
Caching E-Commerce Data for The Web
On the effectiveness of Cache Tags and caching layers
The catalog service
The Square Online catalog service provides all the catalog data for the websites we power. This includes products, categories of products, store locations, and many others.
While some catalog data is fairly simple to present in an API response, other parts are more costly to calculate. The price of a product, for example, comes from many sources: SKUs (think a Small vs. Large shirt), modifiers (would you like cheese on your burger?), and location-based pricing, which gives sellers the ability to set different prices at different locations.
As we continue to add more controls to how merchants sell and price their products, response times for what was initially a simple API have been steadily increasing. To help the clients get all the data needed in a single request, we allow inclusion of related data on most endpoints. For example if you wanted to get a list of all products including images, variations, modifiers, locations, and categories, we can craft a query string on our product endpoint that looks like:
?include=images,options,modifiers,categories,delivery_locations,pickup_locations
Performance
In spring of 2019, retrieving a list of products from the products endpoint could take anywhere between 200ms and 500ms. This was barely okay, but clearly couldn’t support our future plans and additional features.
After a bit of profiling, we found two areas ripe for improvement. The first was, our serialization layer worked at the single object level, so for each object in the response, we were fetching the related includes one at a time instead of fetching them all for the full collection. This caused a classic N+1 query problem.
In addition, formatting the data for API output was costly. Finding the price range of a product now required joining at least 3 and potentially up to 5 DB tables. To reduce the cost of building the API response once we had a list of results, caching was the best option.
Object Response
The idea behind the object cache was to avoid the cost of fetching any related data and performing computation on availability, pricing, and fulfillment for a product. The result for each object in the API response should come pre-calculated.
Let’s take for example a request that would come in and result in a response that lists 5 products:

In between the controller and the transformer, the caching component would perform the following steps:

When we want to enable caching, the transformer now implements a Cacheable interface to retrieve the cache key:
interface Cacheable
{
public function cacheKey(Serializable $item) : string;
}
The actual implementation pulls multiple pieces of data together to create a unique cache key for this item. Simplified, it looks like this:
public function cacheKey(Serializable $item) : string
{
return implode(',', [
$item->id, // The item id
static::class, // Different transformer class for each API version
$this->cacheVersion,
$this->context->storeLocation->id,
]);
}
Here, cacheVersion is an incrementing number we can use when we need to change the format of the response and ensure we’re not retrieving any stale data. Once we have all the keys, it’s a simple call to Memcached, our distributed caching server, to retrieve all the values.
Implementing an object cache this way had multiple benefits for us. First, the cached value is reusable across multiple different requests. Regardless of what the client requests via the ?includes= param, we can get it from the same cached value without re-computing it. In addition, since this is not an HTTP cache, we’re not sensitive to random query string parameters being added to the URL.
Clearing the cache
The data we return is published on our customer’s websites and is read more often than it is written. However, the site owners have the ability to update their products, and can also receive orders that modify inventory. In those situations, we need to make sure that the value stored in cache is promptly removed or updated with the most recent information.
Here are the three iterations we built for our cache clearing system, with the last being the most stable and reliable.
Regenerating keys
In our first iteration, we were attempting to always keep a warm cache. Whenever an update would happen, we would find which keys were generated for this item and replace the values. This proved tricky because a single item could impact data under multiple keys. As we described earlier, a product can have different prices and inventory for each location where it’s sold. On top of that, a product can also have multiple fulfillment types. So code that started as a single loop for different API versions, soon became a series of nested loops trying to guess all possible ways in which an API response could include and generate the data for an item. It might be enough to implement initially but becomes harder and harder to keep up to date.
foreach ($apiVersion as $apiVersion) {
$data = (new SerializationTransformer($apiVersion))->transform($product);
// set the data in cache
}
Became more like:
foreach ($apiVersion as $apiVersion) {
foreach ($locations as $location) {
foreach ($fulfillments as $fulfillment) {
$data = (new SerializationTransformer($apiVersion, $location, $fulfillment))->transform($product);
// set the data in cache
}
}
}
Tags
Laravel, which is the PHP framework we utilize for this application, offers an implementation of cache tags. A way to associate additional keys (tags) with a cache entry and later use any of those additional keys to clear the cached value.
