
DependenTree, Graph Visualization Library
Visualize dependency graphs at scale
DependenTree is a visualization library that allows users to visualize large dependency graphs as a tidy tree. It is built on top of D3.js.
At Block, we have over 14,000 ETLs. Understanding the data lineage of any given ETL was a tedious task. This involved a combination of gathering information about an individual ETL and examining source code. Previous attempts to visualize this data quickly ran into scale challenges.
DependenTree was developed to solve these problems. It’s designed to represent any type of hierarchy data. It supports viewing both upstream and downstream dependencies, it handles cyclic graphs, and it has an easy to use API allowing developers to create diagrams quickly.
Why a Tree Instead of a Graph?
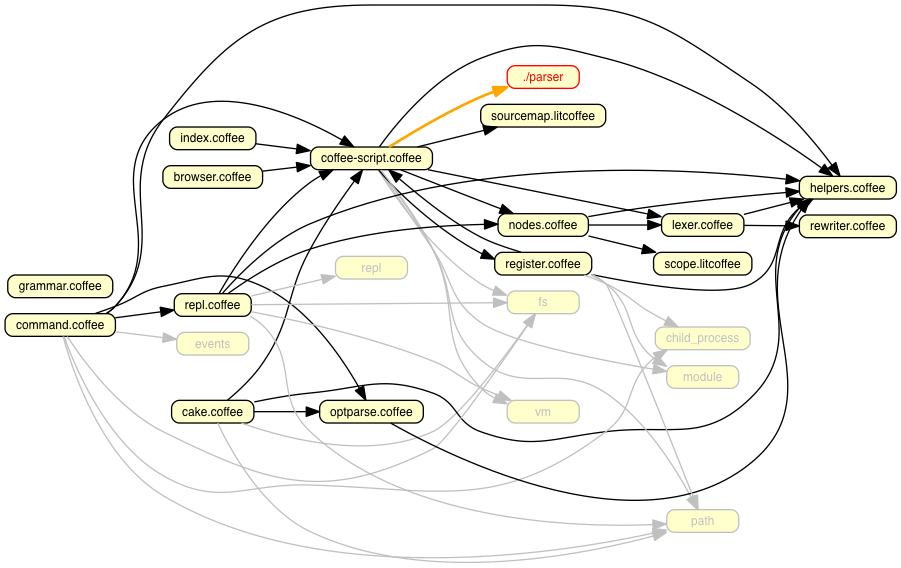
The image above represents the dependency graph of files in the CoffeeScript compiler. This visualization is made with Dependency Cruiser. This is a useful diagram, but it’s easy to get lost trying to follow the lineage of just one or two paths. It's not obvious at first glance what the relationships are from the root file “command.coffee” and all the others. This becomes only more complicated once the number of nodes in a graph increases. I like to call this the “too much information” problem.
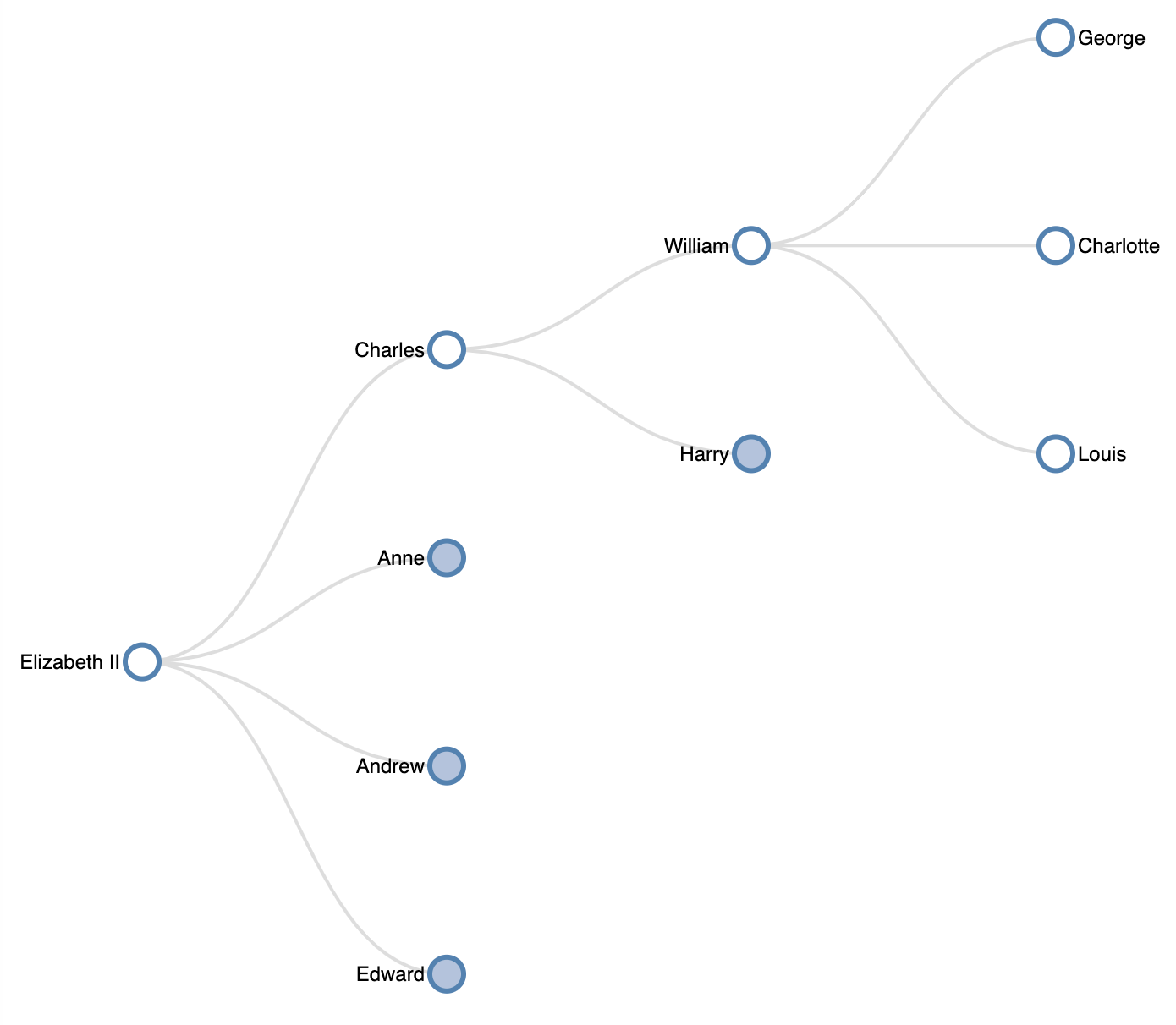
Representing the graph in a collapsible tree format allows the user to see just as much information as they want. Using a tree lets the user focus on a single node, the root, and its direct dependencies. A collapsible tree lets users expand branches as they see fit without being overwhelmed with information.
In the tree above, we can focus on the line of succession when examining the British Royal Family and ignore the rest. Sorry, other royal family members.
