
How We Unified on One Graph at Block
Using GraphQL federation to unify under one "supergraph"
At Block we are working with federated GraphQL to enable clients to consume a unified API of aggregated data from microservices in the backend. It allows, for example, for a single HTTP request from a client application to fetch data about merchants, customers, orders, catalog items, and more even when the data is stored separately in unrelated backend services.
About GraphQL
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. It allows you to define a schema of types and fields using a declarative syntax and allows clients to send HTTP requests, or GraphQL “operations,” to fetch only the data they wish to consume, down to the field level. A type is something that represents an important entity in your system, like a Merchant. A field is an attribute of one of those types, like “businessName”.
# A GraphQL schema definition defined by the server:
type Merchant {
id: ID
businessName: String
}
type Query {
merchant(id: ID!): Merchant
}
# A GraphQL operation the client could send to fetch the business name of a merchant with id “abc”
{
merchant(id: “abc”) { businessName }
}
About Federated GraphQL
Federated GraphQL is a way of combining multiple small GraphQL APIs into one large API. It creates for clients a single GraphQL endpoint, serving an API referred to as the “supergraph”, where fields can be resolved from different federated “subgraph” services in the backend. This approach gives both data aggregation and scoped backend services that are maintainable by individual teams.
See the schema example below to see how things are combined in a federated GraphQL schema:
# Example service schema: Catalog Graph
type Query {
catalog(merchants: MerchantFilter!): CatalogQueries!
}
# Example service schema: Customers Graph
type Query {
customers(after: Cursor, filter: CustomerFilter!, first: Int): CustomerConnection
}
# Resulting federated schema
type Query {
catalog(merchants: MerchantFilter!): CatalogQueries!
customers(after: Cursor, filter: CustomerFilter!, first: Int): CustomerConnection
}
At Block
