
Square Payroll’s Migration from a Monolith to Microservices
Scaling with AWS serverless architecture
Imagine a large soccer field with many balls scattered around. There are players whose job it is to scour the field checking in on each ball and determining whether the ball should be kicked or skipped. For each ball that needs to be kicked, the player needs to inquire from a coach how precisely to kick the ball. In this polling model, there is a large burden of responsibility placed on both the players and the coach. Also, many balls are checked in on, for which no action was required. This is the pre-migration story.
In the post-migration story, players stand at designated field positions, balls that need kicking are queued up next to designated players. Players kick enqueued balls in specific directions to their next queue location, based on flashing arrows on the ball.
Context
Square Payroll provides payroll services for small businesses. Today, the infrastructure supporting these responsibilities is largely housed in a Ruby monolith backed by MySQL. Thanks to great product success and user growth, Square Payroll is now at a point where servicing our customers is motivating us to undertake a migration to more scalable architecture. This document is focused on a successful early step in this journey, focusing on a redesign of our tax filing system using AWS serverless architecture.
The theme of migrations from a monolith to microservices is a relatively common genre in the tech industry. This experience is a reward that successful companies are privileged to undertake. Typically, these stories are told at a higher level. In contrast, in this article we will focus on a narrower example and dig deeper into the details. In particular, we will discuss a non-trivial situation we encountered which was tailor made for using a Step Function to reduce code complexity and increase transparency.
Terminology
- Sidekiq is a background job scheduler in Ruby.
- The Employment Development Department (EDD) of California, is a department of the California government that collects unemployment taxes from California employers.
- Amazon Web Services (AWS) is a subsidiary of Amazon that provides on-demand cloud computing platforms.
- A Square application or App, is an independent application within Square, associated with a cost center, owners, and a collection of infrastructure and storage options.
Background
For Square payroll, the “soccer balls” from the opening imagery are what we call “tasks”. Tasks are rows in a database table. Each row, or task, in the data model represents an instance of a workflow. For example, a single workflow might be: pay tax X, for employer Y, to agency Z, in association with event W. The control flow of a task workflow is defined by in-code configurations and orchestrated by Sidekiq workers.
The task architecture is largely polling-based, relying today on >100 distinct cron jobs which run on a fixed schedule and regularly poll for any available work to do.
Goals
Engineering design goals
- The architecture will be event driven. We will kick off AWS supported workflow with an event message containing information that encapsulates all the required information for progression of the task. We will not have any queries of Square Payroll Databases from the payroll-filings service.
- The flow of information will be push based. With payroll pushing work to do, to payroll-filings, and payroll-filings pushing back updates to the payroll monolith.
- Lambdas will be single purpose mappers taking inputs, performing work, and producing output. Lambdas will have no, or minimal, need for conditional or configuration logic. Conditional logic will be delegated to configurable component resources, e.g. Step Function Choice states.
Technical Design
We built a new AWS “serverless” app, or service, payroll-filings. The payroll-filings app consists of a number of filings microservices encompassing lambdas, SQS step-functions, dynamoDB, and SecretManager. The payroll-filings app is split into two new repositories: payroll-filings and tf-payroll-filings. The payroll-filings repo contains our business logic, and source code for lambdas. The tf-payroll-filings is a terraform configuration repo we use to build our AWS resources. Separating code and configuration layers into different repos helps keep each repo focused on a more singular purpose structure and design. Separate repos also allows for build/deployment flexibility, and lowers the blast radius of code changes.
The Square payroll app sends an event in the form of an SQS message to the payroll-filings service. This event includes all the required information the payroll-filings service needs to complete the filing. The payroll-filings service posts updates to the square payroll service at fixed check-in points and when the filing is in a terminal state. Update postings between the square payroll and payroll-filings service occur over SQS. Using SQS as a standardized bi-directional cross service communication process between square payroll and payroll-filings is a good fit for the background, asynchronous nature of filings, provides system robustness in the form of fault tolerance 1, and allows for easy observability 2.
This architectural design allows both filings logic and data to be encapsulated in the payroll-filings service. A new payroll-filings repo houses payroll-filings business logic which can be removed from the payroll monolith. Additionally, a DynamoDB table was created in the payroll-filings AWS account, used for internal implementation of the filings workflow, and this internal data is not needed by or exposed to Square payroll.
