
Shard Splits with Consistent Snapshots
How to take a copy of something too large to fit in a single shot
Splitting shards into smaller shards
At Square, we have a lot of data being inserted into our databases. To make it possible for MySQL to handle the load, we shard the data using Vitess. Because the amount of data we are receiving is very large and the rate is increasing, we are not done just because we’ve split the database once. Rather, we need to keep making the shards smaller so that each individual MySQL database does not have to deal with too much data at once.
In theory, this is pretty straightforward. We have already decided on which column to shard, so all we need to do is to go over each row in each table and use the hashing algorithm to decide which new shard the row will end up in.

The problem here is more one of scale. Our shards tend to be around one terabyte in size when it’s time to split. Any operation on that much data will take time. During that time, data keeps coming into the system and we can’t just tell customers “hold that thought, we’re just going to take a couple of hours to do database maintenance, m’kay?”
Shard splitting is a gradual process. Here, I’ll walk you through this process, and what Vitess does to make it possible to do this with minimal impact on the app layer. I’ll also explain a new feature we are in the middle of adding to Vitess that will make this process more efficient in many cases.
When splitting a shard, one can split into at least two pieces, but one can also split into more shards, such as one-to-four or even one-to-eight. For simplicity, I’ll only discuss one-to-two, but the concept is the same.
The first step is to set up the destination databases and copy the table structures. Once done, the destination shards are ready to receive their share of the data.
Big picture first
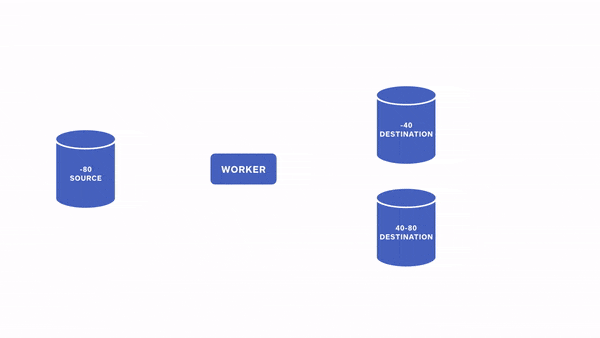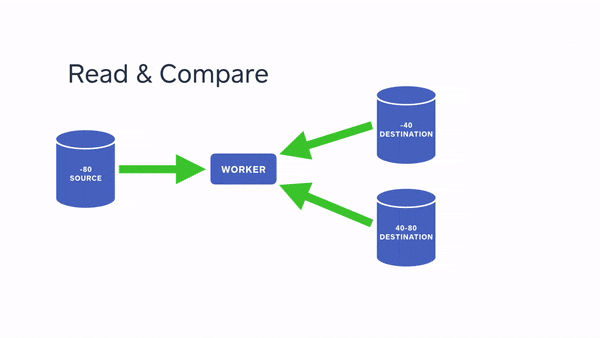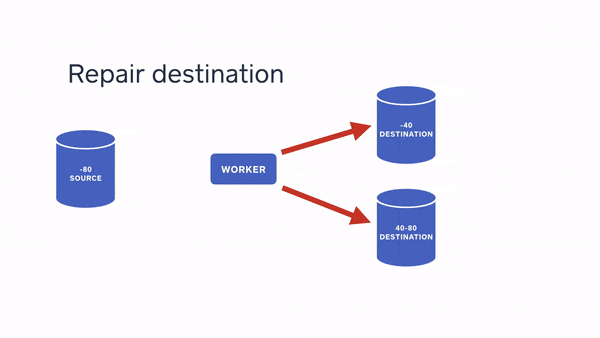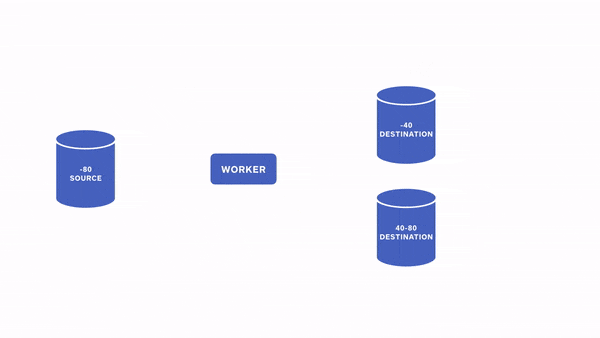
The next step is to do what is called an “online clone,” which means going over each table and copying the row over to the destination shard that the hash points to. This is done without grabbing any special locks on the source tables. By the end of this phase, we have lots of data in the destination shards, but because we did not protect ourselves from concurrent updates, it’s most certainly inconsistent. Since the source database kept getting inserts, updates and deletes while we were copying data over, the copy now has different parts from different points in time. A nice visual example of this is when you take a panorama photo and something moves in the picture.