We began by building an internal graph with a schema that describes data across the company. We created subgraphs with types to represent Merchants, Payments, Hardware Devices, and more. Our target client consumers at the beginning were internal applications, such as operational and developer tools. In a separate initiative, we built a public GraphQL API for Square as a companion to our REST API. This graph is used by third party developers building applications on top of Square APIs.
Logically, the Square Public GraphQL API has always contained a subset of the data available in the internal graph.
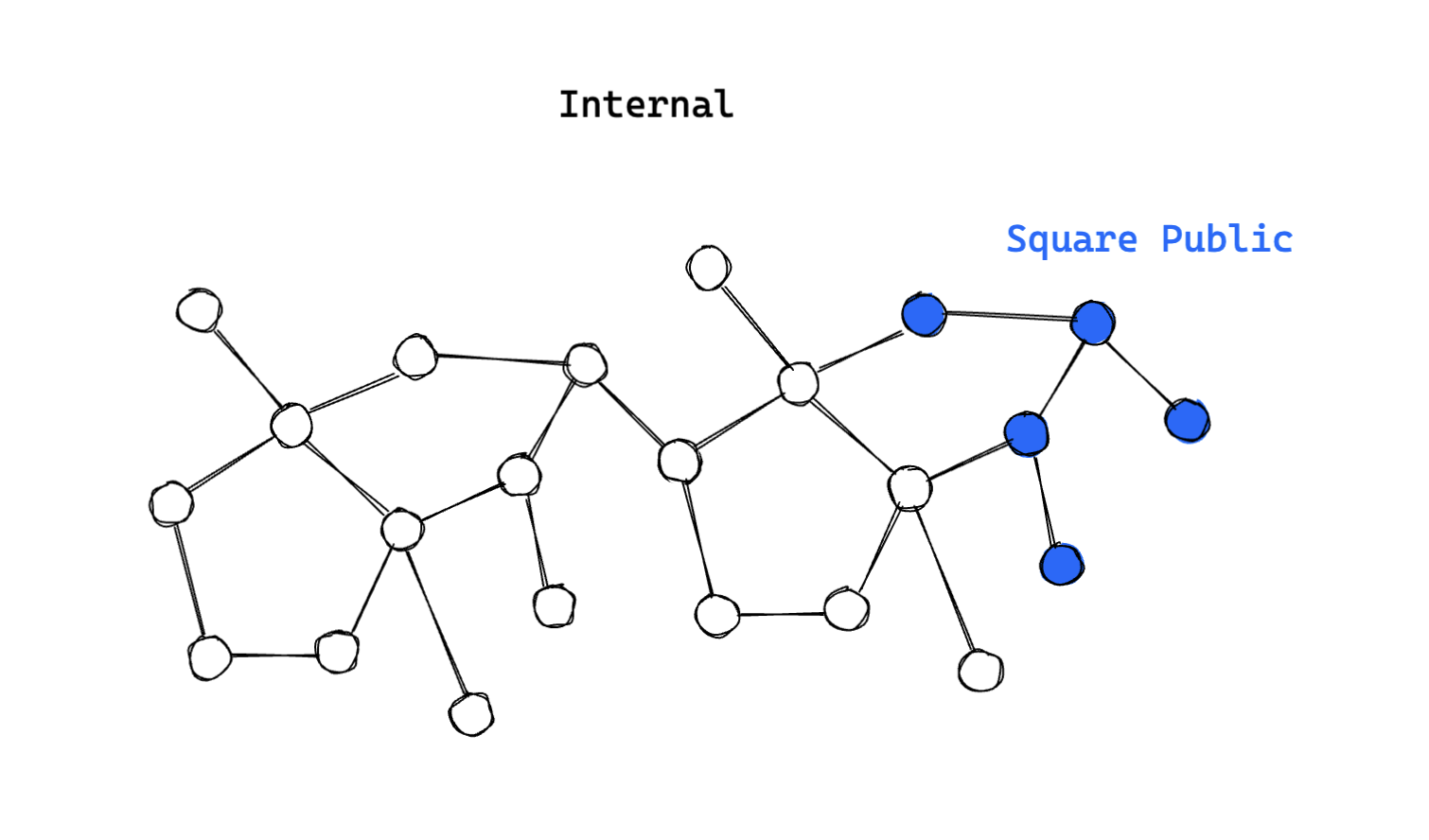
In terms of implementation, these two graphs were initially separate GraphQL APIs, running on different technology stacks.
The first stack uses an Apollo Gateway to serve the supergraph, and custom built CLI tooling to generate subgraph services. Subgraph generators are tools we built to allow developers to run a command and generate a subgraph codebase. The generated services are essentially empty GraphQL servers, except that come fully functioning and are also ready to integrate into the federated graph. They are pre-wired to do things like Apollo schema checks on every PR, and push the schema into a registry when artifacts are built. We used Apollo’s open source implementation of the gateway server, and customize it only so far as we need to to make it work at Block.
The second stack powered the first version of the public API. This system used a handwritten gateway and handwritten subgraphs (both using graphql-java) and a custom approach to combining GraphQL schemas from multiple subgraphs. The approach used here involved the gateway holding a copy of every subgraph schema, checked into version control.
We had these two separate GraphQL APIs and tech stacks and wanted to merge them, while keeping both API schemas separately accessible for the internal and third-party use-cases. With the introduction of the Contracts feature from Apollo, we felt the inspiration and support we needed to achieve this goal.
Contracts
Contracts let you tag types and fields of a GraphQL schema with a directive that looks like this:
type Merchant {
id: ID! @tag(name: "public-square")
…
}
Next, in Apollo Studio, you can set up configuration to either include or exclude schema members tagged with a certain value in a new projection (aka “variant”) of the graph’s schema.