This is not something offered directly by Memcached, so it’s interesting to understand how it’s built. The interface for the Laravel implementation looks like:
Cache::tags(['product:1', 'user:2', 'location:3'])
->set('cache-key', $productApiData);
What would then be stored in Memcached is the following:
| key | value |
|---|---|
| products:1 | abc123 |
| user:2 | def456 |
| location:3 | ghi789 |
| cache-key:abc123:def456:ghi789 | $productApiData |
The following visualizations show how data is retrieved from the cache or stored in cache when tags are involved:
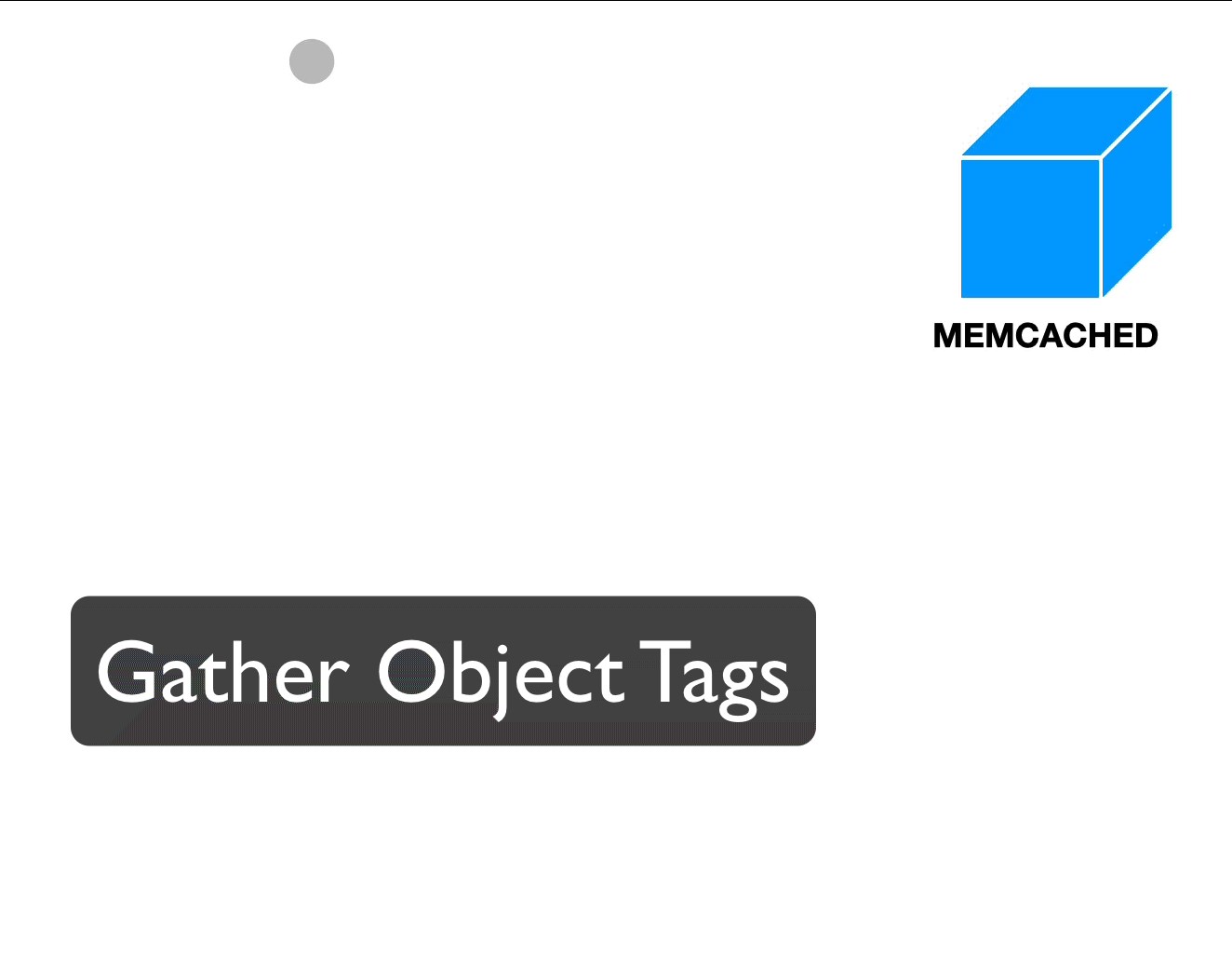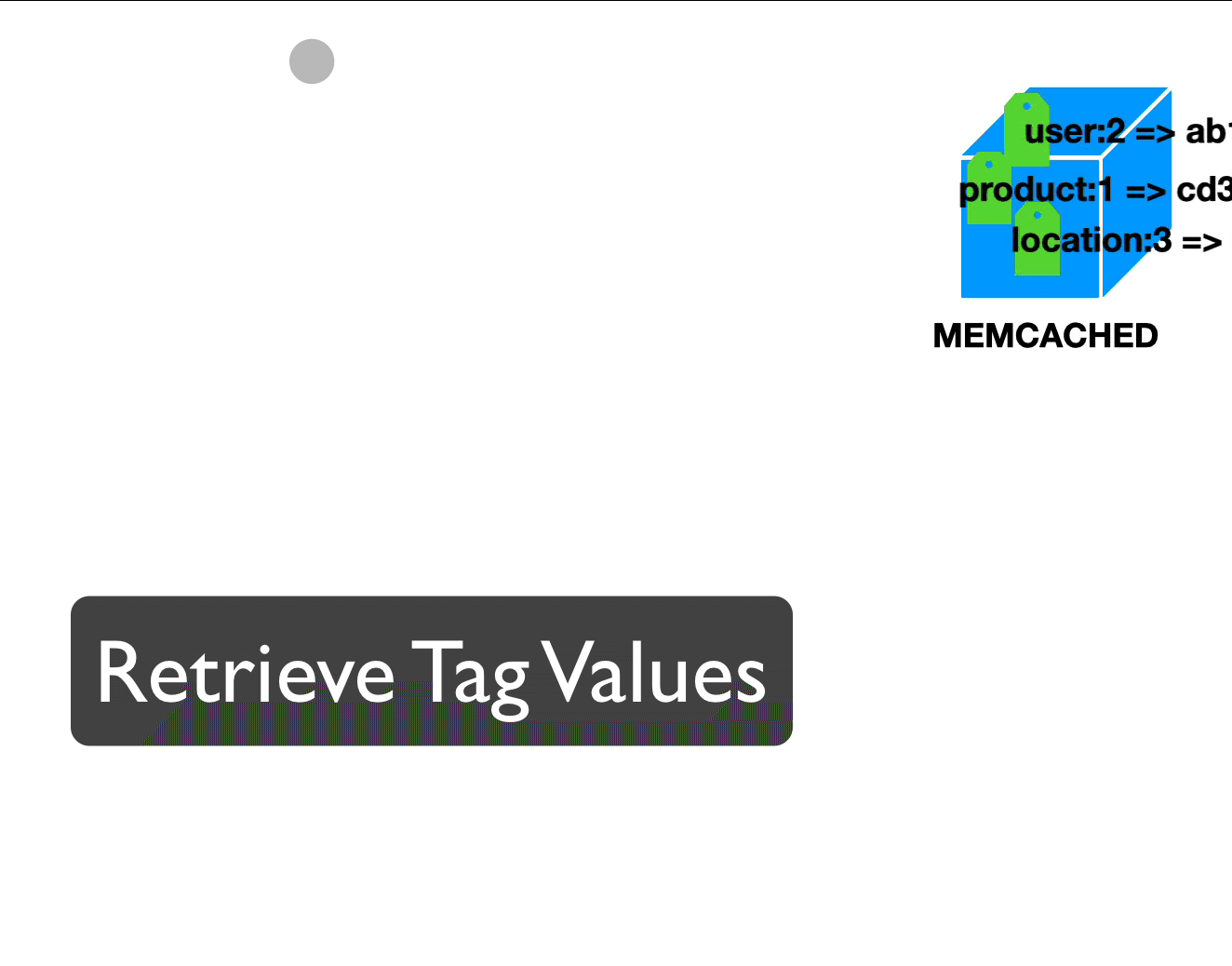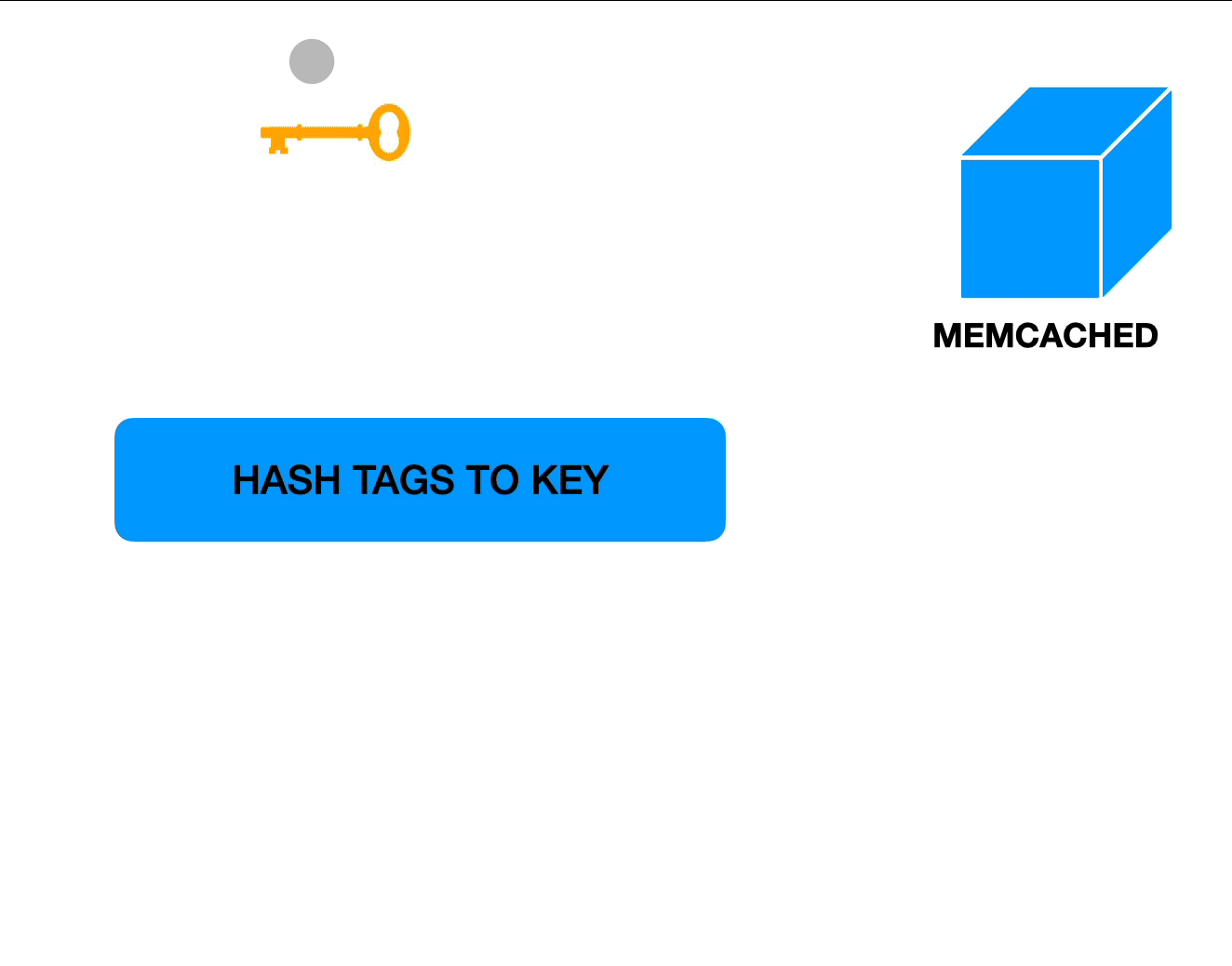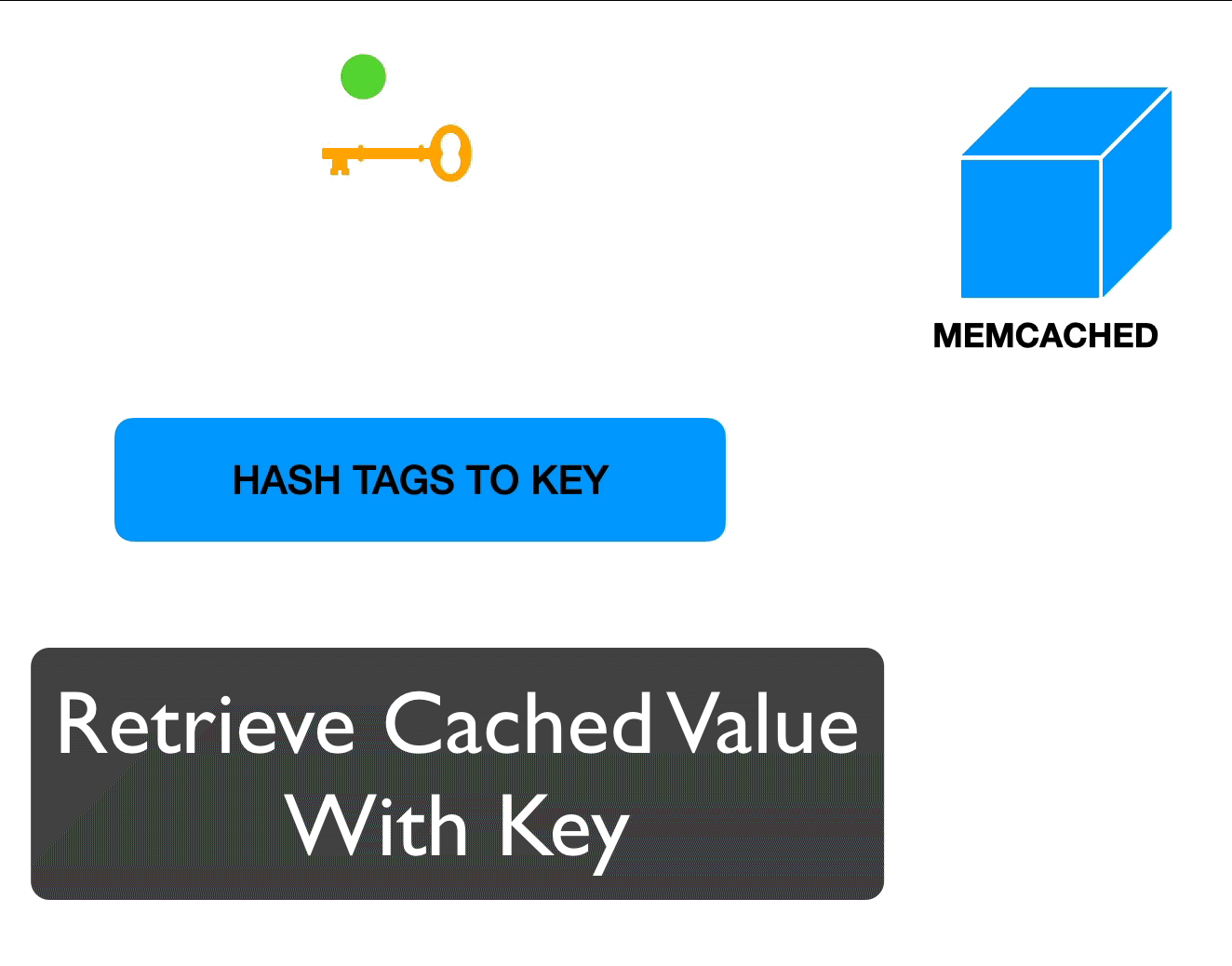
Tags and data available. Retrieving data.
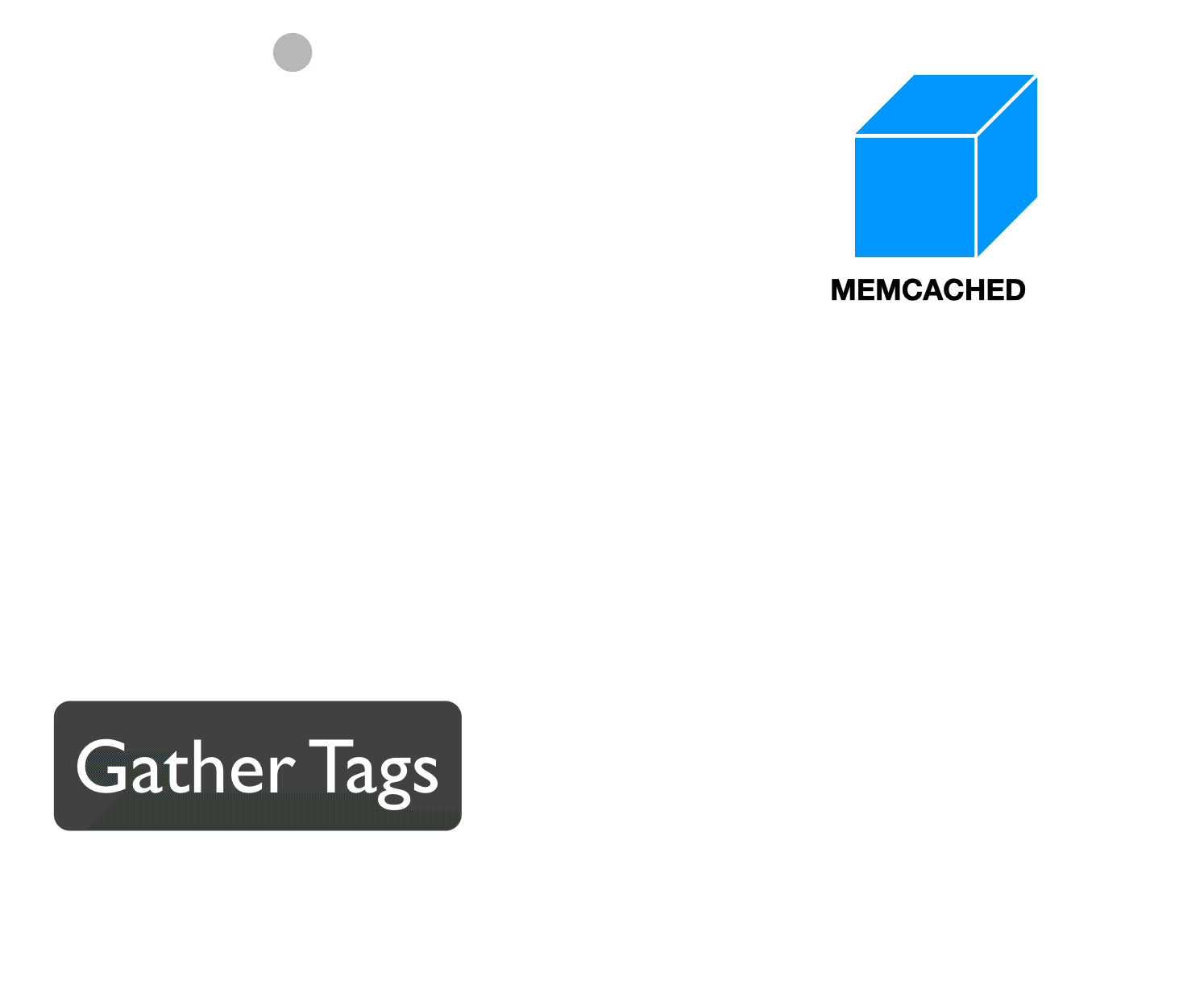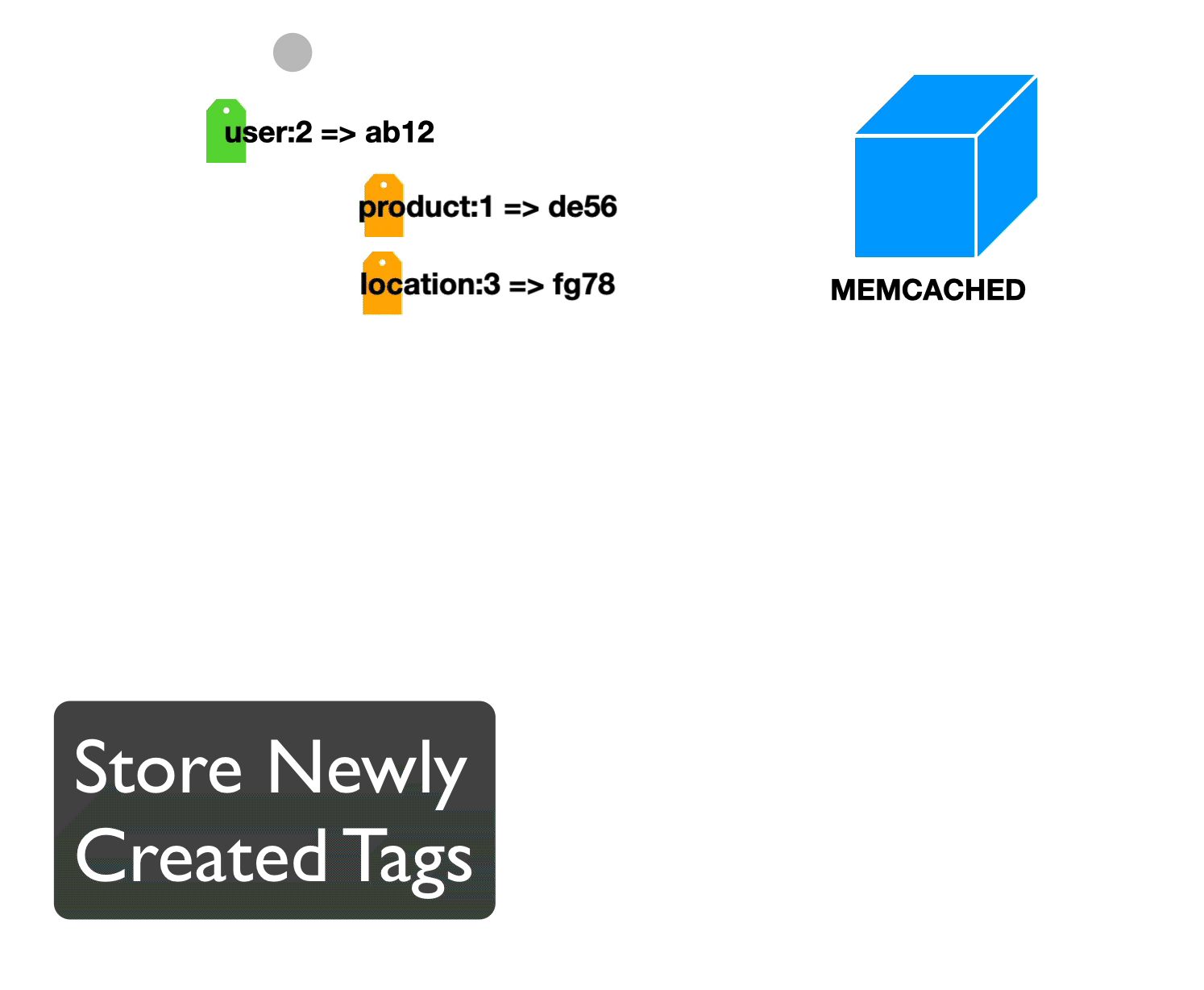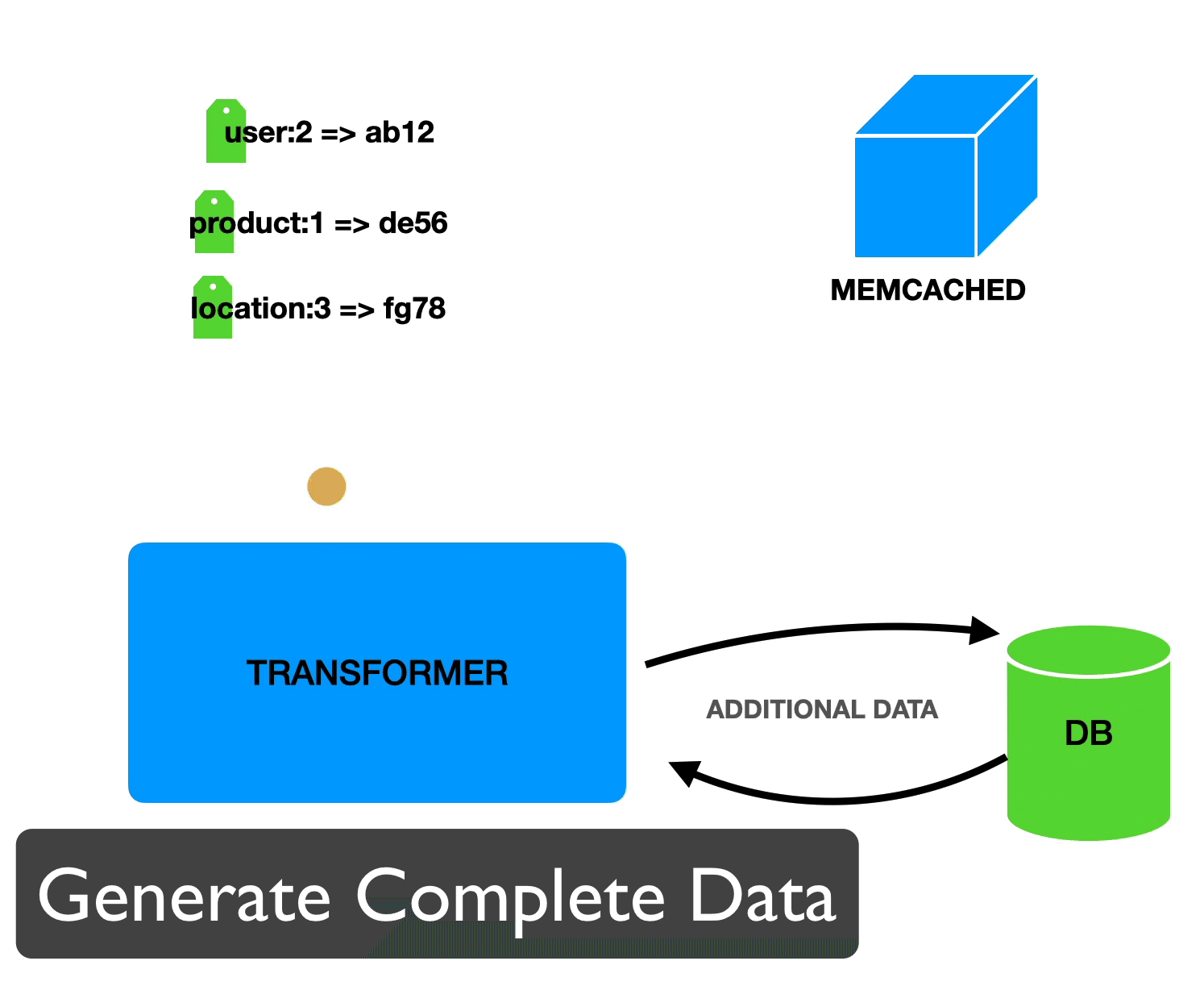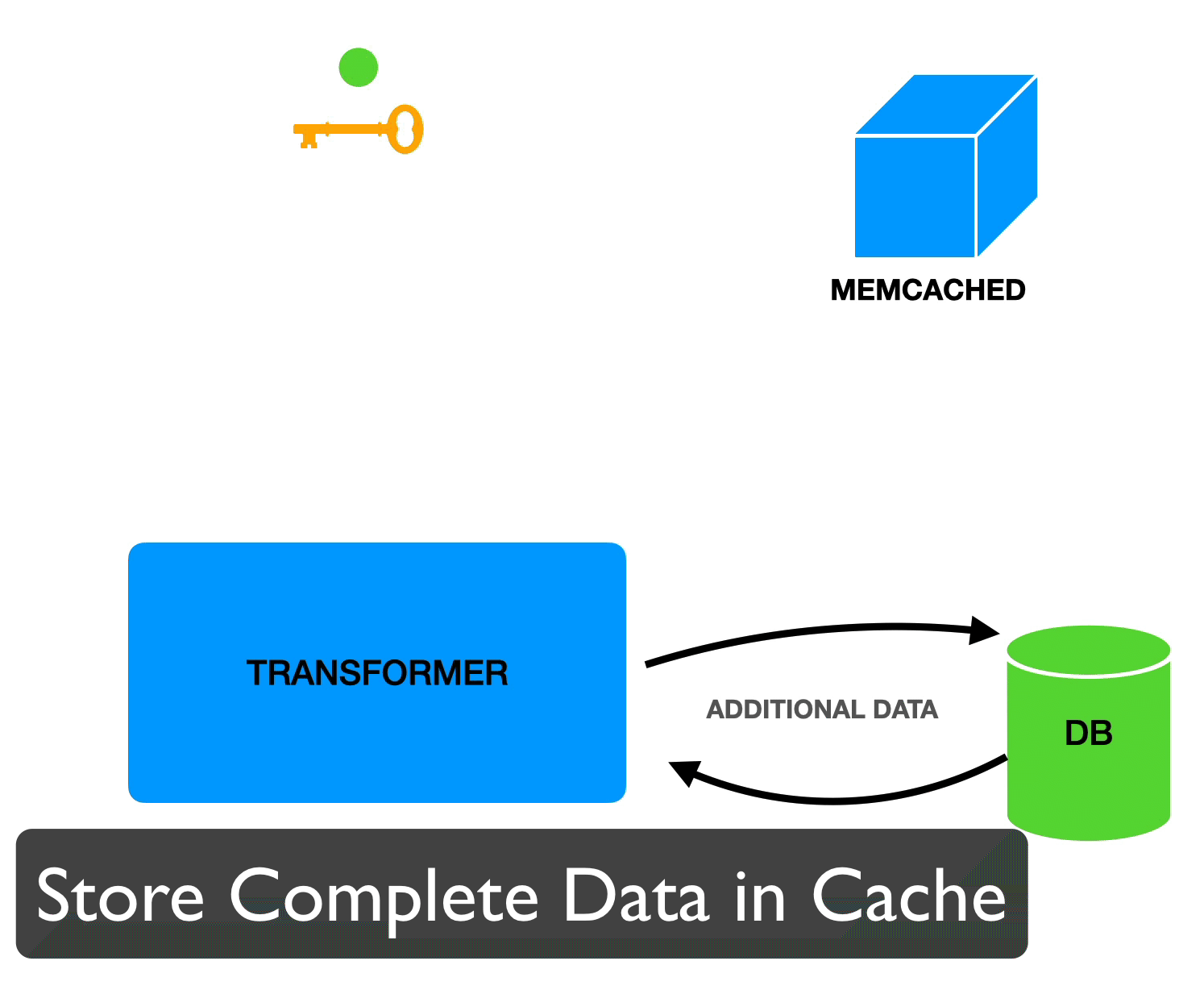
Some tags unavailable. Storing data.
For each tag defined in code, a random value is generated. By combining those values, we can re-create the key to find our data. Now, whenever we want to remove from cache any value that depends on the product with id 1, we just replace the value of that tag:
| key | value |
|---|---|
| products:1 | abc123 => d6a1ey |
| user:2 | def456 |
| location:3 | ghi789 |
| key:d6a1ey:def456:ghi789 | NULL |
When that value has been replaced, the new key we construct will have changed, and we’ll get a cache miss on the next request.
Laravel’s implementation of tags is so that for every tag, the framework will make a single request to Memcached to get its value. Since we wanted to use multiple tags per object and return hundreds of objects at once, that would mean over 1,000 calls to Memcached per request which would not speed things up.
We created our own version of Memcached-based tags, making sure to retrieve all the keys / tags we could in a single call. With this, we could retrieve all our cached objects in just 2 calls to Memcached:
- 1 call to get all the random values of the tags
- 1 call to get all the actual cached data
This worked great and we started adding all sorts of tags to our objects:
$tags = [
'id:09823861-23da-4d7f-bbe2-b47ba62d25c9',
'location:2ad819c2-c16d-4ecc-9de0-c1d004c40cdc',
'...',
'api_version:11',
'cache_version:1612931700',
];
We lived with this version of the cache for many months and it was mostly working as expected except once in a while, the hit rate would suddenly drop to zero. Since the cache then repopulated itself and response times improved within a couple minutes, we didn’t spend too much time investigating.
Balancing tags and key
With growth and increasing traffic, we eventually got to a point where one such cache loss one day brought us down for 10 minutes. Our current setup was unable to gracefully serve the traffic we received if we lost the entirety of our cache at once.
The issue turned out to be with tags like cache_version or api_version which were shared to almost every single one of our cached objects. If we overwrote that tag by mistake, or if Memcached decided to evict that key to make space for something else, we’d lose all of our cache in an instant.
We moved those values out of “tags”, but still made them part of the “key” to ensure the key was unique. This system was more stable, as we now have limited the blast radius of such occurrences so that at most, we’d lose the cache for a single user.
