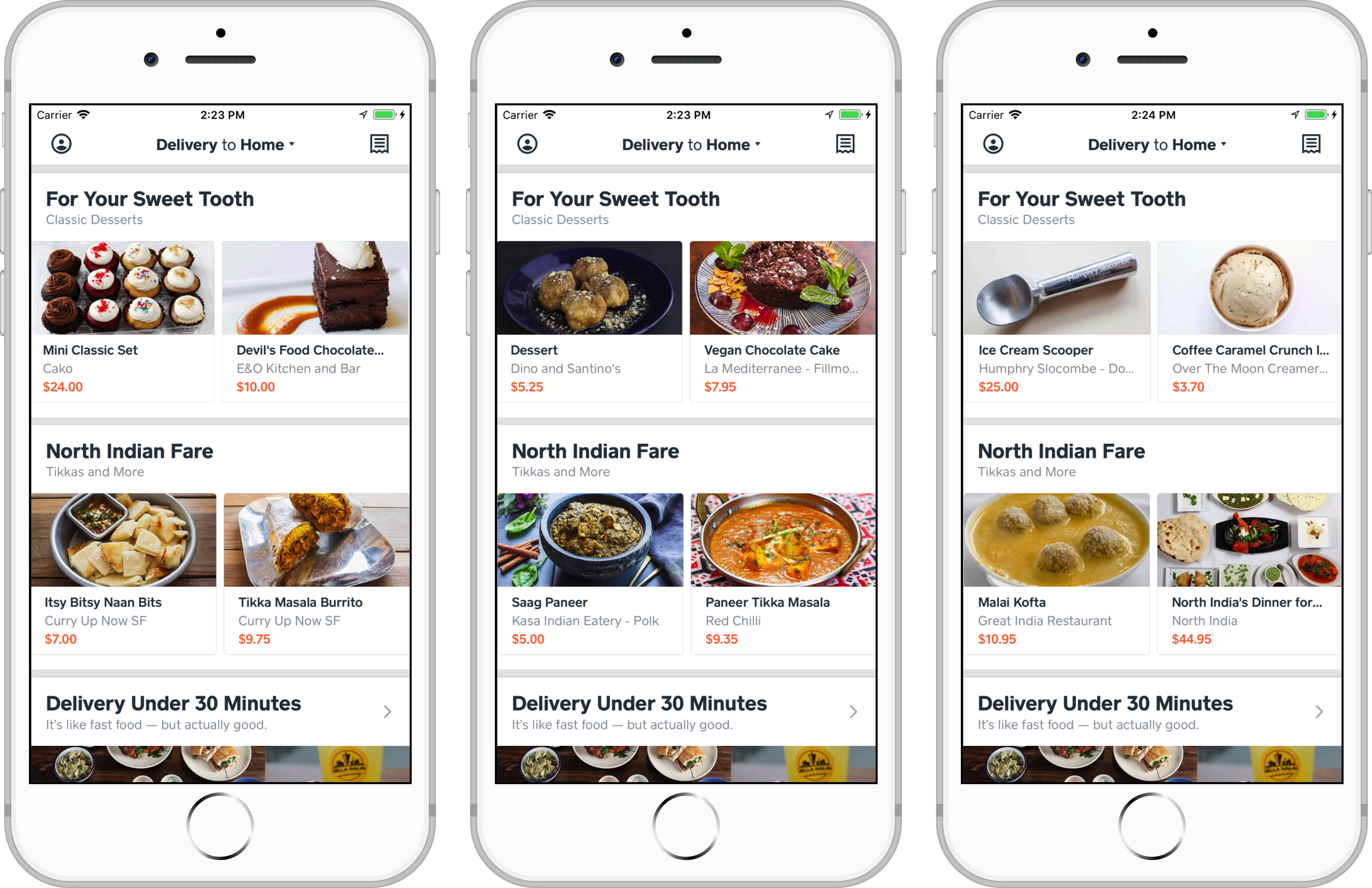 Automated categorical collection examples from related post “Caviar’s Word2Vec Tagging For Menu Item Recommendations”.
Automated categorical collection examples from related post “Caviar’s Word2Vec Tagging For Menu Item Recommendations”.
Algorithmic collections are our most advanced type. With these, any algorithm we can dream up for generating recommendation content can be packaged as a recommendation collection. Algorithmic collections allow us to scale recommendations to all markets beyond just those where curation is readily available. An algorithmic collection is created with the content management system UI by associating it with a content generator algorithm.
Content Generator Algorithms for Algorithmic Collections
Algorithmic collections use pluggable content generator algorithms to provide their recommendations. Content generator algorithms are made pluggable by implementing a simple get_recommendations(context) interface that returns recommendation results in the format expected by the platform. How algorithms go about generating those results is encapsulated away from the processing pipeline at runtime. The following examples show the variety that this pluggable approach allows:
-
The “Recommended For You” algorithm uses a hybrid content-based and user-based similarity recommender system to suggest restaurants.
-
The “Delivery Under 30 Minutes” algorithm selects restaurants capable of meeting the delivery promise for a given diner.
-
The “Pickup Under $15” algorithm selects popular restaurants that have numerous entrees under the price limit.