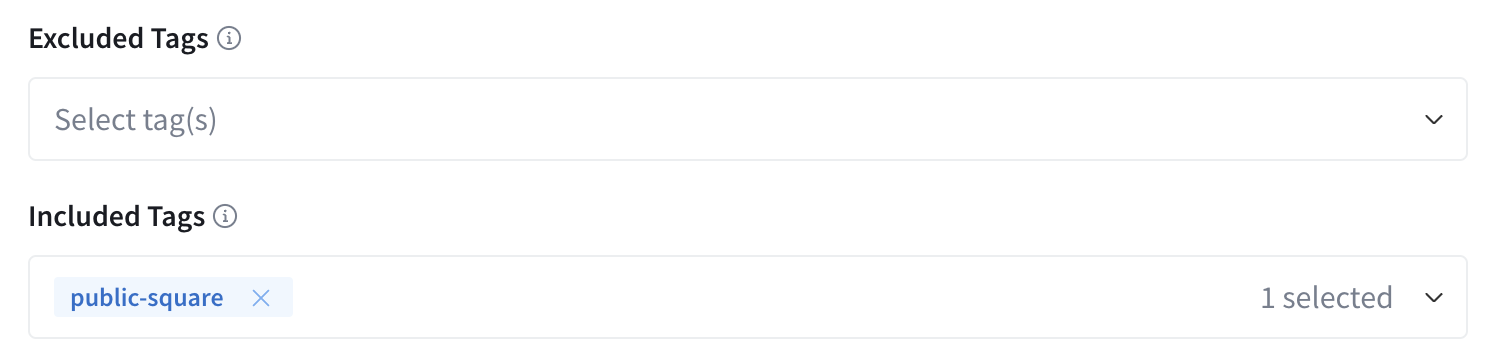
After you do both of these things, it produces a new graph variant that you can run on an instance of a gateway which will only contain the schema members you want to be included, according to your contract configuration. We were able to use this feature to serve a subset of our internal schema as the Square Public GraphQL API.
Unification
To complete our transition from separate APIs to one graph with multiple variants of the schema, we followed a three phase approach:
- Subgraph Unification
- Contract Creation & Tagging
- Rollout of New Variant
Subgraph Unification
The first step was to unify all the subgraphs. Given that the plan was to move everything to the Apollo based federated graph and that graph was currently internal, we were able to take all the subgraphs currently used in the public graph and include them as subgraphs in our internal graph as well.
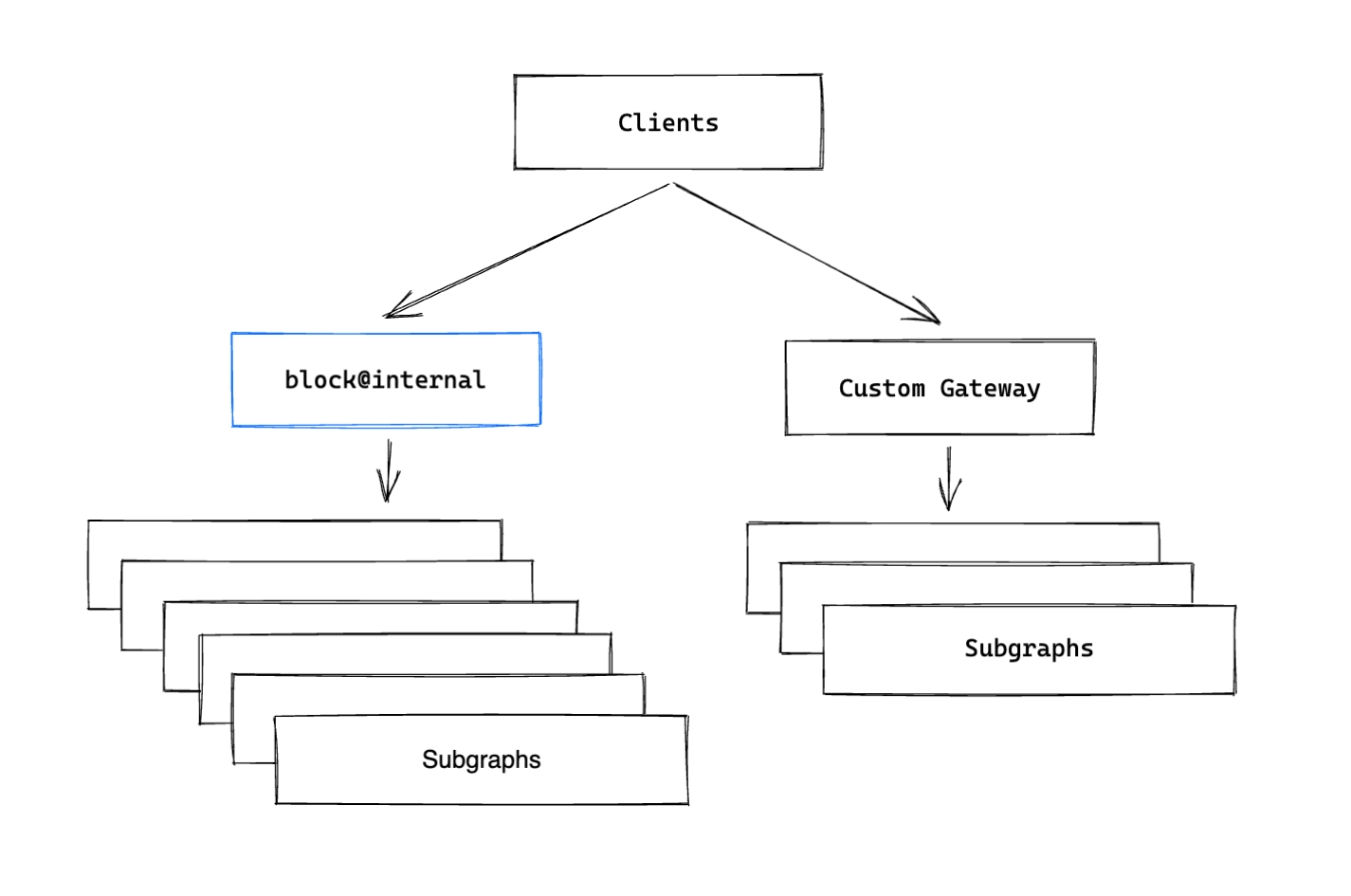
Contract Creation
The second step was to create our contract variant and tag all schema members we wanted to be included in the public API as well as set up contract configuration to create a new variant that we could serve. We used “includes” contract configuration with one value: “public-square” and tagged everything that needed to be in the public API with that value.
