
Expanding Secrets Infrastructure to AWS Lambda
Extending our data center to the cloud
Overview
This article describes how we extended our Data Center (DC) based secrets infrastructure to enable cloud migration supporting Lambda. We added SPIFFE compatibility to our secrets infrastructure and developed a Lambda secrets syncer that Square engineers can deploy via a Terraform module. Our design choices aim to offer the best of both worlds: easy management via an established centralized system, but cache secrets in a cloud native way so services can operate independently without being blocked or slowed down by the DC. This system is currently used in production to support systems such as Square Financial Services, a bank owned by Square that launched services recently. This content is also presented as part of a Black Hat briefings session.
Introduction
Square is in the process of moving to the cloud. To enable this migration, Square has worked on adoption of VPC endpoints, workload identity for Lambda, and other topics. To enable engineers to work efficiently, we also require managed application secrets. For context, what we mean by “secrets” for example are API keys, GPG key material, or anything custom that we would prefer to not be checked into a source code repository. In the data center we use Keywhiz to manage secrets. However, the way Keywhiz is used is very DC-centric and does not map well to serverless technologies. We had to rethink how we want to manage secrets in the future to serve our engineers best.
AWS Lambda offers great features, such as near immediate response time and scalability. Lambdas are used both for entirely new services, but also for gradual migration where a service exists in multiple environments at once (see for example Strangler fig pattern). A prime use case for Lambda are bursty workloads that have to serve hard to predict loads. In the DC these workloads would occupy servers that often go unused. Lambda can scale infrastructure quickly and transparently. However, the reasons that make Lambda attractive also pose challenges for security infrastructure.
The system described in this article is bringing Keywhiz secrets to AWS Lambda, to learn how to do this best we interviewed Square engineers about their requirements. Secrets will remain stored in Keywhiz in the data center and can be managed via existing web tooling. Syncing logic lives in AWS that updates secrets transparently for developers and caches them in Secrets Manager, so availability of secrets is not blocked on Keywhiz uptime. We created a developer experience where developers can synchronize secrets into their AWS accounts in a self-serve fashion, never blocking on a security team.
System Goals
An approach we have followed when migrating from DC to cloud is to be “as secure or better”. This is also true for functionality. We want the system to offer at least the features we provide in the DC, or better. We use Keywhiz as a baseline that we describe later in the article.
Lambda is attractive to developers, but as we quickly learned the reasons why it is attractive also make it challenging to engineer infrastructure for it. Lambda is highly scalable, both up and down. Response times after a cold start are near immediate. Since Lambda has no permanently assigned infrastructure, allocation happens on demand. Security infrastructure cannot reduce these qualities, but has to be engineered to support them.
- Basic functionality: the system has to provide secrets reliably and prevent unauthorized access
- Sharing: Secrets can be shared between services, and services can be located on multiple infrastructures (DC, Lambda, AWS EKS).
- Ease of use: Regular operation of the system should not require interaction by developers
- Resource consciousness: Requests to Keywhiz have to be engineered to prevent overloading Keywhiz, as it uses Hardware Security Modules (HSM) to encrypt secrets
- Lambda properties: the system cannot degrade scalability, response times, or availability of cloud native functionality
Keywhiz
In the DC we use Keywhiz, a Square in-house developed open source secrets management system. Ownership of secrets is mapped to microservices, where a single secret can be assigned to multiple services. Secret metadata is stored in a database, such as HMAC and ownership information. Secrets contents are encrypted using an HSM key and then stored in a Keywhiz database.
On DC server nodes we operate a system called keysync to update secrets. Keysync is a daemonset that operates node-wide. We track deployment status of services, what services run on which node to assign permissions correctly. The syncer has access to all secrets of applications assigned to the node and assigns permissions to local services.
Keywhiz has multiple endpoints, for this system we use a list operation to describe all secrets metadata that is available to the requesting service. We use another endpoint to retrieve the contents of secrets. Since metadata is merely a database query, this operation is much faster. Secrets contents need to be processed via HSM, which makes them more expensive.