-
The “Trending Dishes” algorithm highlights popular menu items from the past week.
-
The “Free Delivery” algorithm checks a complex set of business rules to determine all the restaurants that will deliver for free to a given diner.
Content generator algorithms can be one of two subtypes: pre-generated or real-time. Pre-generated algorithms perform their content generation offline via periodic background jobs. This subtype implements an additional generate_recommendations(storage) interface that knows how to generate and store its recommendations and its get_recommendations(context) implementation then just becomes a fast, direct retrieval from storage. The platform abstracts the concrete storage technology away from the algorithm by providing generate_recommendations(storage) a simple key-value-store-like interface to use via the storage parameter. This gives us flexibility to use relatively cheap/slow options like Postgres or expensive/fast options like DynamoDB as appropriate. Pre-generated algorithms are preferred because almost any interesting algorithm will be too slow to run in real time, and even for algorithms fast enough for real time, pulling from pre-generated results will generally be even faster.
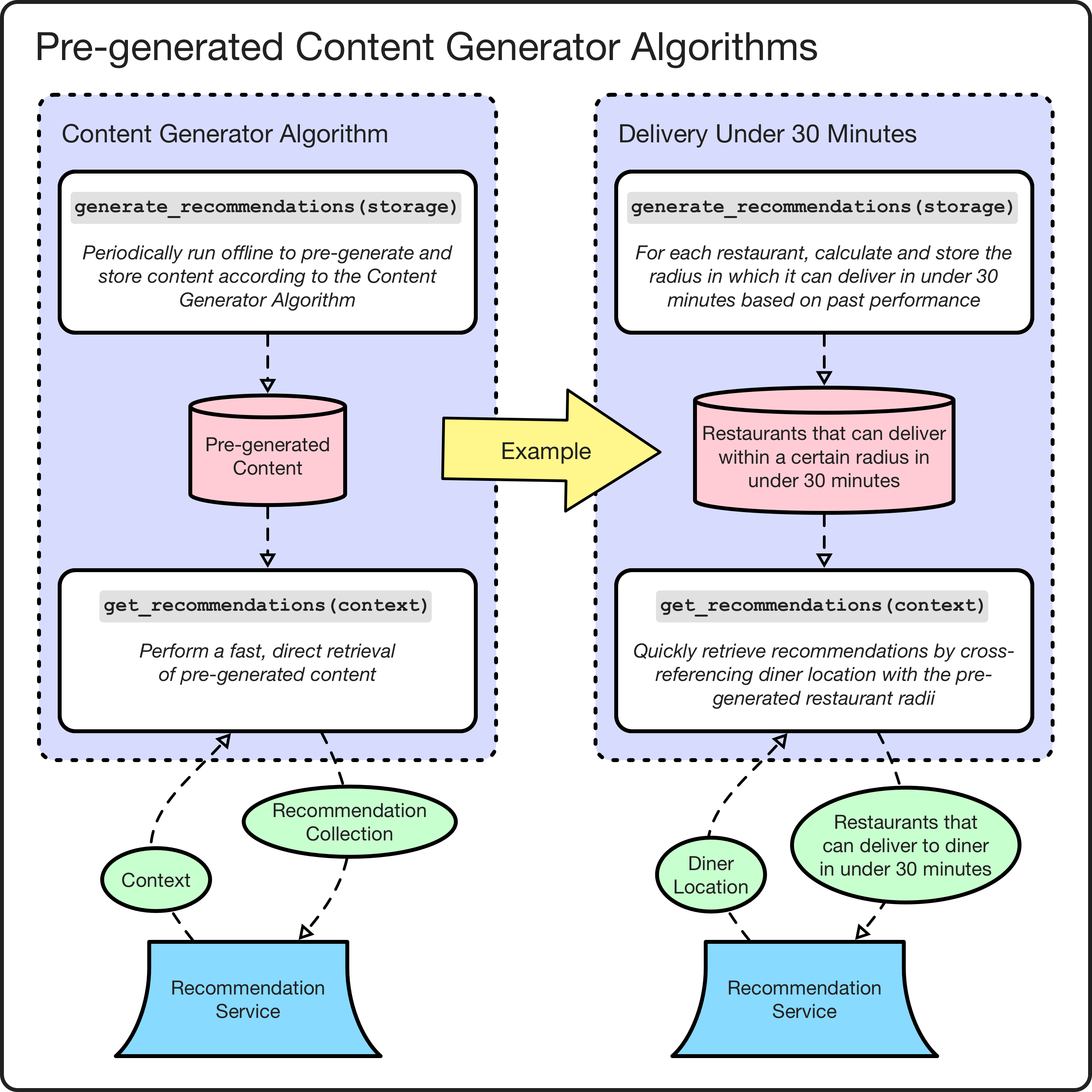 Pre-generated content generator algorithm examples.
Pre-generated content generator algorithm examples.
Real-time algorithms perform their content generation dynamically in real time and only implement the get_recommendations(context) interface. These serve as a fallback for algorithms that cannot be pre-generated due to needing immediate context like user location or where the effort to implement as a pre-generated algorithm is too costly. Typically, real-time generated algorithms are used to wrap existing legacy and third-party recommendation sources that already run in real time. Eventually, whenever possible, we migrate them to pre-generated algorithms.