We also wrote a script to tag all elements of a subgraph schema with this value, to handle cases where an entire subgraph’s schema is included in the public API. A similar script developed by Apollo is now available as open source. It uses the convention that you can place a tag at the top level of a subgraph’s schema and run this command to “expand” it to all taggable elements in the schema.
New Variant Rollout
After we had our contract variant created, the third step was to create a separate cluster of our gateway service and configure it to run the new contract variant containing the schema for the public API.
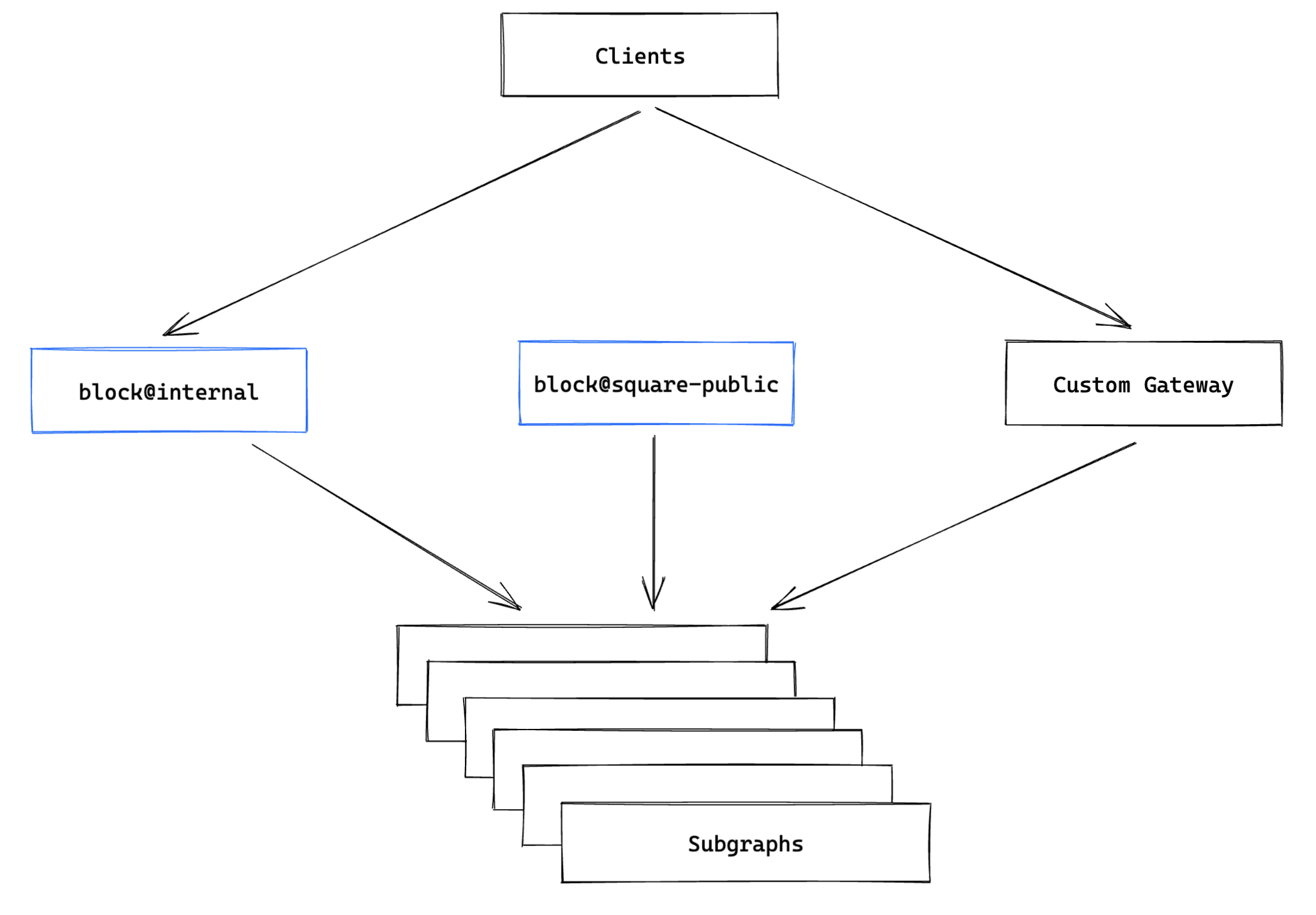
We then performed a switch to route traffic from the existing public API endpoint to this new endpoint:
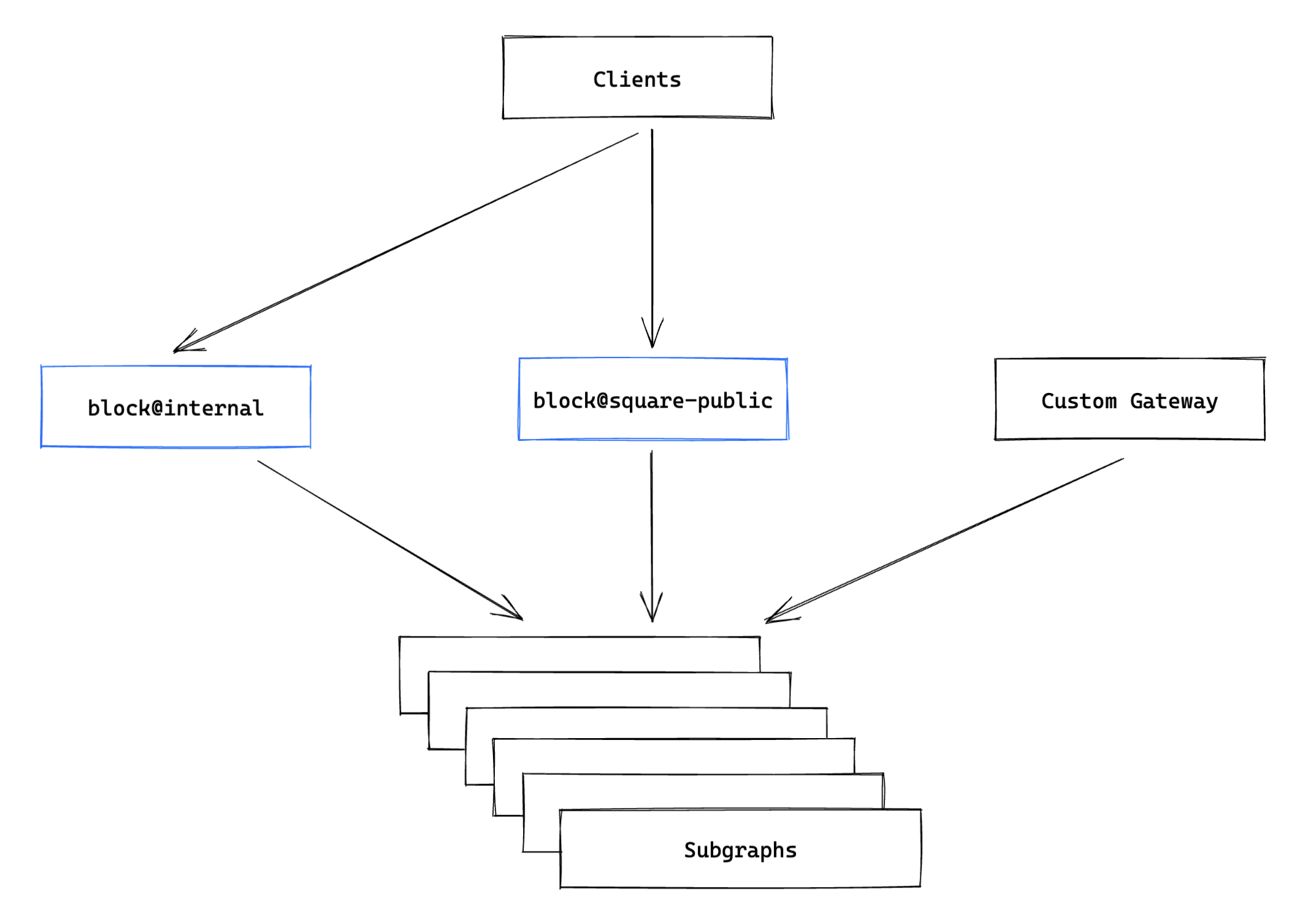
At this point, we had one supergraph with multiple variants serving these different APIs and audiences. We were then able to decommission our custom implementation of a gateway, and reduce the maintenance surface area for both our teams.