Architectural Changes
Pre-existing Design
The subject of this article is the migration of a single task representing the workflow responsible for a single employer (ER) paying their State Disability (SDI) and State Income Taxes (SIT) to the California (CA) EDD. These taxes are required to be paid on a per payroll-run basis.
In the pre-existing design, the process of generating, progressing, and driving the workflow to completion involves 3 distinct cron entry points. A task is created with a status CREATED by an async job after a CA employer runs payroll to pay their employees. This row in the task database captures the obligation of the ER to pay taxes to CA as well as some metadata for the filing. A Sidekiq cron job queries for all CREATED or IN_PROGRESS tasks and kicks off async jobs to progress the task. The kicked off async jobs call a ruby method based on the current status and step of the task as stored in the database. This ruby method can be a no-op or mutate the tasks status or step so that a subsequent instance of the task polling worker will call a new/different ruby method on the task.
This polling task progression is not the entire story however. As part of the polling task progression, an “External Communication” is attached to the task which represents the content of what will be sent to the CA EDD agency in order to ask CA to debit the ER for the required taxes. There are two other cron jobs that are responsible for progressing the communications that are relied on by the task workflow. One cron job queries for transmissions ready to send and sends them in a batch to CA. Another independent cron job polls and checks on the status of all sent transmissions. Together these two communication cron jobs update the status of the external communication after acting on them.
Ultimately when the transmit and checking cron jobs progress the external communication to a terminal status, the task polling worker will realize this update and progress the task toward completion. See diagram below for details.
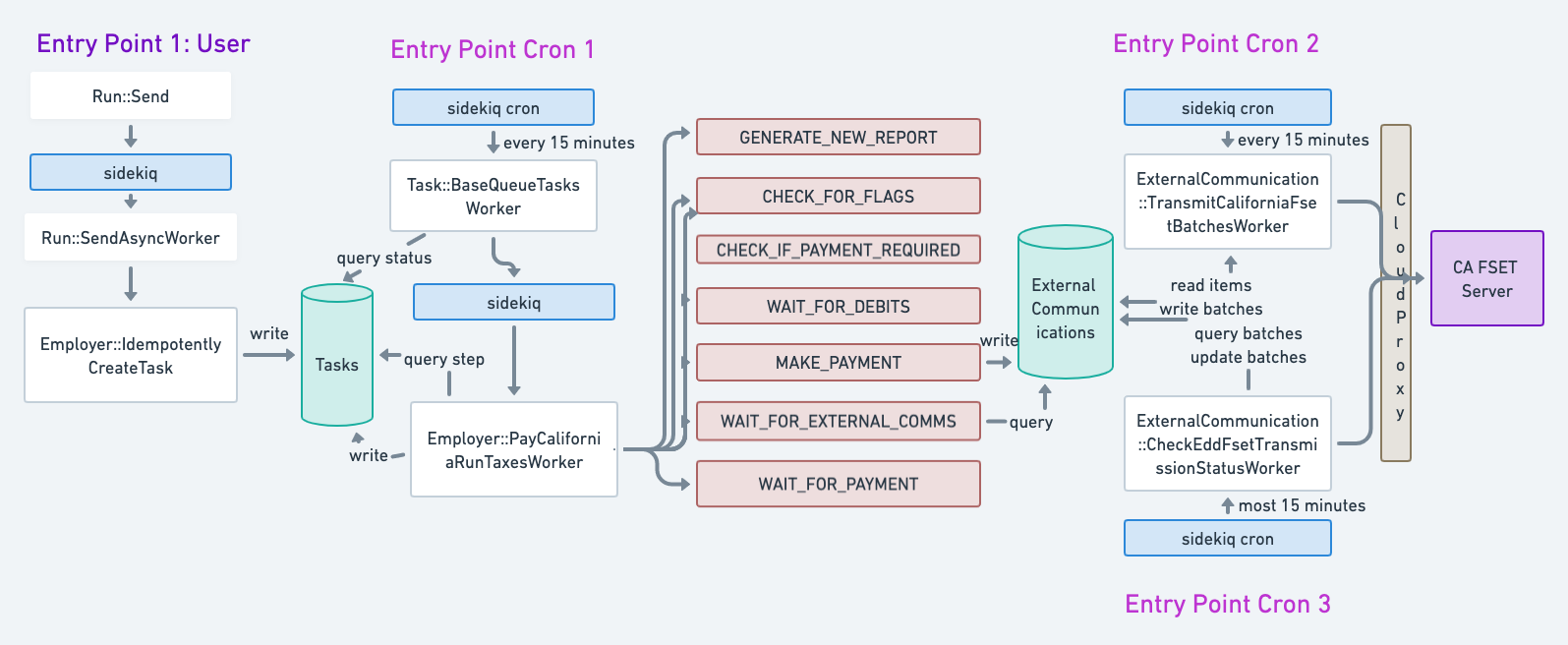
Pain Points with pre-existing design
With the pre-existing design, we experienced the following problems:
-
Not Great Availability.