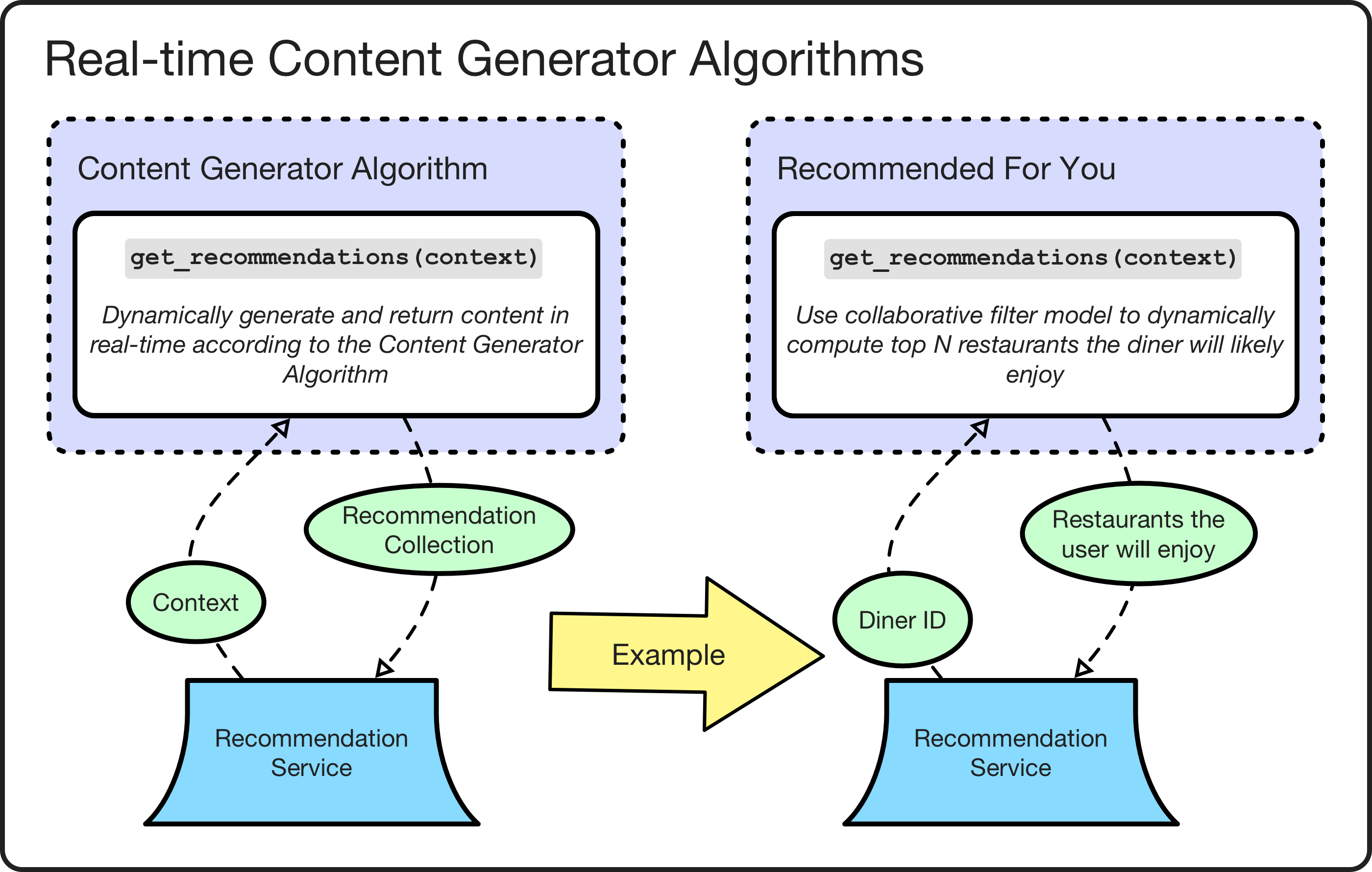 Real-time content generator algorithm examples.
Real-time content generator algorithm examples.
Recommendation Content Types
Our platform currently recommends two types of content: restaurants and menu items. We’d like to easily add new content types in the future as well. The platform supports this variation by abstracting away the underlying content type from collection processing. Collections are selected, filtered, and sorted without explicit reference to the collections’ content type by the processing pipeline. The content type is only ever used downstream so that collections of different types can be visually stylized differently.
 Recommendation content type examples.
Recommendation content type examples.
Diner Context and Targeting
We personalize the home feed by providing the platform a diner context, i.e., we provide it everything we know about the diner that will be helpful in selecting the best recommendations for them. This context includes a combination of real-time and historic information. Real-time context includes information like location, current time, and device type. Historic context includes information like sign-up date, number of previous orders, and cuisine category ordered from most.
One key way we configure collections is via targeting options related to diner context. This targeting is used when selecting a candidate set of collections to show in the diner’s home feed. For example, a “Happy Hour” collection of appetizers would be targeted to show only to diners when their current time is between Monday-Friday, 4–7pm. Similarly, we might target a “Popular” collection to new diners while targeting a “Recommended For You” collection to veteran diners for whom we have lots of ordering history.