 Photo by lastnightat3am is licensed under CC BY 2.0
Photo by lastnightat3am is licensed under CC BY 2.0
At the end of this phase, we have the background of the picture correct. There are probably anomalies, inconsistencies and other issues with the data, but that is expected, and OK. We don’t have to be satisfied with the physics of the normal world; in software, we can have superpowers!
But I’m getting ahead of myself . . .
Clean up
To fill in the details, we have to take the next step, which is an “offline clone.” This means taking one of the nodes in the source shard cluster offline — we turn off all queries and replication to one of the replicas, and wazam, we have a stable point to copy from. Now we go over all the tables in the source and compare with the rows we’ve copied over. Any discrepancies are fixed as we find them. This is much faster than the original copy, even though we have to scan all rows of all tables again, simply because reading is so much faster than writing to a database. A read just takes grabbing a lock and reading, whereas a write has to take locks, write to a transaction log, update the table in memory (if a page fills up, spill over!), update indexes, replicate changes to replicas, etc. Suffice it to say that there is just a lot more to do when writing data than when reading, and in this second step, we are mostly reading.
Before we are done with this phase, we want to make sure we track changes, so we turn on vReplication from the source to the two destinations. vReplication, or filtered replication as it’s also sometimes referred to, is replication that takes sharding into consideration. Only the rows that belong in the destination shard are copied over. The source cluster is still taking all the reads and writes, but changes are copied over to the destination shards, so they have up-to-date data and are ready to take over.
Our extension
In some environments, it is not possible to pause replication to a single database like that. If you are on Amazon’s Aurora, you can only control the replication to a whole cluster, not to individual nodes. Here at Square, the way we provision databases makes it difficult for us to control replication. Our solution has been to set up an extra node in a different environment that we host ourselves and can control. This is very time consuming, so when I joined, improving this situation was my starter project.
Jon Tirsén pointed me in the direction of mysqldump. To make an online backup, mysqldump has the same problem, namely that a moving target is difficult to copy. Their solution is cool and what we ended up using it as well.
You can read the interesting code for mysqldump yourself here. Here is a comment from that file:
To get a consistent backup we lock the server and flush all the tables.
This is done with FLUSH TABLES WITH READ LOCK (FTWRL).
FTWRL does following:
1. Acquire a global read lock so that other clients can still query the database.
2. Close all open tables.
3. No further commits is allowed. This will ensure that any further connections will view the same state of all the databases which is ideal state to take backup.
This is the connection provider that mysqldump will use for all reads from the source.
The approach is simple on the surface but there’s a lot of very complex machinery under the hood. First, we make sure to pause all updates to the source by grabbing a huge read lock on every single table using FLUSH TABLES WITH READ LOCK (FTWRL). This is equivalent to pausing replication — no transactions make it through now.
Then we open as many transactions as we want connections. When opening them, we specify that we are interested in getting a consistent snapshot transaction, which is very helpful in this situation. This gives us a stable picture of the database — if things move, MySQL works hard to recreate the original state for us. Since we first paused all updates using the FTWRL, we now have a bunch of transactions that all point to the same point in time in the evolution of the database. In short, we have frozen time!
Now we can release the table locks and allow the replica to resume receiving replication traffic from its leader.
Using this transactionally stable view of the database, we can now go over the database and fix inconsistencies introduced by the first copy.
This makes for better use of resources — the replica can still participate in read-queries and does not lag behind replication traffic, and we don’t have the big task of setting up an entire node just to be able to split into smaller shards.
The results for us

For us, this change has made it possible to split shards much quicker. With our old process, we could do a couple of splits per week, and now we can do a couple per day. Some very smart people on the MySQL team have worked hard and for a long time on the features we rely on, and it makes perfect sense for us to leverage their work.
This post is part of Square’s Vitess series.
Authored By

