
Implicit Product Tagging
How To Label With Data You Don’t Have
Problem Statement
To best understand the problem that Implicit Labeling solves, it’s important to clarify what Explicit Labeling is. Fundamentally, any model needs data X to predict the output Y. For example, given a series of transactions (let’s call these X), we can tell whether or not they are Fraudulent/Okay (our label Y). Since we capture both sets of data, we can develop, train, and deploy a fraud model that can look at payments data and tell us what’s fraudulent and what isn’t.
What happens when we don’t have label Y? For example, we want to measure alcohol sales on the Square platform. Sure, we have the names of items sold, but we don’t have a flag like isAlcohol='Y'. Sure, we can write some rules that say, “If this item has ‘gin’, ‘mezcal’, or ‘beer’, let’s label it as an alcoholic beverage,” but that type of ruling is time-expensive and might require subject-matter expertise. We need a better way to associate item X and a potential label Y (that we don’t have).
Implicit Labeling
There are actually a series of transformers that do something called Zero Shot Classification that specialize in solving this type of problem. In summary, you give these transformers a sequence of words, such as an item name X, and you give it a set of potential labels Y.
Example
Item: “Szechuan Wontons”
Labels: ["Spicy," "Not Spicy"]
Scores: [0.76, 0.24]
In the example above, our item is Szechuan Wontons, and we want to label it as “Spicy” or “Not Spicy.” By running the item and label through a Zero-Shot Classification model, it would determine that the item is more likely to be spicy than not, probably because the token Szechuan is associated with “Spicy.” In practice, instead of using “Not Spicy”, we will use a blank space as our null label. The reason we do this is because “ ” has no embedded value to it to bias a response. Our null label is probably as important as our label, but we’ll get into that later.
For simplicity, the label we’re going to try to assign is coffee, because we assume most people can follow what is coffee, what isn’t coffee, and where things get nuanced. You might be able to capture coffee with a set of keywords, but again, we’re oversimplifying here so that it’s easier to follow.
Is It Coffee?
The goal of this exercise is to create a high-quality dataset that has accurately labeled values for items, and whether or not they are coffee. To start, you’re going to want to install transformers and torch, if you haven’t already.
pip install transformers
pip install torch
We’re also going to want to import these with a couple other packages to make this run smoothly.
import pandas as pd
import os
import torch
import seaborn as sns
The transformer we’re going to use for this exercise is Facebook’s BART (facebook/bart-large-mnli). I’d encourage you to check this list of models on HuggingFace if you’re working with multiple languages (BaptisteDoyen/camembert-base-xnli is specifically designed for FR language, so I would defer to use that if you we’re doing this in French). Let’s load our model and set our classification label.
from transformers import pipeline
if torch.cuda.is_available(): classifier = pipeline("zero-shot-classification",
model="facebook/bart-large-mnli",
device=0)
else: classifier = pipeline("zero-shot-classification",
model="facebook/bart-large-mnli")
classification_label = 'coffee'
null_label = ' '
candidate_labels = [classification_label, null_label]
Notice we call on torch.cuda.is_available to check if we have an NVIDIA GPU enabled. While you don’t need a GPU to run this pipeline, it will be prohibitively slow on CPU. To illustrate, running one example on GPU is less than one second; on CPU it takes about 14 minutes. If you don’t have access to a GPU, try using the default GPU instance on Colab (even the free tiers will have GPU availability).
Let’s try some examples — first, with something obvious.
sequence_to_classify = "cappuccino"
classifier(sequence_to_classify, candidate_labels)
# Output
## {'sequence': 'cappuccino',
## 'labels': ['coffee', ' '],
## 'scores': [0.8640812039375305, 0.13591882586479187]}
Okay, looks like cappuccino is, in fact, coffee. Astounding performance. Let’s try something else.
sequence_to_classify = "wine"
classifier(sequence_to_classify, candidate_labels)
## Output
# {'sequence': 'wine',
# 'labels': [' ', 'coffee'],
# 'scores': [0.9873257279396057, 0.012674303725361824]}
Okay, wine is definitely not coffee. Still good. Note that the order of the labels has flipped. Keep in mind that his model will return the labels in order of their scores. This is annoying for binary classification, but is super useful when you might have three possible labels. Let’s try something else.
sequence_to_classify = "Garlic Bread"
classifier(sequence_to_classify, candidate_labels)
# # Output
# {'sequence': 'Garlic Bread',
# 'labels': [' ', 'coffee'],
# 'scores': [0.9944584369659424, 0.00554158678278327]}
Okay, let’s throw a curveball. Can we do the same thing in Japanese? Let’s give it a try. For reference, カプチーノ means cappuccino and コーヒー means coffee.
sequence_to_classify = "カプチーノ"
candidate_labels = ['コーヒー', ' ']
classifier(sequence_to_classify, candidate_labels)
# # Output
# {'sequence': 'カプチーノ',
# 'labels': [' ', 'コーヒー'],
# 'scores': [0.9102840423583984, 0.08971594274044037]}
Ouch, so it looks like the null label won here. We might need to adjust our null label. Let’s try again, but setting the null label to ヌル (null in Japanese).
sequence_to_classify = "カプチーノ"
candidate_labels = ['コーヒー', 'ヌル']
classifier(sequence_to_classify, candidate_labels)
# # Output
# {'sequence': 'カプチーノ',
# 'labels': ['コーヒー', 'ヌル'],
# 'scores': [0.5033012628555298, 0.4966987669467926]}
Okay, so this null_label isn’t perfect, but we’re going in the right direction. I don’t know Japanese, but the point to highlight here is make sure that your null label is reflective of the use case at hand. You might need to experiment with a few before you’re ready to go.