For collections that make it past the targeting step, a second way that context is used is to populate the content for individual collections. For example, a collection that gets its content from a supervised machine learning model uses the diner’s context as input signals to an execution of that model. Similarly, a “Free Delivery” collection uses the diner’s location to determine the restaurants where the diner qualifies for free delivery.
There are also actions that all collections must take based on context such as capping the number of content items to generate depending on the diner’s device or screen size. For example, we show a maximum of 20 recommendations per collection to diners using the mobile app but a maximum of 50 to diners using the larger-screened web app.
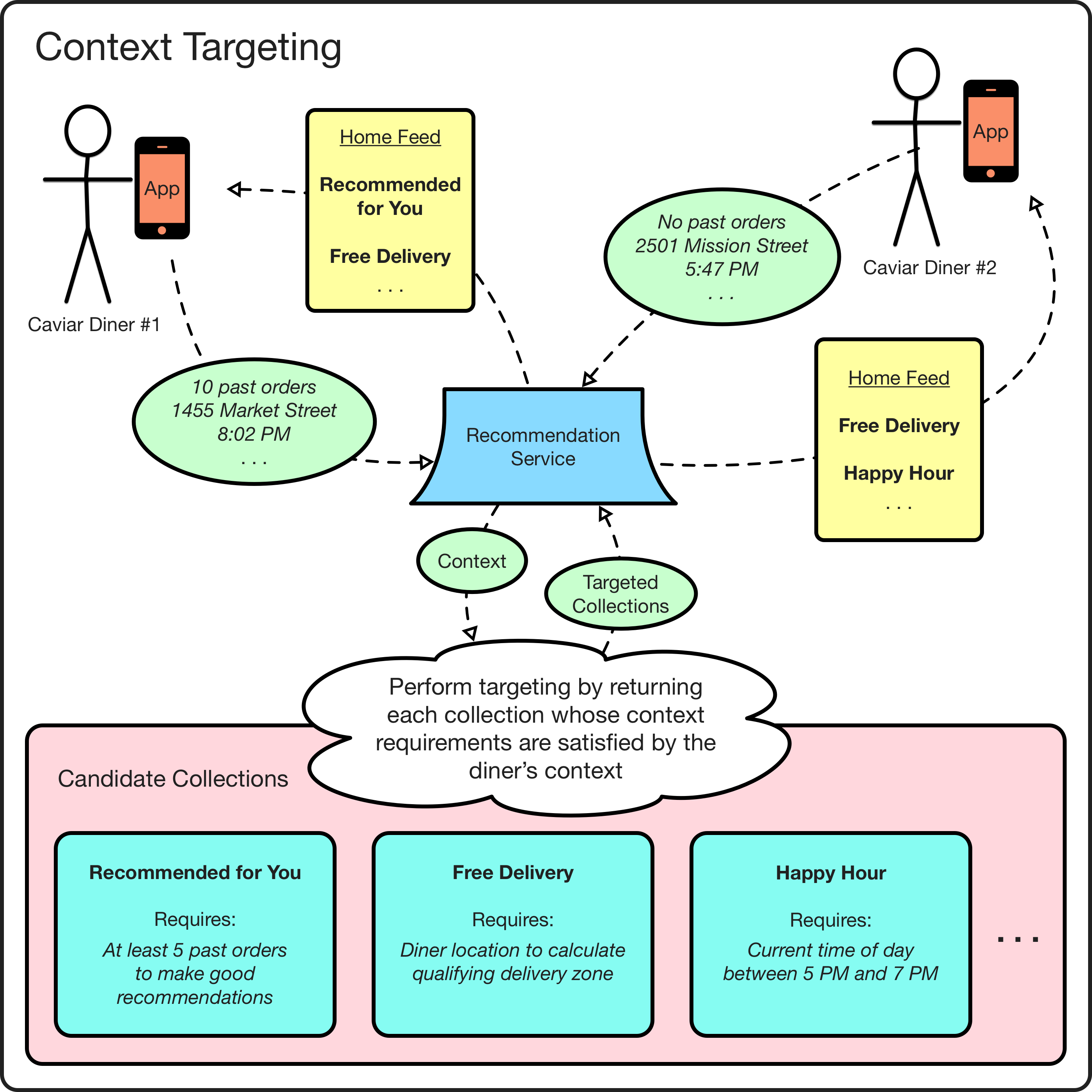 Using personalized targeting to populate a diner’s home feed.
Using personalized targeting to populate a diner’s home feed.
Home Feed Layout Algorithms
The platform is able to iterate on new home feed layouts by using pluggable layout algorithms, i.e., pluggable algorithms that determine what collections to show and in what order to show them relative to one another in the home feed. All layout algorithms follow the same basic steps:
-
Use diner context and configured collection targeting to select an initial candidate set of collections (as discussed in the previous section).
-
Pick and sort (relative to one another) a subset of collections from the candidate set that satisfies the algorithm’s objectives.
