
Using Amundsen to Support User Privacy via Metadata Collection at Square
More scalable, automated data insights while preserving users’ privacy
When I started at Square, one of our primary privacy challenges was that we needed to scale and automate insights into what data we stored, collected, and processed. We relied mostly on manual work by individual teams to understand our data. As a company with hundreds of services, each with their own database and workflow, we knew that building some type of automated tooling was key to continuing to protect our users’ privacy at scale.
We quickly discovered that companies like Netflix, Airbnb, and Lyft were already iterating on tools for metadata collection. This gave us confidence that we could take a similar approach. Rather than building something from scratch, we ultimately decided to spin up and support our own version of Amundsen, Lyft’s data dictionary solution.
Supporting More Specific Metadata
Once we had Amundsen running internally, we began ingesting schema information from our data sources, including Snowflake, BigQuery, and MySQL. We store this data as nodes and edges in a graph database, as visualized in Figure 1 below:
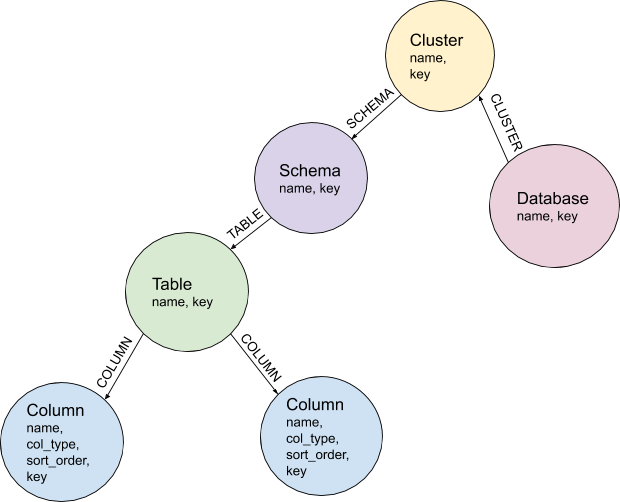 Figure 1: Simple Graph Database Representation
Figure 1: Simple Graph Database Representation
This information by itself is enough to support better data discoverability via the Amundsen UI. Our users can now search for specific tables or column names, and find them across our data sources. Users who aren’t sure the exact naming of a table or column can search on descriptions or the name of the owning app. They can also bookmark tables to make them easier to find later, or view a list of most popular tables based on our access logs. Already, this is a win!
However, we wanted to store more about our data than just where it lived. We knew that if we exposed metadata relating to what the data was, how it was protected, etc, we could empower our Square community to better understand, govern, and use the data we collect. To support this, we created new node types for our graph database that represented more specific column-level metadata.
- PII Semantic Type - A set value describing the general contents of data in a column, with a focus on discovering data that fits into one of three buckets:
- Sensitive by itself
- Could be sensitive when taken together with other data
- Links to sensitive data, like an internal identification token
- Data Storage Security - A set value describing the form of data in a column. Values include
PLAINTEXT,ENCRYPTED, andTRUNCATED. For example, if a column contains only the last four digits of some sensitive data, the Data Storage Security value would beTRUNCATED. - Data Subject Type - A set value describing the users whose information exists in a column. A value might be formatted like:
SQUARE_PRODUCT_CUSTOMER.
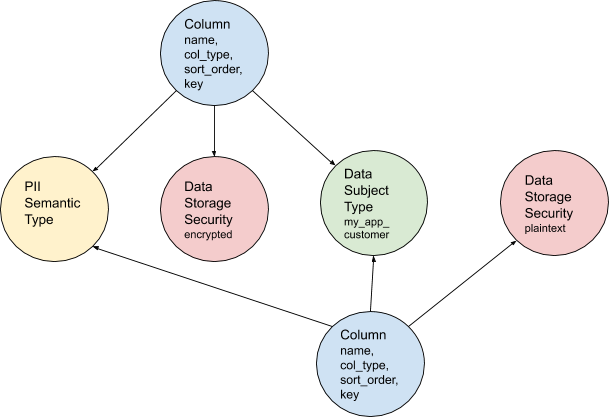 Figure 2: Columns connected to new metadata nodes
Figure 2: Columns connected to new metadata nodes
In Figure 2 (above), two columns hold data that is the same PII Semantic Type, for the same type of user, but one is stored in plaintext and one is encrypted. We can now write a simple query to uncover data we deem to be less protected based on our risk model and make quick changes if necessary.
Supporting Automated Data Inventorying
With hundreds of thousands of table nodes and an order of magnitude more column nodes, we still faced the tall challenge of keeping the metadata about our data up to date and ensuring that information given to us by our data owners remained correct over time. To reduce manual work, and with future scale in mind, we built out logic to flag data storage locations that we’ve judged as more likely to hold sensitive data. This is useful for multiple reasons:
- New data sources get created all the time. Reducing the burden on data owners to properly annotate their tables when they are created can lead to less work for them and better metadata for us.