Technical Challenges
Mapping Relationships
In the early stages of this project, we naively tried to generate every ETL’s upstream and downstream dependency tree and store them in JSON string form. We started with only mapping a fraction of our total ETL relationships; this generated a JSON payload of 100mb. Mapping every ETL table’s relationships to other ETLs is a factorial O(n!) space operation. Getting to our full scale of 14,000 tables would likely generate a payload far too massive to pass from server to client.
The solution was to create the dependency mappings on the client-side. We collected every ETL’s first level of dependencies represented as strings and created a JSON output. Once the data was parsed on the front-end, we replaced each string with a pointer.
JSON generated on server-side
{
a: { _name: ‘a’, _deps: [‘b’] },
b: { _name : ‘b’ }
}
On the client-side, the JSON is mapped
{
a: { _name: ‘a’, _deps: [ pointer-to-b ] },
b: { _name : ‘b’ }
}
We also simultaneously create the downstream dependency relationships by inverting the relationships on a separate map. With this new approach, we were able to represent our full set of ETL lineages with a JSON payload only 5 mb large.
Handling Scale and Cycles
The d3.tree() algorithm that maps the tidy tree node coordinates requires traversing the entire input tree. Though the payload is now a manageable size, traversing the nodes in the graph from the root was still an operation with a quadratic O(v² + e) time complexity, where v represents the number of nodes and e represents the connections. When trying to display larger dependency trees, my browser tab would frequently crash. Once, I was lucky enough to see an “out of memory” error in the console which gave me a clue as to what was happening. The repeated invocations of the traversal algorithm was causing a stack overflow.