We also offer centralized tooling integrated in a system called “Square Console”. This allows developers to self-service adding secrets or generating GPG key material. We also notify developers of secrets that are about to expire to prevent potential outages.
System design
On a high level the described system will fetch secrets from Keywhiz in the DC, authenticating via a newly added SPIFFE API and using AWS Secrets Manager as cache. Lambda developers are not required to interact with this system directly; secrets are made available transparently for them.
This approach leverages the best of both of DC and AWS. Secrets need to be changed in a single location only and will be updated across all environments while using AWS Secrets Manager for performance as well as a reliability improvement. We restrict access to secrets with SCP and IAM policies, while our per-application identity synchronization (rather than cluster-wide or node-wide) enables us to have fine-grained control over secret access.
Centralize vs. Decentralize
We performed developer interviews at the start of this project. One request was that developers wanted to use Secrets Manager directly. While this would have solved the task at hand, decentralizing secrets entirely would have negative long term consequences.
Our centralized tooling covers functionality that is not directly available when using Secrets Manager natively. Developers would be required to synchronize secrets themselves between infrastructures for multi-tenant services. Sharing of secrets would require direct use of IAM which is error-prone if done rarely. Also expiration tracking would be missing, which is important to avoid outages.
What we decided on was a mix of both centralization and decentralization. We let developers use Secrets Manager directly for reading secrets, but we synchronize secrets for them.
The system we built resides entirely in the customer Lambda accounts which host the client Lambda that fetches secrets. The reason for this deployment model is that secrets remain only readable to the client accounts and mTLS identity does not need to be shared with a centralized account. We use Secrets Manager per account as a cache. I.e. If five Lambdas are deployed to five different accounts, each Lambda will write to their own Secrets Manager and deployed syncer.
Making secrets access finer grained: client-side syncing
In the DC we use node-level syncers with wide-ranging access on a parallel PKI. We try to improve on our existing systems while migrating to the cloud, so we approached this situation with an open mind.
Several months before this project we had implemented mTLS identity for Lambda. While the primary reason for that project was to enable mutually authenticated service-to-service communication, it also unlocked the use of service identity for infrastructure components such as secrets management. We had the idea to move away from a specialized syncer identity with wide-ranging access by building a form of side-car syncer, and expanded Keywhiz to support SPIFFE identities. Our Keywhiz changes allow every application to access their own secrets, without introducing another identity that has super powers.
We get multiple advantages from this property. A wide-ranging syncer also is a prime target for attack, by removing it we reduce the blast radius of compromised access. We also don’t have to track deploy status or operate a parallel PKI.
Architecture
Overall system architecture. From deploy to synchronization of secrets.