The pre-existing design is dependent on the Sidekiq server uptime. Sidekiq processes can be shut down for example by code deploys or by other activity on shared nodes. In some cases shutting down a task worker abruptly can cause errors for in progress communications or connections.
-
Inefficient, database-heavy architecture.
Our current polling task system relies on sidekiq kicking off to potentially advance tasks to a next step. In many cases we check too frequently for work to do, leading to execution no-ops. In other cases we allow unnecessary time lapses between steps.
The polling architecture strains, and is limited by, our MySQL cluster as each polling step must start by querying the database for required information to perform its objective. In terms of the imaginative example at the start, the MySQL cluster here is the coach who must direct each player as to how to kick every ball.
-
Reduced engineering velocity and increased bugs.
We lack clear, future-proofed, visibility into a tasks path through its workflow. For example, using previous tasks as examples can result in outdated expectations. Similarly, using happy path examples can miss edge case trajectories. This limited visibility results in reduced engineering velocity and more time triaging bugs or iterating on tasks.
Our pre-existing code intertwines business logic and configuration routing. Our code also relies heavily on end-to-end and integration testing. The combination of these two factors makes it intractable to thoroughly cover all situations due to logical branching.
New event-driven design
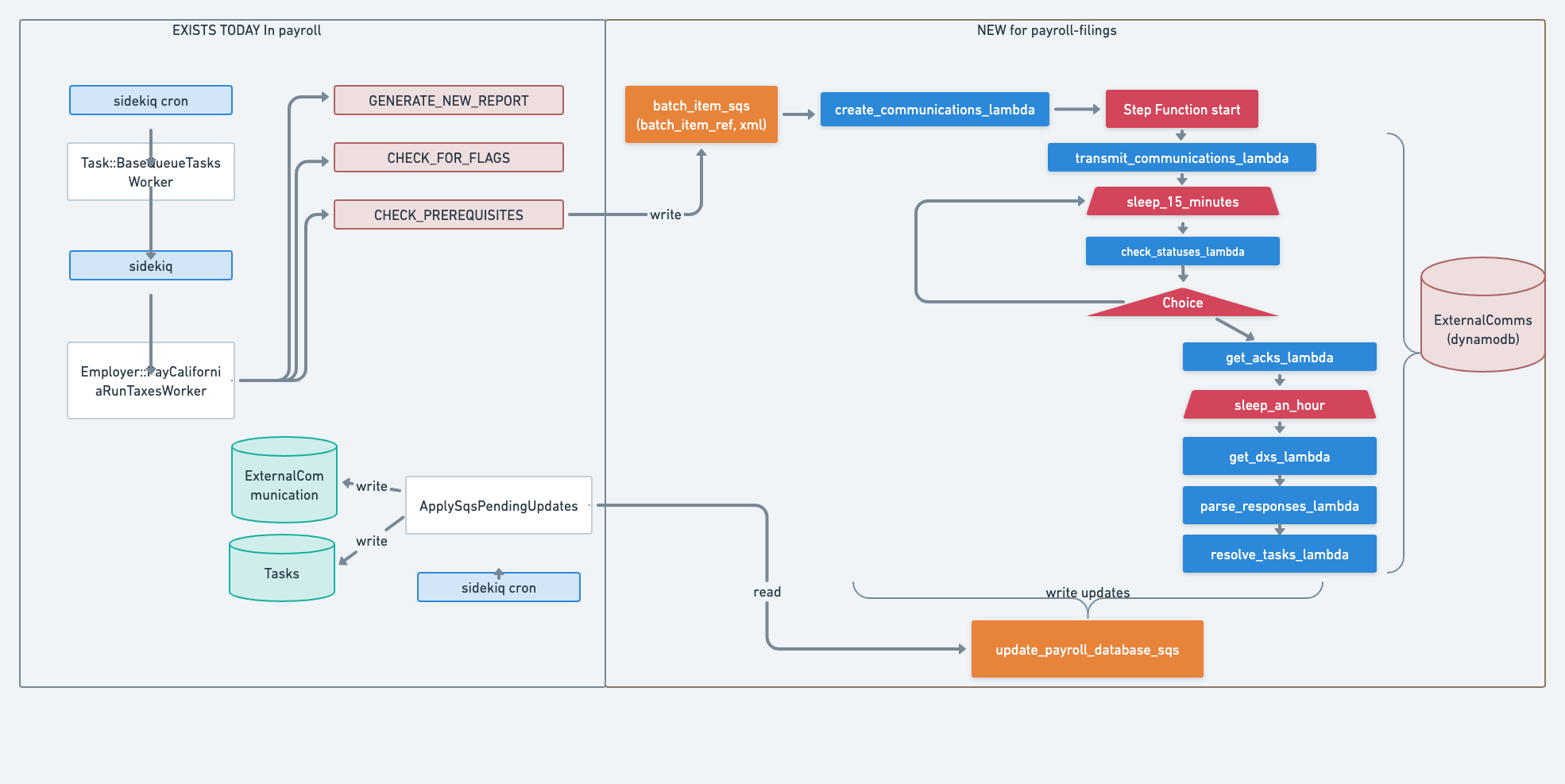
In the new design we used AWS Step Functions as an ideal, out of the box solution for our situation to replace the need for three cron jobs. Step Functions allowed us to transparently orchestrate our workflow by piecing together Actions (Lambdas) and Flows (Choices and Waits), all while keeping the code of complexity of the lambdas minimal.
The following two examples highlight some of the value of using a Step Function.
Old: We used a cron job to poll for the transmission’s status that returns early unless the status was successful. New: We used a Step Function “action lambda” to fetch the transmission status and then configured a Step Function “choice” to compare the status with expected outputs and either wait to retry, or progress the task.