$tags = [
'id:09823861-23da-4d7f-bbe2-b47ba62d25c9',
'location:2ad819c2-c16d-4ecc-9de0-c1d004c40cdc',
'...',
];
$key = hash_key('api_version:11-cache_version:1612931700-...');
Results of the object cache
With this in place, our response times distribution shifted dramatically towards lower latencies (Y-Axis is number of requests, X-Axis is time in milliseconds):
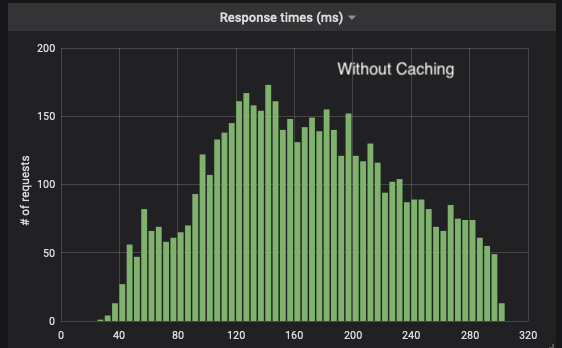
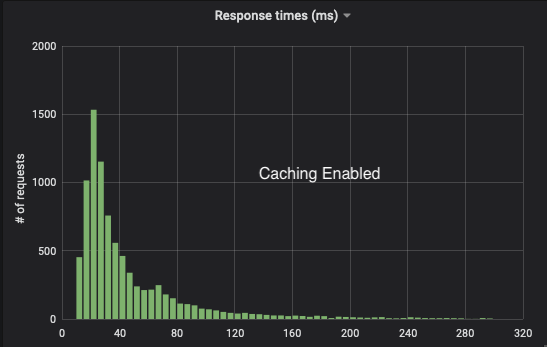
The hit rate we get usually sits between 93% and 96%.
Building a full response cache
With all of this in place, we were now in position to build upon it and start caching entire responses. This would mean no more database calls, as only a couple Memcached calls will be required to serve the full HTTP response.
Making this work requires a couple improvements and adaptations over what we had already built.
We start by receiving a request to one of our URLs such as: /users/123/products/456?in_category[]=1&in_category[]=6&includes=images,options,modifiers. Initially we don’t have a response in cache for that request and the response gets generated as usual. As we generate the response, we do the following:
- Get a list of products to include in the response
- Transform the product data for the API response
Preparing the data for the API response is done either by pulling it from the object level cache as described above, or by generating it and then caching it for each element of the response. In either case, as we gather the data, a list of tags was generated for each element of the response.
For the purpose of the full response cache, we collect all the tags that were generated. If any element of the response changes, and is cleared via one of its tags, a response containing that element will also need to be invalidated in the cache.
Now that the response is ready we have:
- The URL that was just called
- The response content
- The list of tags for all the elements that were included in the response
Unfortunately we can’t store this data in cache the same way we cached values for individual elements. We saw that the way we store individual elements requires us to have knowledge of the tags ahead of time in order to retrieve the data. However, when we receive a request and only know the URL, we don’t know what elements are going to make up the response and therefore don’t know what the tags are going to be. In this case, instead of building a dynamic key based on the tags and their current values, we can store the tags and current values along with the data:

This way, we can first retrieve the value based only on the URL and then verify that all our tags are still up to date.
An interesting benefit of this approach is that even when the data is stale, we still have access to it. This allows us to return that stale data fast and recompute up to date values in the background.
There is one last trap to avoid with this: an element that was not part of the response could still change the content of this cached response. For example, if I made a request to /users/123/products/456?price_max=45, that could return 3 items that are worth less than $45. When changing the price of an unrelated item from $200 to $20, I need to make sure that cached response gets invalidated, as it should now return 4 items.
We currently do this simply by adding a fairly generic tag like user:123:products to all responses that list products, and invalidating that tag whenever any of this user’s products change. While this is not a fine grained strategy by any means, since data is read a lot more often than it is updated, we are still able to get a satisfactory cache hit rate.
This full response cache has further reduced our response times, with most responses being served within 15ms to 35ms (measured on the server) and a hit rate slightly over 80%.
The following response times show the improvements we saw going from no cache to an object cache and a full response cache.
On the performance plans, things got better with each iteration:
| Cache Strategy | Sample Response Time (ms) |
|---|---|
| None | 2,100 |
| Object Caching | 100 |
| Full Response Caching | 50 |
Final step
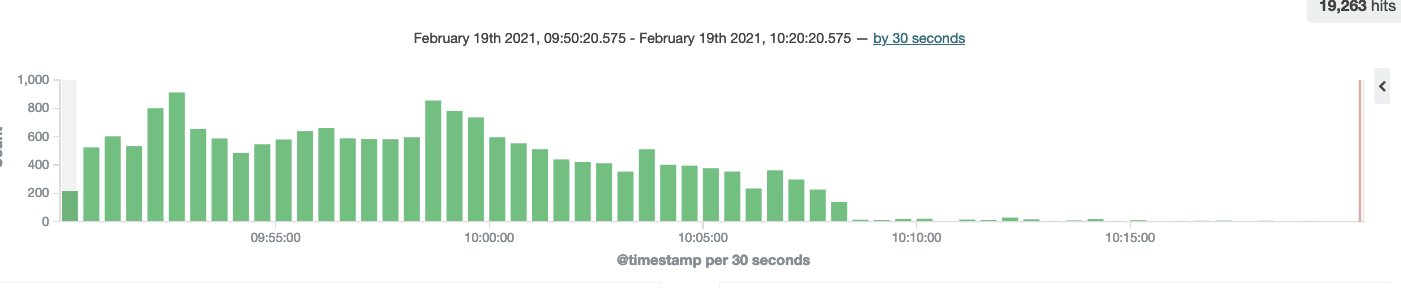
Since initially writing this article, we’ve been able to make use of those exact caching strategies to cache our dynamic API responses via a CDN. This not only improves the response times even more, it also enables the CDN to respond directly with up to date cached content when available therefore decreasing the load on our services. The figure below shows the effect it had on traffic received by our service for a single one of the sites we host after the CDN was enabled.
Authored By