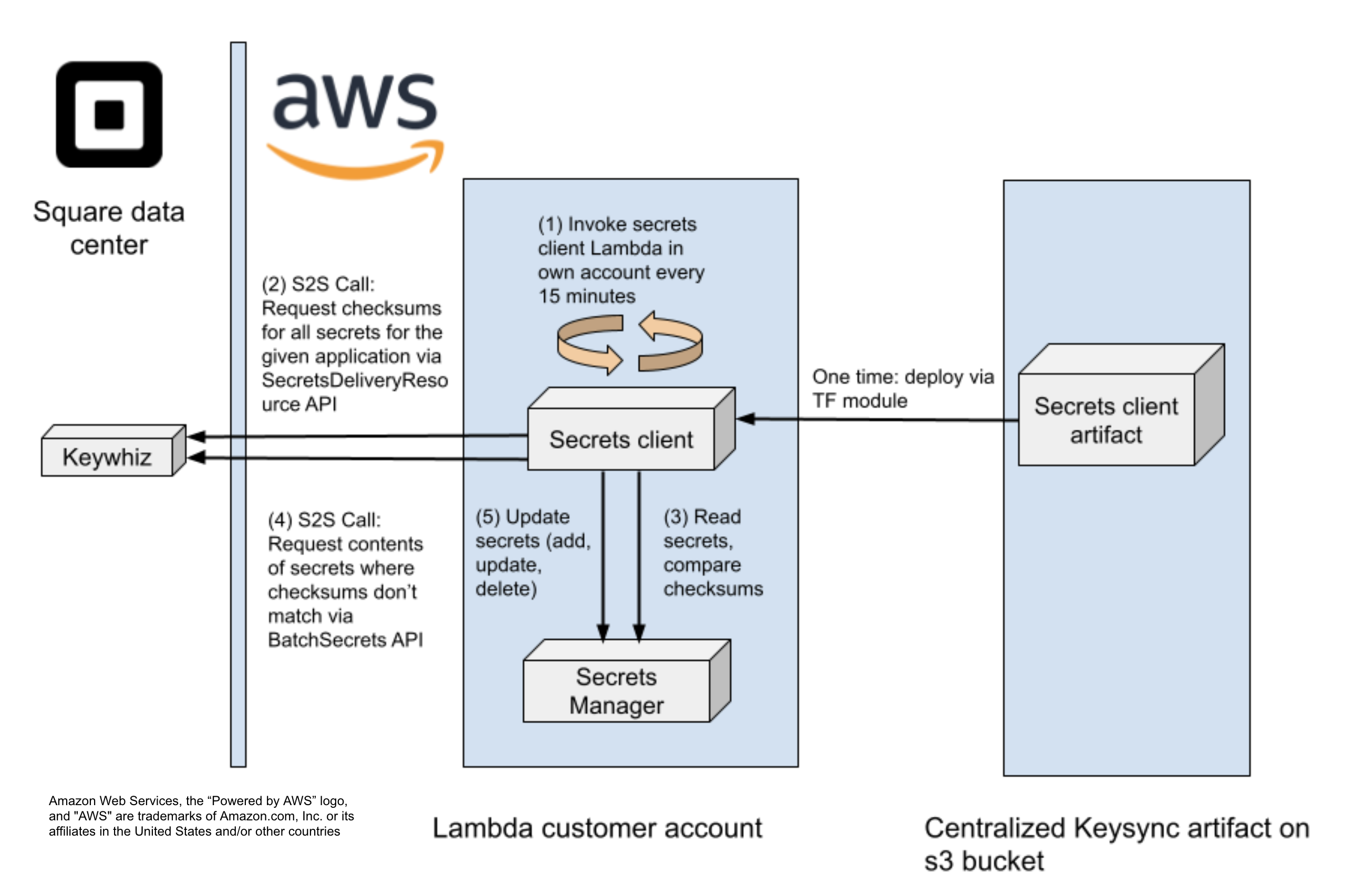
To deploy, we provide a single centralized artifact which is on the far right in the figure. The artifact is on a shared s3 bucket and we prevent modifications via object version. When operational, the syncer performs the following steps:
- The syncer is invoked on a cron schedule every 15 minutes
- When invoked, the syncer makes an mTLS call to Keywhiz in the DC. The syncer uses the service identity for this call. Keywhiz knows which secrets the service has access to and responds with metadata, secret names and HMACs
- The syncer reads secrets from the local Secrets Manager to compare with the response metadata. This is essentially a “diff” operation.
- For secrets that require updating, the syncer requests secrets contents. If no contents require updating, the syncer exits here. The majority of invocations are no-ops.
- Updates can be applied to Secrets Manager. Secrets are created, updated, or deleted.


Thundering herds
The majority of syncing requests are no-ops, as the cached HMACs match usually, which means they are merely database queries for meta data which are cheap. Querying for secrets contents however is expensive since our secrets are backed by an HSM that can represent a resource bottleneck.