Since the candidate set is typically much larger than the maximum number of collections we want to show in the the home feed, layout algorithms differentiate themselves in how they perform Step 2 and how well they perform. For example, a random algorithm might pick a random subset of collections from the candidate set and then randomly sort these relative to one another. This algorithm would certainly not be our best performer, but it provides a great baseline for comparison. A fully automated algorithm might rank the candidate set of collections according to a machine learning model or heuristic and then pick the top *N *collections as its sorted subset. While this would perform much better, it would prevent from us curating the home feed and making direct use of our food and market experts. A third type of algorithm is a hybrid, curating certain vertical positions with pre-set collections while using a model-based ranking to dynamically fill out the rest of the vertical positions. This could perform competitively while still allowing us room to use our human expertise.
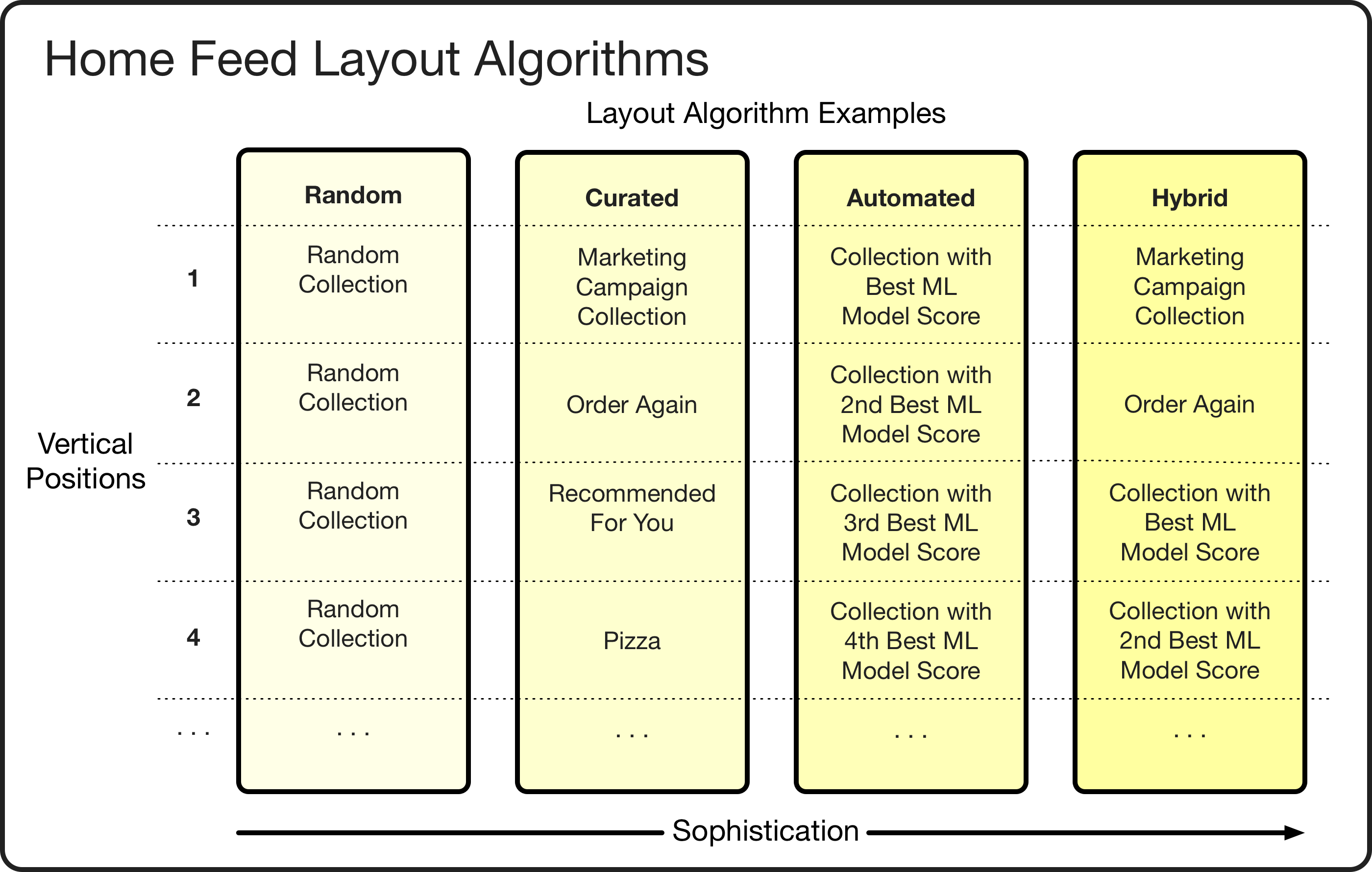 Home feed layout algorithm examples.
Home feed layout algorithm examples.
While the hybrid algorithm sounds plausible, it’s really an empirical question as to what algorithm is best. Even if a hybrid algorithm is the best, which hybrid? How many vertical positions can you curate before you are back to the notoriously poor-performing “informed gut” approach? With the evaluation enabled by pluggable algorithms, answering these questions is straightforward.
