
Connecting Block Business Units with AWS API Gateway
Secure cross-mesh communication using in-mesh bastions
Overview
When Block acquires another company, we often want to integrate backend services to benefit from each others’ technology. For example, one can imagine an acquisition wanting to leverage internal APIs, such as Block’s internal payments stack. A naive integration proposal might be to put both companies on the same network and PKI infrastructure. Of course, this is easier said than done. Further, there are infrastructure engineering, security, and privacy reasons for stricter isolation.
At Block scale, acquisition integration is an ongoing effort. To enable business goals at Block's velocity, we require reusable design patterns. In this article, we explore how Block onboards acquisitions within weeks rather than months.
We've created infrastructure within Block's AWS environment that we call Farcars. Farcars enable acquisitions to call into Block service mesh by seamlessly translating from aquisition-native identity semantics to Block-native mTLS. From the perspective of services within Block's internal mesh, acquisition connections are first-class participants, enjoying identical authn/authz semantics. Acquisition services make SIGv4 calls with their existing IAM roles into an AWS API Gateway, which handles identity translation. The system is in production for Afterpay and Tidal while we are rolling it out to other business units.
Introduction
Internally at Block, we often refer to the company as an “ecosystem of startups.” For example, Square and Cash App each operate their own service mesh. For acquisitions such as Afterpay, TIDAL, or Weebly, we are tasked with the integration of novel infrastructure. As more companies could join in the future, it is important to be able to onboard new acquisitions to our service mesh in a fast and secure manner to enable business value.
Block has been using mTLS to provide identity to workloads and secure its internal network for over a decade. We migrated to SPIFFE-conforming identities in the past four years and have been using SPIFFE as a standard for mTLS authentication throughout the company. Block's Traffic team provides Envoy sidecars, which abstracts away mTLS internals from service developers. To issue mTLS credentials, we use a combination of SPIRE and internal systems that build on top of AWS Private CA which we have written about previously here.
Acquired companies can use different technology stacks and clouds. We anticipate the possibility that an acquisition's security posture might range from manually managed passwords to a curated cloud native solution. We want to extend our service mesh offerings to these new business units while maintaining a security standard, without requiring acquisitions to completely align with Block infrastructure. As Block is made up of many building blocks, such a solution has to overcome scalability hurdles. To see how we did that, keep reading!
Challenges
The goal of this project was simple: join two companies in a way that their backends work as if they were part of a single company. Ideally we want to cause as little work in an acquisition as possible, as infrastructure work can displace product work. To achieve this goal however we had to overcome a set of challenges that we will line out in this section.
From an organizational perspective, Block operates teams specifically for Cryptographic Identity and Traffic, whereas most companies especially if they are smaller don’t. However, Block is also unfamiliar with the ins and outs of infrastructure within newly acquired companies. While we can deliver specialized expertise, we might not be able to support operations within infrastructure we are not familiar with. Implementing a solution acquisition-wide in less familiar infrastructure is a risky undertaking, changes there should be minimal and performed by engineers familiar with the acquisition infrastructure.
Another aspect here is scalability, while deploying to a different AWS organization is complicated logistically it is also less scalable than deploying to the Block environment where we can be more flexible in our operations. Consider for example operating in five different infrastructures vs. operating five different configurations of the same mediating infrastructure. If this is not concerning enough, make that number 20. As a result, we decided that infrastructure to support acquisitions should live within the parent company and be offered as a service to acquisitions.
Scalability is also a concern in terms of engineering time spent to enable new acquisitions and services. Infrastructure to support new acquisitions is not a problem to solve only once as there could be more companies joining. A solution has to be general enough to be reusable with different companies using different technologies, otherwise we would risk to perform the same engineering exercise every time we acquire a new company, which is not acceptable. We were very much interested in creating a pattern that provides a paved road for onboarding future acquisitions.
Companies rarely operate in a single programming language. We use multiple languages which operate within different internal frameworks that provide access to underlying infrastructure. This was another scalability concern, as we don’t want to only support some frameworks and not others. Also, new frameworks could be added later, which could mean future updating work and increases the debugging surface. Ideally we would support them all at once and not require future work. The common language of our backend services is mTLS over Envoy, by solving for Envoy we would enable widespread support for acquisitions to connect without large overhead per-service. The same holds true for acquisitions, invasive changes to the entire software stack within a newly acquired company to enable service to service calls are too expensive and not an option worth considering. We want the changes on the acquisition side to be minimal.