Is This Coffee? What About This? How About This?
Okay, so we have a decently reliable way to label coffee for our items.
Now, we’re going to start labeling. However, I do not recommend running this on more than 10K records. Counterintuitively, more data is not good here.
Q: What? Why wouldn’t we want to run this on everything?
There are three reasons you’re not going to run this Zero-Shot on every record you have.
- At scale Zero-Shot Classification can take a really long time. It takes about one minute to process 1,000 items. That means if you have 100,000 records, you’re going to be running that model for about an hour and a half. You will also timeout of the free version of Colab.
- As we’ll see in this article, Zero-Shot Classification is not perfect, and we can actually improve our data by going through some of the undecided labels.
- If you decide to supervise the results of the labeling and add corrections where needed, you will improve the quality of your dataset drastically. On a sample of 4,000 records, I probably spent about two minutes correcting labels that were undecided. If you run this on 100K records, have some friends (and some coffee) to go through the labeling corrections.
Q: But I actually need to label more than 10K records. What do I do?
If you need to label more than 10K records, I recommend you use the final dataset from this exercise and train a transformer to label the rest for you. We won’t cover that in this article, but we might in an upcoming article.
Before we let our Zero-Shot model rip on our entire dataset, let’s run this model on a sample of about 4,000 records. To clarify, we’re going to take 4,000 unique item names from U.S., UK, Australian, and Irish items from food and beverage sellers.
english_items = df[df.COUNTRY_CODE.apply(lambda x: x in ['US', 'AU', 'GB', 'IE'])]
item_names = english_items.NAME.unique()
sample = english_items.sample(4000).NAME.unique()
# Run the sample through the classifier
sample_labels = [classifier(x, candidate_labels) for x in sample]
# This took 3m 43s on a GPU
For each item we’re going to want to assign the probability of our classficiation_label. In this case we’re going to create a column called coffee_score, which gives us the relative score that the item is coffee.
sample_output = pd.DataFrame({'name': sample, classification_label+'_score': label_probs})
Let’s take a look at the score distribution to see how the sample was labeled.
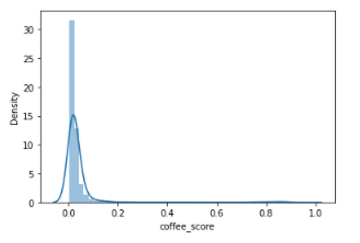
As we’d expect, the vast majority of items are not coffee, so it looks like our items have been labeled properly. Let’s take a look at different score tranches to see where the results start looking a lot less like coffee.
sample_output[sample_output[classification_label+'_score'] < 0.75].sort_values(by=classification_label+'_score', ascending=False).head(10)
The top coffee_score results aren’t surprising. They have the classification label in their item name, so they’re obviously going to get covered.
| Item Name | Coffee Score |
|---|---|
| 1 large coffee | 0.9601255655288696 |
| 2 coffee | 0.9014308452606201 |
| black coffee | 0.8894062042236328 |
Going to the next tranche (coffee_score < 0.75), we’re seeing terms for coffee, such as mocha and latte. On to the next tranche.
| Item Name | Coffee Score |
|---|---|
| bio-coffee | .747865617275238 |
| coffee and cookies | 0.7452135682106018 |
| milk latte | 0.7413088083267212 |
| mocha latte | 0.7153729200363159 |
Going to scores under 0.50, we’re starting to see why this model is so valuable. We’re seeing a lot of items that traditional methods such as keywording would not have included. Furthermore, we can see banoffee, which is a type of coffee, is included here. Here is where the nuances kick in. Depending on the need of your model, you can either attribute it as coffee or not.
| Item Name | Coffee Score |
|---|---|
| banoffee | 0.49095621705055237 |
| biscoffee | 0.490482360124588 |
| espresso | 0.4893379807472229 |
| latte | 0.4725055992603302 |
Based on the histogram and the scores below, it looks like we’re not getting strong matches under 0.30, so we can call these a wash and assign them an N for isCoffee.
| Item Name | Coffee Score |
|---|---|
| sunday roast | 0.2864392101764679 |
| brewed hops | 0.27759650349617004 |
| diet coke | 0.27755919098854065 |
After investigating the scores, I feel confident in setting an initial rule that says that if coffee_score < 0.30, isCoffee is 0; if coffee_score ≥ 0.60, isCoffee is 1. Everything in the middle will be undecided, and we’re going to export this dataset and fill in the items manually. For coffee, virtually anyone can go in and label what’s coffee and what isn’t, but for more complex items, you might want to limit your data size so you have to do less research.
Remember, 50 great data points are worth more than 10K average ones. The tighter your labeling is to the truth, the better your downstream models will be.
Authored By