Old: Tasks frequently shared a common workflow, with some tasks having certain steps in their workflow be no-ops.
For example, all pay taxes tasks have a step called WAIT_FOR_DEBITS where nominally we are waiting for a debit from an employer to be received by us, so that we can turn around and pay the debit to the government agency without incurring risk loss. However, for some tasks in which money is being paid directly from the employer to a Government entity, there is no need for this wait step. The logic of whether a wait step could be trivially skipped was contained in the form of a conditional check in the source code. We were applying the “Do not repeat yourself” (DRY) principle to the workflow design, at the cost of code complexity and decreased system transparency.
New: We created a unique Step Function to transparently correspond to each unique workflow. We are still applying DRY, but rather than applying DRY to the design, we are applying DRY to the source code by reusing lambdas across different Step Functions. Additionally, our lambdas no longer need the conditional branching to check if their step applies as the lambdas are only included in workflows where they are in fact needed.
The following is the new design for the task workflow.
Updates to Square Payroll database
Updates to the Square Payroll database from lambdas are sent over SQS. Updates are limited to specific update types. Message handling is encapsulated in a deep update service module.
Messages in the SQS indicate which of the supported APIs are being used and include the required arguments. Timestamps are passed into the API as there can be a delay or out of order consumption of updates between payroll and payroll-filings.
Data Model Changes
There are no changes to the Square Payroll MySQL data model. Instead we added a new data model to the new payroll-filings service in the form of a DynamoDB single table. This table contains data that was previously stored in Payroll.
Conclusion
On Square Payroll we are currently at a very exciting product juncture. We are planning for and taking on foundational investments in state of the art, scalable, architecture design. The journey is still at an early stage, so we look forward to sharing future deep dives into other parts of our tech stack. Most importantly, if this work is exciting to you, please reach out! We have a lot left to think about and build out together.
Authored By