Meeting these challenges drove the architecture of our system. We decided that on both ends we want to support calls in the native environment, and do so by enabling translation between services on an infrastructure level. Concretely, calls into the Block service mesh have to be terminated in Envoy. If Block services are able to trust acquisition traffic coming out of Envoy, no novel work in services is necessary and we can operate with high developer velocity. Furthermore, the infrastructure to do such translation should live within Block where our infrastructure teams can operate them in a scalable manner for all acquisitions that want to connect.
Providing infrastructure vs. providing raw certificates
One idea for solving these challenges is handing out certificates and letting the acquisition handle the details. Such a cert vending machine approach works in constrained settings but is not a good pattern to follow for integration of new companies.
Initiating and terminating TLS is a known source of problems that we see large infrastructure teams better equipped to perform at scale than most startups. There are many problems to encounter, whether it is updating the trust bundle regularly, relying on the "m" part of "mTLS" being implemented correctly, upgrading protocols, or that crypto libraries are up to date. If we are able to handle this in a fashion we control across all acquisitions this would avoid a set of pitfalls.
Other than preventing these problems, centralized management and abstraction of identity can make for a better developer experience, ideally we strive for an “easy mode” where developers should not be concerned about PKI. For example, Envoy includes logging and abstracts identity details away from developers, and keeps us flexible if we want to add another supported programming language later. We wanted to provide a similar experience to acquisitions.
System Design
Taking into account our challenges helped us see a general system direction. We wanted the system to be compatible with our Envoy service mesh on the Block side, while compatible with what an acquisition uses on the other side.
What we built we refer to as “serverless proxy,”, the approach integrates with the mTLS service mesh on one side, while providing ingress constrained by IAM on the other. We believe that this approach provides the best of both worlds without compromising service-level identity granularity nor over-burdening either side with complex integrations. The serverless proxy contains an Envoy proxy in a docker container running in AWS Fargate, fronted by AWS API Gateway in proxy mode. We refer to the container as “Farcar” rather than “sidecar”. It is farther away from the originating workload than a sidecar would be, but also because it runs in AWS Fargate.
For workload isolation purposes we introduced a new AWS account per-acquisition per-environment (staging, production, …) within the Block AWS organization. Within these proxy accounts we issue SPIFFE mTLS credentials per Farcar that represents an acquisition service. This allows Block to maintain full control over the account and ingress calling controls on API Gateway. It also doesn’t burden an acquisition to port their software into our organization as a requirement. While this approach is built with AWS in mind, acquisitions operating in different clouds can also call into API Gateway, given network connectivity and IAM credentials, for example by using IAM Anywhere. We believe this solution is general enough to solve for most acquisition use cases. This system is implemented as a Terraform module.
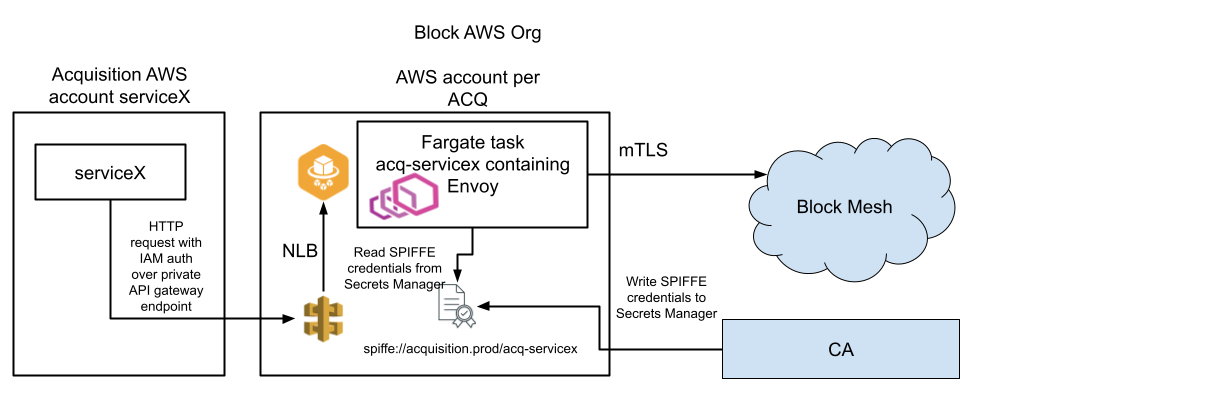
System architecture. API Gateway and Fargate task for all connecting workloads per acquisition. We create a new Fargate task per acquisition workload that can connect to Block. Custom mTLS credentials are issued by a Block acquisition CA.