Relatedly, the “baseline” algorithm mentioned earlier is probably our best tool for answering these types of fundamental performance questions. First, by showing an unbiased, randomized layout occasionally to a subset of diners, we can establish a minimum performance that our regular algorithms must beat. Second, since every collection has an equally likely chance to show up in all vertical positions in the layout, we can calculate a global performance ranking that identifies our best collection, our second best, and so on. This helps pick which collections we invest in maintaining further. Third, since every vertical position will show all collections equally, we can calculate the relative value of each vertical position such that we know how much of a boost a collection gets from showing in the first vertical position versus the second and so on. This helps in budgeting vertical positions for lower-performing curated promotions and also suggests how many total collections to show in a layout before we see diminishing returns. Finally, when training machine learning models, the baselining data can be used instead of regular algorithm data to avoid the “rich get richer” effect where a collection shown at the top of a layout gets more clicks which leads to higher weighting in the model which, in turn, leads to more clicks ad infinitum.
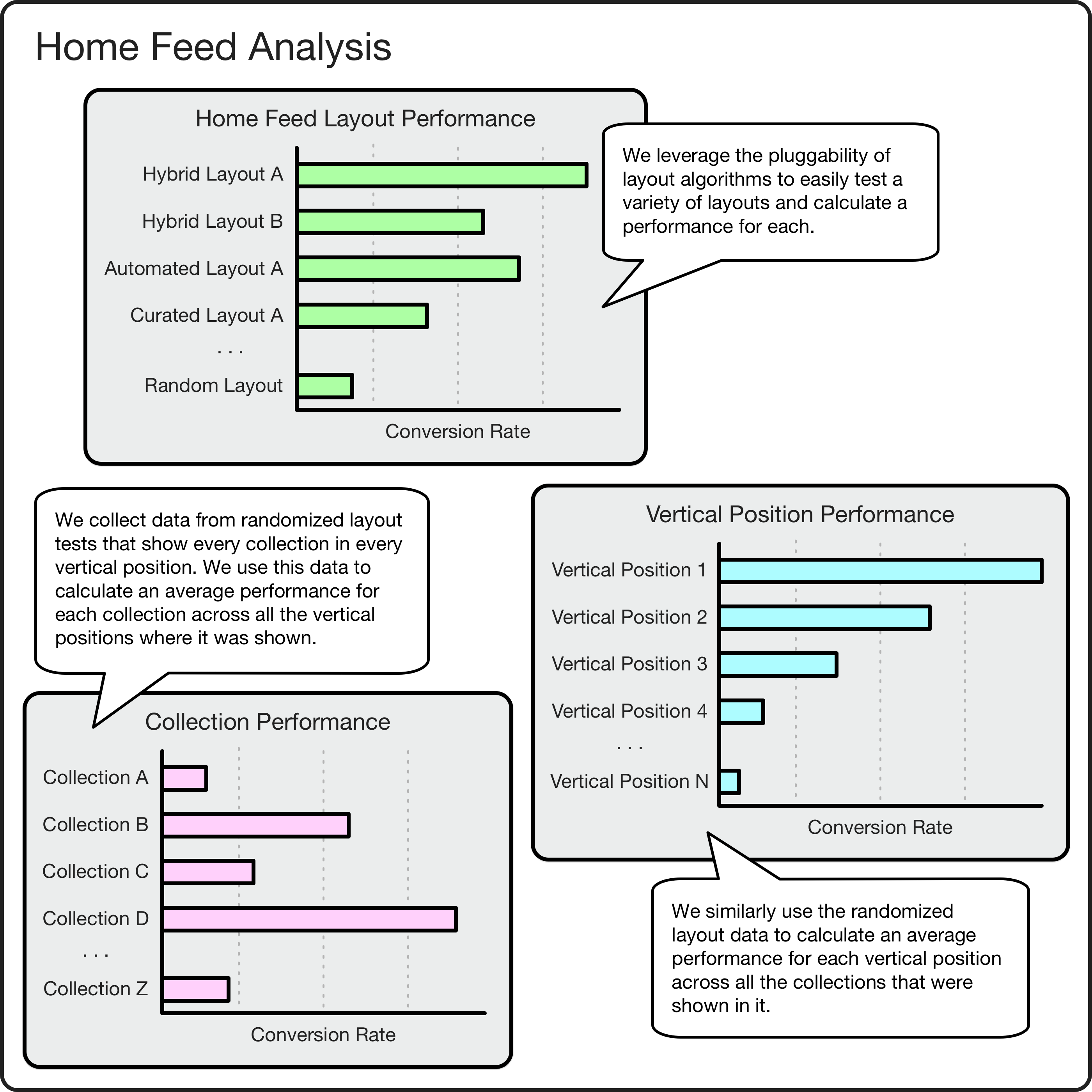 Home feed analysis enabled by pluggable layout algorithms.
Home feed analysis enabled by pluggable layout algorithms.