In addition to the large graph size, the d3.tree traversal method also didn’t have logic to catch dependency cycles, which our ETL table relationships have. This led to infinite loops which also caused stack overflows.
The solution here was to limit how far the d3.tree method traversed the graph. I wrote an initial traversal algorithm to find nodes in the graph that met one of two conditions: Is this node depth too far from the root note? Does this node have a cycle?
Once one of these two conditions are met, we clone the troublesome node. The only difference between the original and the clone is a lack of further dependencies. We then move the pointer from the troublesome node to the clone. Whenever we want to create a new tree, we reset the graph by deleting the clones and setting the pointer back to the original node.
Before
graph = {
a: { _name: ‘a’, _dep: [pointer-to-b] },
b: { _name: ‘b’, _dep: [pointer-to-c] },
c: { _name: ‘c’, _dep: [pointer-to-a] }
}
After
clones = {
a: { _name: ‘a’ }
}
graph = {
a: { _name: ‘a’, _dep: [pointer-to-b] },
b: { _name: ‘b’, _dep: [pointer-to-c] },
c: { _name: ‘c’, _dep: [pointer-to-clone-of-a] }
}
Picking the node depth at which to cut the tree off is a tricky problem however. More can be read about the specifics in the documentation.
Exploring Animation With HTML Canvas Graphics
D3 diagrams are built with Scalable Vector Graphics or SVGs. SVGs are easy to render and manipulate in the browser. But eventually, SVGs will run into scale challenges and drop frames. Test out the animation below on your own browser.