Our architecture is reusing established security methods: we have a model for workloads to call from AWS into the DC via mTLS that is well tested. To call from an acquisition account X into the acquisition proxy account we establish IAM controls. The proxy accounts are created within the Block AWS Organization and owned by Block infrastructure teams. We deploy a Fargate task per acquisition service and front them with one NLB per acquisition service. The proxy AWS account is only reachable from a special acquisition VPC to not expose access to our Fargate tasks.
API Design
We use a single API Gateway for each proxy account to ingress traffic from an entire acquisition. On the API Gateway we configure one path per acquisition service. For example for services X and Y we would configure /X/* and /Y/*. These paths are restricted to be accessed only by IAM roles tied to X and Y respectively. To call Block service Z endpoint “foo” within the Block service mesh from X, service X has to create a SIGv4 request to API Gateway with path “/X/Z/foo”. We remove the leading “/X/Z” and pass on the request. The resulting request is equal to what Block internal services would send. Effectively the acquisition service can communicate with a Block service the same way as services communicate internally to Block.
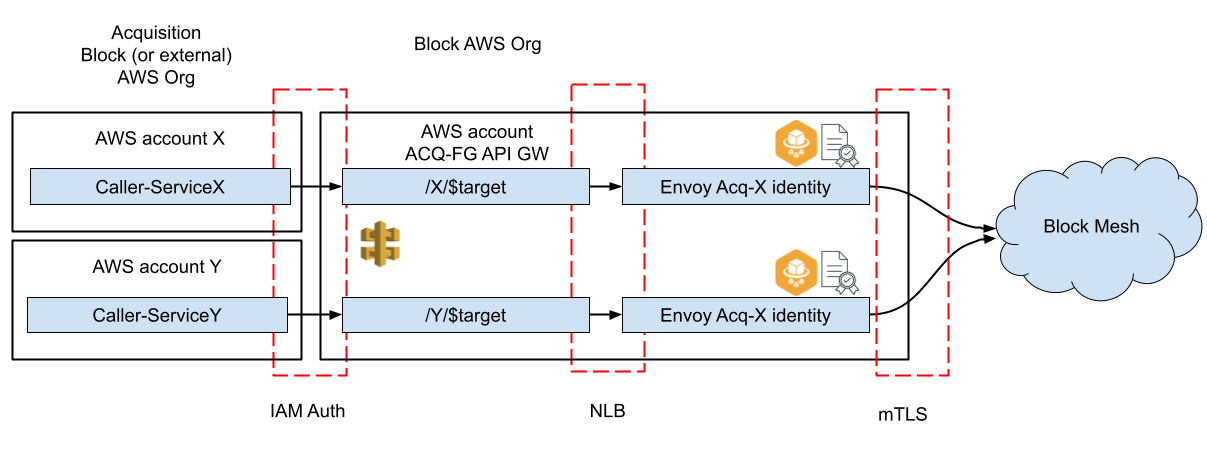
API structure. We deploy an API Gateway in a proxy account that we create per acquisition per environment. Within that API Gateway we tie paths to originator identity to lock down IAM permissions. I.e. if service X wants to call into the Block mesh, API Gateway would require path /X/* to allow calls.
Identity Semantics and Security
Block maintains an “Identity Governance and Administration” (IGA) system that acts as a registry for all workloads operating across the company. As a requirement to use the serverless proxy acquisitions need to onboard to this system. Our IGA system has context whether workloads are part of an acquisition and can issue certificates in a corresponding format and make them accessible to the Farcar workloads. These certificates are issued with a SPIFFE URI SAN.
To preserve identity semantics it is vital to keep a 1:1 mapping throughout the system. A critical component is the relation between API Gateway and the Fargate tasks containing Envoy; anything that can talk to the Fargate task will be able to act on behalf of these acquisition services. This behavior stems from the fact that an NLB cannot have an associated security group. – Isolating the NLB was a priority for the network design. If the NLB were on a widely shared VPC, anything on that VPC could talk to the NLB and assume the role of any acquisition service we are trying to secure. To prevent unwanted access to the Farcars, acquisitions connect to execute-api (API Gateway) from a specific per-acquisition VPC within the Block Organization.
Overall, we are reusing tried and tested methods that we have been relying on for years. By issuing mTLS identity into AWS accounts within our Block AWS organization and isolating Fargate access we maintain service-level granularity. mTLS connections are established through Envoy. Security is provided by limiting access to the proxy account to Block infrastructure teams and monitoring closely. As a result, we transparently enable cloud-native workloads to operate in a way that is compatible directly with our mTLS service mesh.