Collection Sorting Algorithms
The platform decouples the generation of a collection’s content from the sorting of that content by using pluggable collection sorting algorithms (not to be confused with the cross-collection sorting performed by home feed layout algorithms in the previous section). Similar to content generator algorithms, sorting algorithms are made pluggable by implementing a sort(context) interface that returns a list of sorted recommendations. Pluggable sorting algorithms provide a number of benefits. First, they provide flexibility and composability by decoupling the generation of collection content from the sorting of that content. For example, we can personalize a curated collection by sorting it according to a machine learning model score, or alternatively, we can use a machine learning model such as a collaborative filter to generate a collection’s content but sort it by a simpler contextual metric like estimated time of delivery. Second, similar to the cross-collection baselining in the previous section, pluggable sorting algorithms make it straightforward to baseline the performance within a single collection. For example, we could compare a baseline “by random” sort of the content to better sorts like “by ETA”, “by popularity”, or “by machine learning model score”. Third, pluggability allows our human experts to make ad hoc sorting changes via the content management system UI. For example, when we noticed that a new model-based sort was not weighting distance high enough, we easily reconfigured the collection to use a distance-only sort while we debugged the model’s weightings.
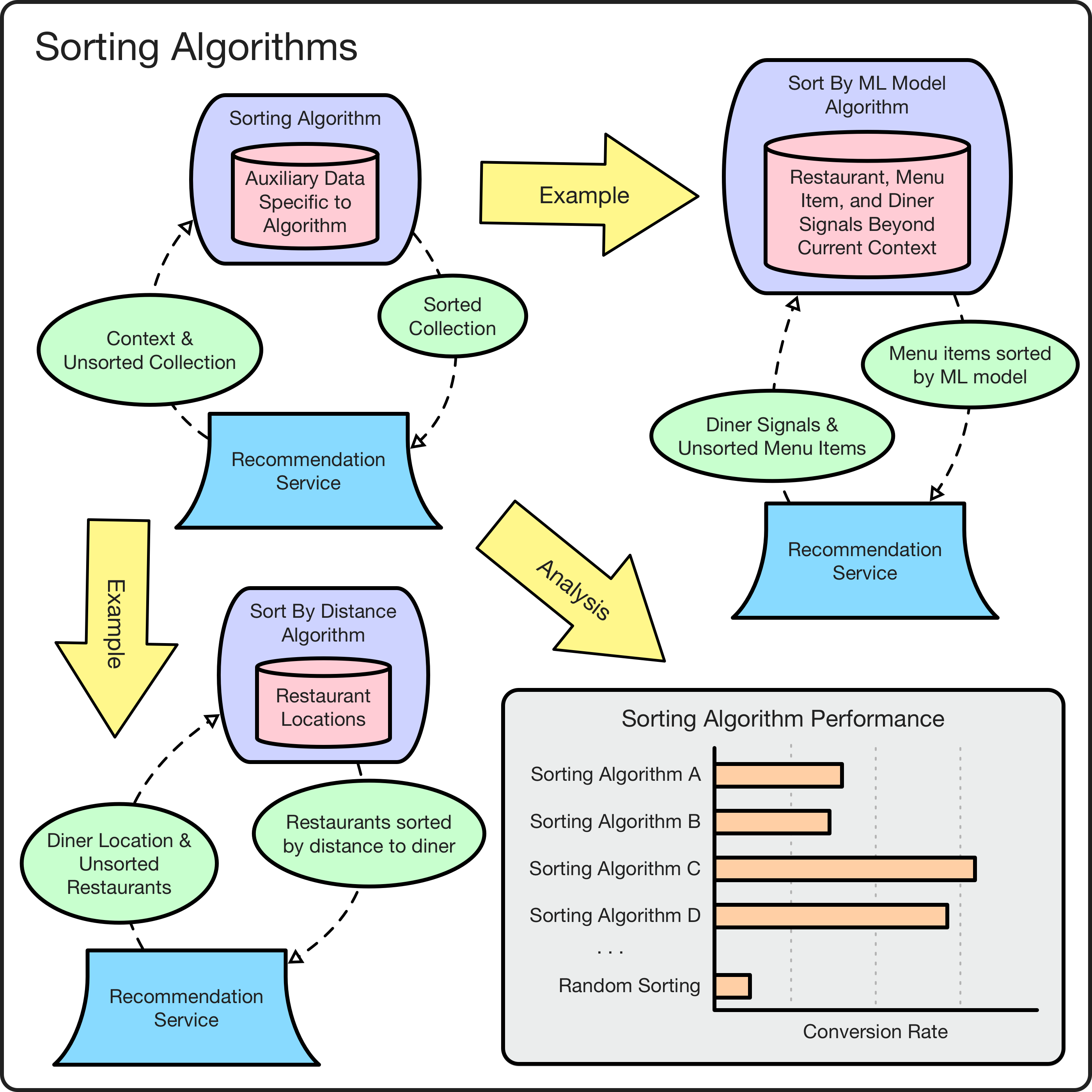 Sorting algorithm examples and analysis enabled by pluggability.
Sorting algorithm examples and analysis enabled by pluggability.
Content Management System
The platform provides a content management system to create and configure recommendation collections, content generator algorithms, and sorting algorithms. This approach makes it possible to iterate in a number of ways without requiring new code or engineering assistance. For example, a collection’s title and subtitle can be iteratively wordsmithed by brand copywriters. Similarly, a collection’s sorting algorithm can be iteratively evaluated by data scientists and product managers. Finally, a curated collection’s content can be iteratively updated by local market experts.
Creating/updating a collection consists of setting:
-
Display information such as title, subtitle, and visual style.
-
Targeting information such as geographical region, diner characteristics, and past diner behavior.