- Mistakes happen! While a data owner might tell us that something is not sensitive, if the name of the column is
user_phone_number, it might make sense to take another look. On the flip side, checking the first few rows of a randomly named column may reveal highly sensitive data that someone missed.
To support these use cases, we introduced an additional Flag node type. The Flag node contains information about the metadata type it relates to (i.e. PII Semantic Type or Data Storage Security), the possible value (i.e. ENCRYPTED in the case of a Data Storage Security flag), and a more human readable description that we can display in our UI.
 Figure 3: Flag connected to a Column node
Figure 3: Flag connected to a Column node
After receiving schema information from our data sources, we run this information through a first level of checks, looking for low-hanging fruit:
- Is the column name an exact or partial keyword match for a value we expect? - We keep a list of keywords associated with various PII Semantic Types. In this system, a column named
first_nameis an exact match for one of ourPERSON_NAMEkeywords, while a column namedaccount_first_nameor name would return a partial keyword match. - Does the column type match what we expect? - A column named
email_statustriggers a partial keyword match forEMAIL_ADDRESS. However, since its type is boolean and we only expect a string for this PII Semantic Type, we don’t flag it. - Is the column name literal PII? - There are some cases where data gets ingested from a spreadsheet, and it’s technically possible, in a rare edge case, that the headers are actually the first row of data.
- Is the table name an exact or partial keyword match for a value we expect? - A table called
<some_sensitive_data_type>sends a good signal that the data in this table might be sensitive, even if the columns aren’t named in a way we expect.
Next, we run a job that samples values from specific columns we are interested in, and sends the actual data to the Google DLP API. If this API tells us that the values are likely sensitive, we flag the column. If not, we tag the column with the date it was last checked against this API so that we can wait before checking the same column again.
Data owners can view these flags in Amundsen and decide whether the flags are correct or not (setting the “result” property on the edge between the flag and the node). In the future, non-data owners will also be able to flag columns they believe hold sensitive information (either they don’t have any of the metadata values above set, or they think the values are incorrect).
We are continuing to iterate on this logic so that we can help our data owners better understand their data, and supplement the annotation work they do manually. With the Amundsen UI, we are creating a centralized, transparent metadata store, enabling easy discoverability of data and quick feedback loops for maintaining privacy-empowering metadata.
The Future: Supporting More Granular Access Controls
We are currently in the process of supporting more granular access control based on the metadata we are centralizing in Amundsen. To do this, we created two additional concepts within our graph database, and within the larger Square community.
- Purpose - An enumerated, legal-approved reason to access specific PII Semantic Types
- Capability - A combination of Purpose and Data Subject Type
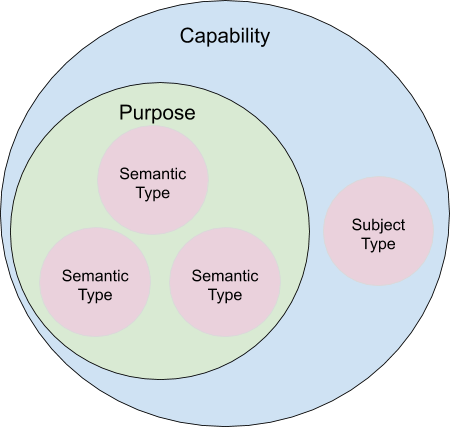 Figure 4: Relationship between Capability, Purpose, and other metadata
Figure 4: Relationship between Capability, Purpose, and other metadata
We believe that access controls based on Capabilities are easier to reason about and therefore, easier to follow and enforce. A customer support specialist for Cash App, for example, may be granted a Capability that includes the Purpose User Support. User Support includes the PII Semantic Types EMAIL_ADDRESS and FIRST_NAME so that grantees can properly communicate with users who request assistance. This Capability’s Data Subject Type, however, is more specific -- CASH_APP_CUSTOMERS only. Customer support specialists for two different business units would have separate Capabilities, even though their Purposes are the same.
Because PII Semantic Types and Data Subject Types are tagged at the column level, we can expose an endpoint within Amundsen that will tell callers which specific columns an employee has access to based on their Capabilities. A service in charge of gating access to Snowflake, for example, would call Amundsen to get this list of tables/columns, then build specific Snowflake views for the user that only include the columns they are allowed to access.
In the future, our users will be able to visit the Amundsen UI to see which specific columns a Capability grants access to, and request the access they need. Data owners, meanwhile, will have better transparency into the exact data a user can access, empowering them to revoke access that no longer seems relevant, or suggest a new Purpose if one seems unnecessarily broad.
Conclusion
Square is not the only company working to centralize our metadata and scale privacy solutions, especially in light of increased focus on consumer privacy and new requirements from laws like GDPR and CCPA. Our approach aims to make privacy an easy outcome of more streamlined workflows, and with Amundsen, we are excited to help other companies do the same. If you are interested in getting involved, read more about Amundsen and join our community on slack!
Authored By