Too many content requests at once could overwhelm Keywhiz; this is known as the Thundering herd problem. To address this concern we want to spread out requests. In the DC we invoke synchronization on a cron schedule and send the process to sleep randomly for up to five minutes. This approach is fine for the DC as sleep leads to no additional cost. For Lambda, invoking a process to sleep is atypical and expensive, we wanted to solve this in a more fitting way.
Cloudwatch events support two types of scheduling expressions, rate and cron. Rate would invoke a function in a configured interval based on deploy time. If functions are deployed randomly this would be sufficient. However, a re-deploy of all Lambda functions (e.g., urgent maintenance tasks) would lead to all accounts calling into Keywhiz at the same time, ruling rate expressions out.
Unlike rate, Cloudwatch cron expressions can be based on absolute time. We needed a source of randomness, but not necessarily cryptographic strength. It also had to be stable across deploys as changing an invocation trigger every time an application is deployed is unnecessary and could lead to confusing Terraform deploys.
What we picked as a solution was hashing the application name and performing MOD 15 on the result. This provides a sufficiently uniform distribution that prevents call spikes. Terraform supports sha256, but we ran into strange behavior as Terraform has returned numbers for the modulo operation that were negative or larger than the modulus. This is a bug in the math module used by TF which has since been fixed. We measured at the time that four characters were sufficient for the purpose of even distribution and did not trigger unexpected behavior.
Risk Mitigation
This section reviews security aspects of the designed system. Secrets are obviously security critical and need to be defended appropriately, and we aim to keep the blast radius low where possible.
- Access all secrets: The most high-value attack would be exfiltrating all secrets at once. Such an attack would require either compromising Keywhiz, or our identity system. Both systems are well tested and we are confident in them.
- Compromise syncer: We protect deploys by enforcing an S3 object version that is encoded in a Terraform module. Modifying the artifact would not lead to deployment of a new syncer. We also protect the CI/CD pipeline in which the artifact is built.
- Access individual secrets: Identity, We also reduce secrets exposure by using opt-in per secret; only a subset of all secrets is synchronized to AWS. Furthermore we use the default encryption key for Secrets Manager, which prevents intentional and unintentional sharing of secrets outside of account boundaries.
Cloud Cost Modeling
Cost factors for this project are Lambda execution time and Secrets Manager broken down into storage and API usage. The cost for Secrets Manager can be calculated ahead of time, but the Lambda use is better to measure. Pricing for Lambda is dependent on the number of requests, memory usage and traffic. The AWS Pricing calculator can be used to estimate the charge, we measured execution time to calculate. The scaling factors to pricing are the number of secrets and number of accounts that are kept in sync; the following subsection provides details on how to estimate Secrets Manager cost.
Secrets Manager
Pricing depends on the number of secrets and the number of API calls. The cost of API calls is $0.05 per 10,000. Syncing of secrets will require a read per secret every 15 minutes per application. For a single secret, were the secret to be checked and not written for an entire month: 24 * 4 * 31 = 2976 API requests - $0.014 per month. If a secret were to be also written every single time, the price would be doubled to $0.028. In terms of storage, the cost is $0.40 per secret per month per region, for this system storage cost is higher than API cost.
Conclusion
In this article we describe how we extended our existing DC based secrets infrastructure to support AWS Lambda. We built a synchronization system that preserves the DC as a single source of truth, while providing cloud-native access and reliability for developers. We extended Keywhiz to support SPIFFE identity and grant secrets access per-service. We reduced blast radius by avoiding wide-ranging syncer identities, and used opt-in before syncing secrets automatically. The system is in production use, including Square Financial Services.
Acknowledgements
This project was developed in close collaboration with early adopters at Square Financial Services. On the Infrastructure Security team Jesse Peirce and Will McChesney collaborated on the wider Secrets Syncing project, and the wider Infrastructure Security team as well as Cloud Foundations has contributed through thorough design reviews.
Authored By