Appending SVGs vs Drawing on the Canvas
The process of adding a tree node to the page with SVG has a few steps outlined below. A quick timing test on my browser shows that this process takes 2,005 microseconds, or 2 milliseconds, to create each node.
| Task | Microseconds |
|---|---|
| Creating several SVG elements in memory | 2000 |
| Setting these coordinates as properties on the parent SVG element | 0 |
| Appending these SVG elements to the page | 5 |
| Total | 2005 |
To try and prevent frames from dropping, I explored using HTML canvas graphics. The canvas does not have a DOM the way regular HTML elements do. Instead, the images are made by “drawing.” These drawings are not tied to any objects in memory, they are simply pixels. For this reason, there are fewer steps needed to add a node to the page. A timing test on my browser returns 25 microseconds, or 0.025 milliseconds.
| Task | Microseconds |
|---|---|
| Draw the node on the canvas | 25 |
| Total | 25 |
Each of these operations is done once for each node displayed on the tree. The results of this test showed that at least in theory, animating with canvas is faster.
SVG vs Canvas, Performance in Practice
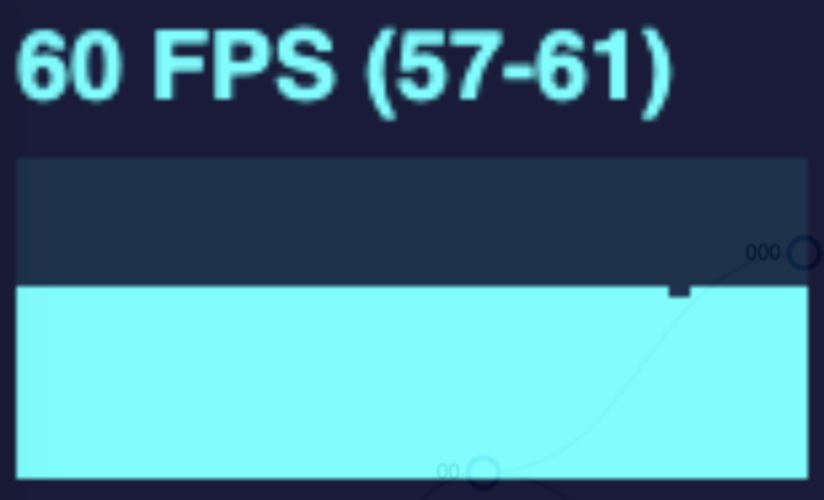
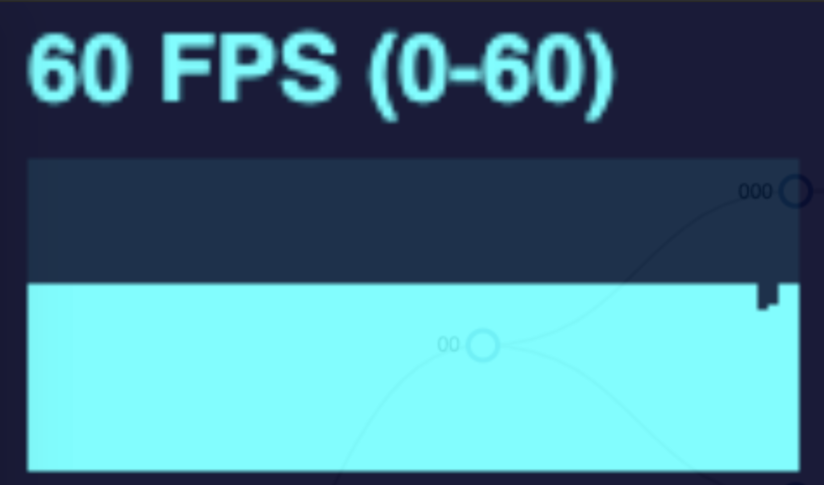
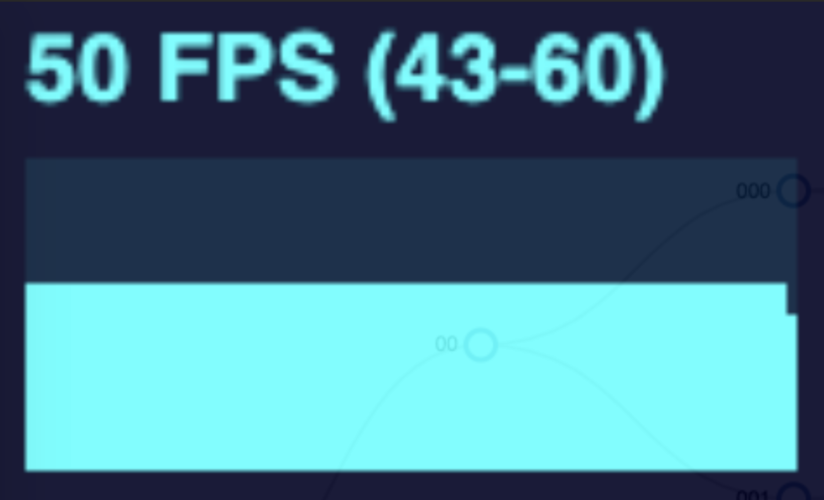