What about the other way?
To enable service-to-service calls from acquisitions into Block we accept signed calls into an API Gateway where we translate the call to mTLS in an Envoy “Farcar”. In the reverse, to support calls from the Block organization into acquisitions we use the same system, but have to generalize it. We already have capabilities to let workloads assume IAM roles and can call API Gateway directly. On the side facing the acquisition we use Farcars in a similar fashion as we described earlier, but rather than use mTLS automatically we encapsulate logic for workload identity native to the corresponding acquisition, which may or may not be mTLS. We need to be flexible to support different service environments. As a hypothetical example, if an acquisition was to use a custom signature scheme, we could implement that in a Farcar to abstract it away from services operating in Block. We enable services across all languages so long as they can call API Gateway.
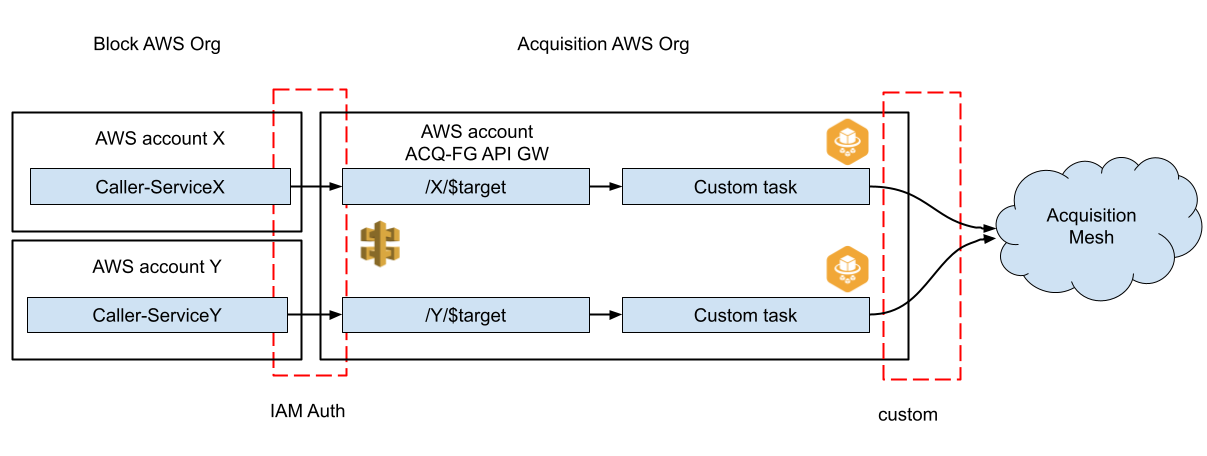
Block calling into acquisitions. We use IAM auth the same way as acquisitions calling into Block. The proxy account lives in the acquisition AWS organization. We generalize the fargate task using a custom image that we can adjust to the acquisition environment.
AWS API Gateway wishlist
While API Gateway solves many problems for us, one big downside is the lack of gRPC support. In its current form API Gateway only allows for HTTP/1.1 which means requests and responses need to be translated to JSON, combined with a maximum response size of 10MB. While we have a JSON-to-proto bridge for services, this needlessly impacts performance and prevents us from streaming responses. We eagerly await to provide HTTP/2 to our clients should API Gateway enable support.
We are happy with API Gateway overall. However, we hope that future improvements will make the service even better and support wider use cases.
Note: We are aware that we could switch to other AWS services to overcome a particular limitation of API Gateway. However, we haven't found any existing AWS offering that would provide the full spectrum of functionality that we needed and we want to avoid any architectural rewrites that would deliver a partial solution.
Conclusion
Connecting backend services in an acquisition scenario is a challenging process that can take companies months. We discussed here a technical solution to onboard acquisitions to connect within weeks and allow acquisitions to join the service mesh securely and call workloads in Block as if they were part of the Block service mesh themselves.
Our solution uses API Gateway to translate IAM credentials into an mTLS connection that we transparently provide via an Envoy proxy running in AWS Fargate. We used that pattern successfully to onboard multiple acquisition production systems already and have a few more integrations in the pipeline.
Acknowledgements
This project required wide collaboration across infrastructure teams and close collaboration with engineers in acquired companies, specifically Afterpay. Thank you to the Traffic team, Network Engineering, and AWS Security. Note: If this kind of work is interesting to you, see our careers page for open roles in our InfoSec team.
Authored By