Benefits of One Graph
We find there are many benefits to aggregating all GraphQL data at our company into one GraphQL API. The biggest benefits are as follows:
- Shared Features - All effort on platform features (schema management tools, linting, etc) can now benefit every customer, regardless of what GraphQL API they work on.
- Faster Development - Less effort is required for product team engineers to serve their data to different audiences. In our case, engineers are able to add their data to the public API simply by tagging the parts of their schema they want to be public. This is easier in our experience than most other systems we have seen designed to include data in a public API. The process usually involves writing and maintaining code in a separate codebase to power the public API implementation, while with this implementation fields that overlap in both schemas can share the same exact code paths.
- Data Discovery - Having one supergraph makes it easier for people to find and discover the full extent of what is possible with the graph vs having disparate GraphQL APIs containing siloed data.
- Type Relationships - With one graph, it’s possible to create references between types in the graph even if it is not apparent from the beginning there will be connections between them. The one graph approach gives us the ability to model technically the changing relationships between important types in a dynamic, fast moving company.
All in all, we are enjoying the benefits of federated GraphQL. It gives our client applications a unified API with data available from every corner of the company. It also gives our product engineering teams the maintainability of separate, domain specific services that can contribute data to the graph anywhere in the schema.
If you develop with Square APIs and love the advantages of GraphQL (simplified client code, type safety, client-specified operations), you don’t have to wait to merge the two: Our GraphQL API is in public alpha right now! You can query for all Orders including their Catalog Line Items and Customers, all in a single query. Covering a subset of the overall APIs, the Square GraphQL API is available for anyone with a Square Developer account. You can get started here.
If you are passionate about GraphQL and want to work with us, get in touch.
Authored By