As I implemented and explored canvas animation in my diagram, I learned that there were still limits and some tradeoffs. In the gif above, we are expanding the tree at a rapid rate. The more nodes in the tree, the more frames are dropped. I conducted this same test with both a SVG and a canvas tree measuring the frames per second during the animation. See the performance graphs below.
| Number of Nodes In Tree | SVG | Canvas |
|---|---|---|
| 32 | 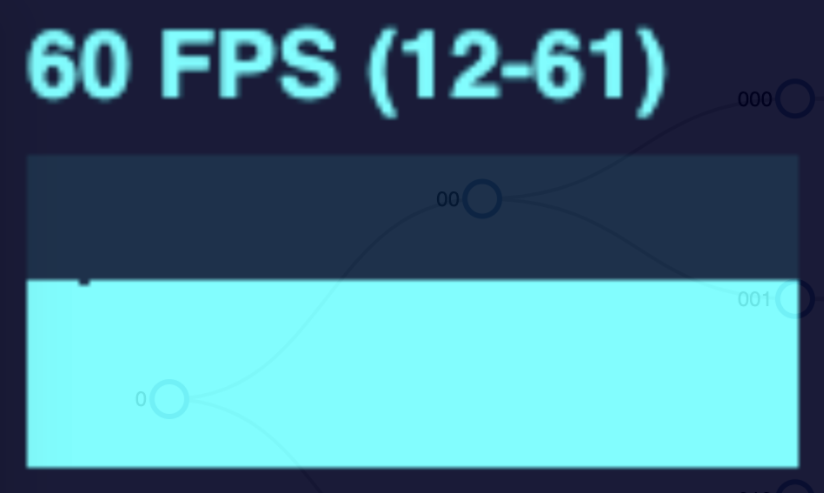 |
 |
| 64 | 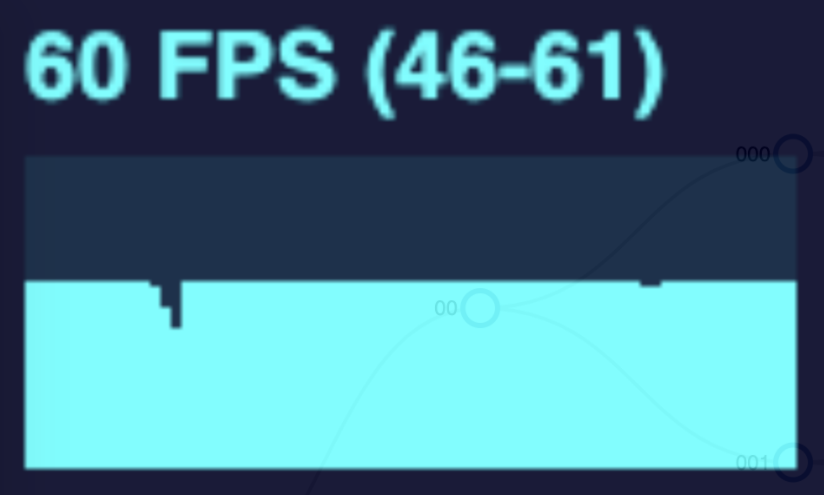 |
 |
| 128 | 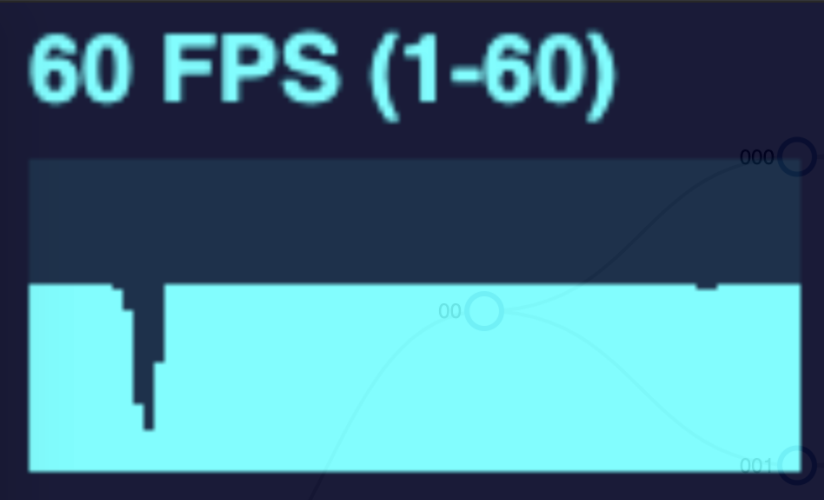 |
 |
| 256 |  |
 |
| 512 | 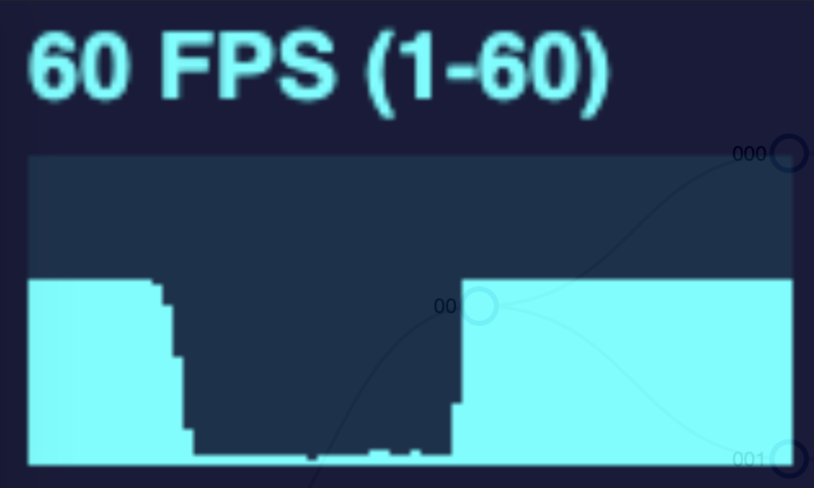 |
 |
| 1024 | 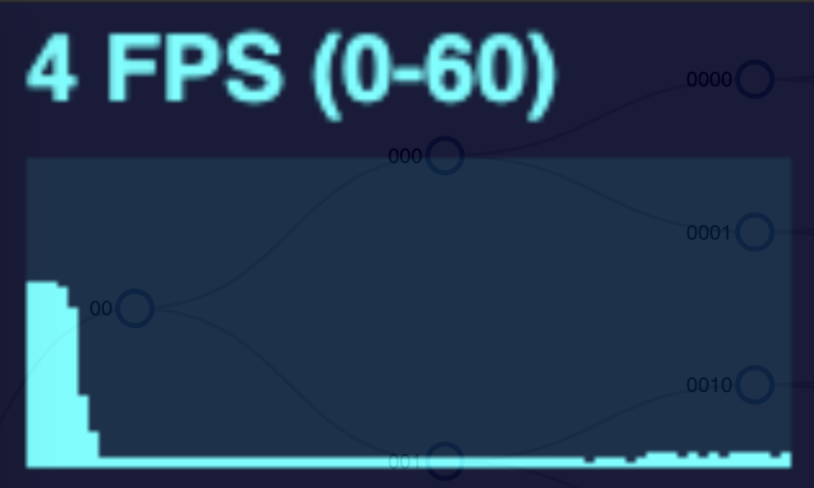 |
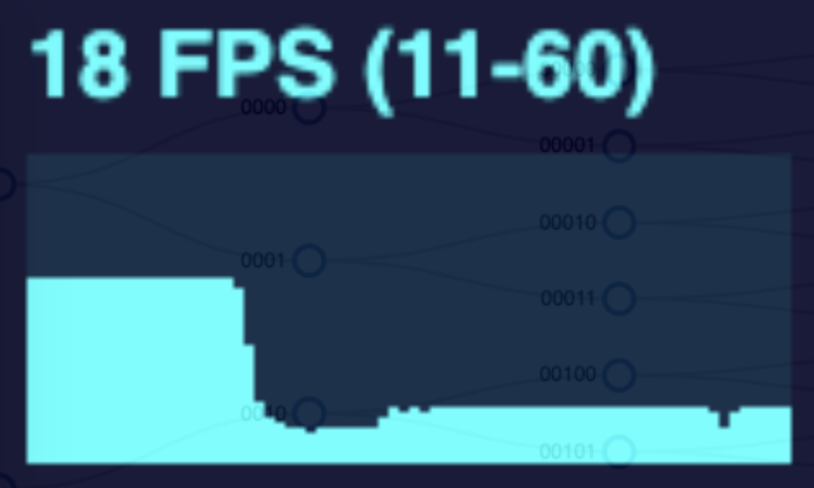 |
The SVG animation noticeably drops frames when the tree changes for the larger trees, but returns to normal when the animation is complete or at least when the number of nodes moving at once reduces.
Doing this same test but with a canvas drawn tree will drop fewer frames overall, but the frame rate declines and remains low when more nodes are drawn on the page. This is due to the canvas animation method. To simulate movement, the canvas works the same as a video. It is simply a series of photos shown in rapid succession. This is achieved by drawing the canvas, wiping it, and drawing it again but with each moving node in a slightly different position. This happens many times per second. However this wipe and redraw still occurs even when the nodes are not moving. So the higher the number of nodes in the tree, the more drawing operations that have to occur in perpetuity.
The effectiveness of canvas forms a bell curve. Animating a small tree makes no noticeable performance difference; a medium tree with canvas will yield better performance; but a large tree will end up being worse!
Sticking with SVGs
Another difficulty with animating with canvas was the need to mimic d3’s enter, update, and exit animation cycle. D3 transitions SVG elements and their positions for the developer; this logic is abstracted away. Attempting to recreate this cycle with a diagram that changes so frequently proved to be very challenging. I only managed to develop a rough prototype for my testing purposes.
With the canvas effectiveness bell curve discovered and thinking about the painful amount of problem solving still needed to get the animation fully working, I decided to abandon this approach. I was reassured by remembering the purpose of this library: not giving the user too much information. It’s unlikely that users will have more than a few dozen nodes on a page moving at once. The user will only be expanding the tree one node at a time.
Additional Resources
DependenTree links
These collapsable tidy tree diagrams is what I based my D3 code off of:
Blogs about converting D3 animation to canvas that heavily informed my work. Both blogs go into detail on how this is done:
- Learnings from a d3.js addict on starting with canvas by Nadieh Bremer
- Working with D3.js and Canvas: When and How by Irene Ross
A great talk on animation performance
Authored By