-
Collection source type and associated parameters such as the category for a categorical collection or the pluggable content generator algorithm for an algorithmic collection.
-
Recommendation content type such as restaurant or menu item.
-
Other behavioral modifiers such as a pluggable sorting algorithm.
Creating/updating a content generator algorithm or sorting algorithm consists of setting:
-
Friendly description for display in the related drop-down box in the collection creator.
-
Path to the implementing code package.
-
Recommendation content type that can be used with this algorithm.
-
Behavioral modifiers such as if a content generator algorithm is pre-generated or real-time.
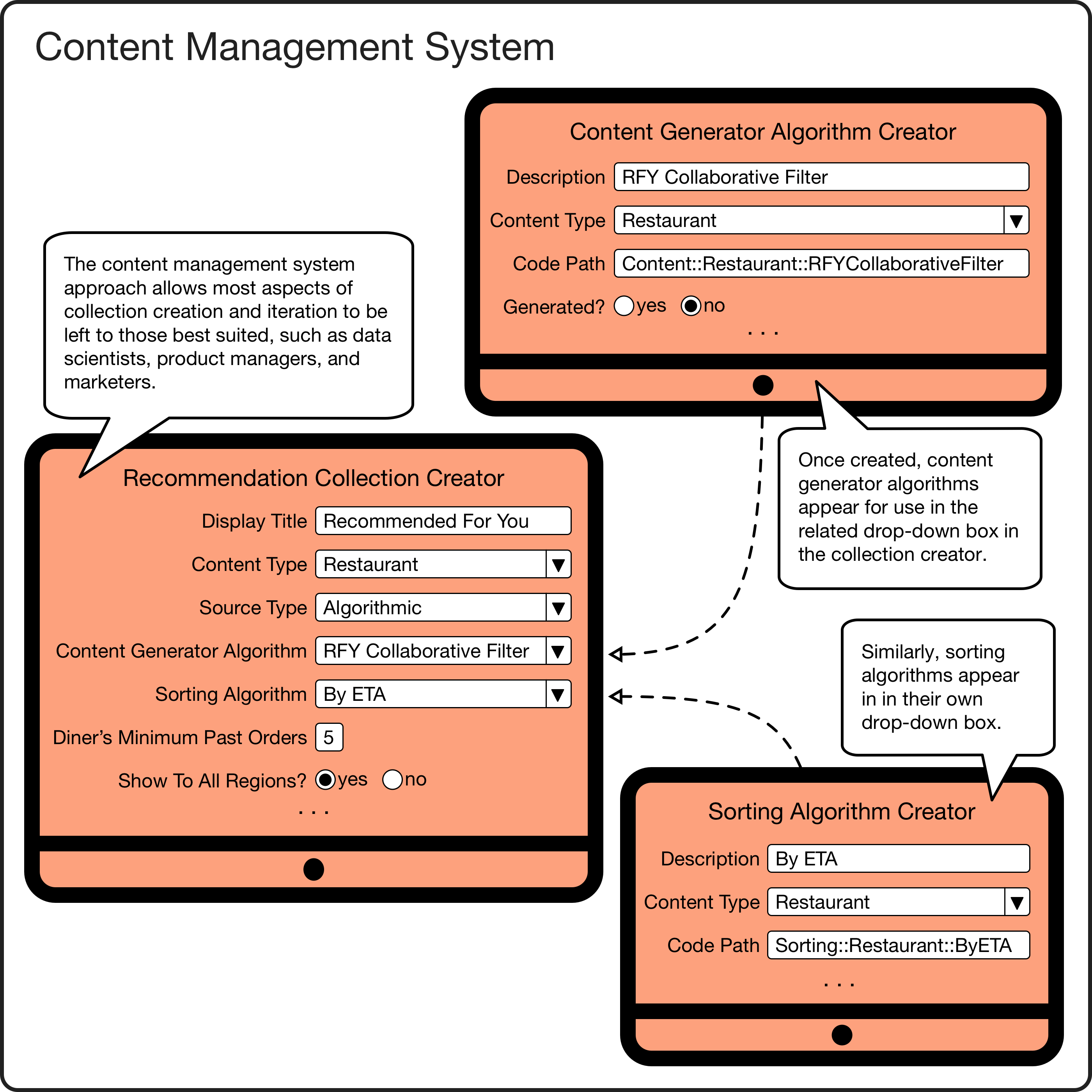 Content management system examples.
Content management system examples.
Wrap-up
The recommendation platform primarily derives its flexibility and power from a few key features. Its pluggability supports rapid iteration and testing. Its configurability and content management system supports a more sensible division of labor between engineers and key non-engineers. The various collection source types, content types, content generator algorithms, and sorting algorithms can be recombined in many ways to suit the diverse tastes and needs of our diners. By combining all these, the recommendation platform excels at its job of connecting our diners with great food.
Beyond the Caviar home feed, there are natural additional applications of the platform that we’d like to explore such as powering personalized email campaigns and powering our corporate group ordering and catering products. Be on the lookout for future posts on these topics.
Questions or discussion? Interested in working at Caviar? Drop me a line at [email protected] or check out jobs at Square!
Authored By



