
Challenge — Table of Contents Generator
Introducing developer challenges! This is a new series where we post challenges inspired by real world applications.
While solutions are present later in the article, we encourage you to give the challenge a try first! We’ll be highlighting the top solutions we get over on Twitter at @SquareDev.

The Problem
 Questions questions, we’ve got a question.
Questions questions, we’ve got a question.
Given an HTML page with multiple headers, we want to extract the headers to make a table of contents:
<h1>Main title of the page</h1>
<h2>Sub title</h2>
<p>Some text content</p>
<h2>Another sub title</h2>
<p>description</p>
<h3>Sub sub title</h3>
<p>sub description</p>
Now what we optimally want is to extract a table of content from this list. For now we can just start with an unordered list:
<ul>
<li>Main title of the page
<ul>
<li>Sub title</li>
<li>Another sub title
<ul>
<li>Sub sub title</li>
</ul>
</li>
</ul>
</li>
</ul>
This, put above our content, would look something like this:
 The apex of HTML styling. Beautiful.
The apex of HTML styling. Beautiful.
So given a page, the goal is to give back an unordered list representing a table of contents for it.
Give it a try!
Want to give it a try? Here are some basic specs in Ruby using RSpec to start:
require 'rspec/autorun'
def header_hierarchy(html)
raise 'Implement me!'
end
describe '#header_hierarchy' do
context 'EASY' do
it 'can extract a single header' do
fragment = "<h1>Foo</h1>"
result = '<ul><li>Foo</li></ul>'
expect(header_hierarchy(fragment)).to eq(result)
end
it 'can extract one nested level of header' do
fragment = "<h1>Foo</h1><h2>Bar</h2>"
result = '<ul><li>Foo<ul><li>Bar</li></ul></li></ul>'
expect(header_hierarchy(fragment)).to eq(result)
end
end
context 'MEDIUM' do
it 'can extract multiple levels of nested headers' do
fragment = "<h1>Foo</h1><h2>Bar</h2><h3>Baz</h3><h4>Bam</h4>"
result = '<ul><li>Foo<ul><li>Bar<ul><li>Baz</li></ul></li></ul></li></ul>'
expect(header_hierarchy(fragment)).to eq(result)
end
end
context 'HARD' do
it 'can extract multiple nested headers in multiple branches' do
fragment = "<h1>Foo</h1><h2>Bar</h2><h3>Baz</h3><h2>Bam</h2><h3>Ba</h3>"
result =
'<ul><li>Foo<ul><li>Bar<ul><li>Baz</li></ul></li><li>Bam<ul>' +
'<li>Ba</li></ul></li></ul></li></ul>'
expect(header_hierarchy(fragment)).to eq(result)
end
end
context 'LIVE - Integration' do
# Version of HTML when tutorial was created: https://gist.github.com/baweaver/4214ea2f1f203e8f5eaf9445b6d9eec8
it 'can parse an entire document' do
require 'net/http'
fragment = Net::HTTP.get(URI("https://jquery.com/"))
result =
'<ul><li>jQuery<ul><li>Lightweight Footprint</li><li>CSS3 Compliant</li>' +
'<li>Cross-Browser</li></ul></li><li>What is jQuery?</li>' +
'<li>Other Related Projects<ul><li>Resources</li></ul></li>' +
'<li>A Brief Look<ul><li>DOM Traversal and Manipulation</li>' +
'<li>Event Handling</li><li>Ajax</li><li>Books</li></ul></li></ul>'
expect(header_hierarchy(fragment)).to eq(result)
end
end
end
With that said, let’s dive in and explore a solution! No peeking until you’ve given it a try first.
A solution
The fun part of this problem is we’re trying to take something linear and make it into something of a tree structure.
Note that our solution will not be perfectly factored, but will seek to explore a viable solution technique to this problem. We’ll leave that as an exercise to the ambitious readers.
Tree Node
 We can branch out a bit
We can branch out a bit
For that, we’re going to want to start with an idea of a Tree Node:
class TreeNode
attr_reader :parent
def initialize(tag_name, tag_text, parent = nil)
@tag_name = tag_name
@tag_text = tag_text
@parent = parent
@children = []
end
def descendant?(tag_name)
@tag_name < tag_name
end
def add_child(tag_name, tag_text)
TreeNode.new(tag_name, tag_text, self).tap do |new_child|
@children << new_child
end
end
def to_h
{ 'name' => @tag_text, 'children' => @children.map(&:to_h) }
end
def to_s(indent_level = 0)
indent = ' ' * indent_level
tag = "#{indent}[#{@tag_name}] #{@tag_text}\n"
tag + @children.map { |c| c.to_s(indent_level + 2) }.join
end
def to_html
child_html = @children.empty? ?
'' :
tag('ul', content: @children.map(&:to_html).join)
return child_html if @tag_name == 'h0'
tag('li', content: "#{@tag_text}#{child_html}")
end
private def tag(name, content:)
%(<#{name}>#{content}</#{name}>)
end
end
We want to be able to capture the concept of a header tag having potential children, and potentially a parent header.
Given a simple example, we might have this:
h1 = TreeNode.new('h1', 'Title')
h1.add_child('h2', 'Subtitle')
h1.add_child('h2', 'Another Subtitle')
Now you can add children tags freely to a header node, and there’s also a to_s and to_h method to allow us to take a look inside:
puts h1
# [h1] Title
# [h2] Subtitle
# [h2] Another Subtitle
h1.to_h
{
"name" => "Title",
"children" => [
{"name"=>"Subtitle", "children"=>[]},
{"name"=>"Another Subtitle", "children"=>[]}
]
}
We can also tell if a particular tag is a descendant of another:
h1.descendant?('h2') # => true
h1.descendant?('h3') # => true
Given this, we could raise an error if someone tries to add a child that’s not a descendent, but we’re also not going to be directly using it either.
The last thing we have in here is a to_html method, which will give us the ability to recursively generate HTML. If we run it through HtmlBeautifier, it’s a bit easier to parse from a glance:
puts HtmlBeautifier.beautify(h1.to_html)
<li>Title
<ul>
<li>Subtitle</li>
<li>Another Subtitle</li>
</ul>
</li>
But that brings up the interesting question of that h0 mention up there, and the strange lack of an outer <ul> element. There are reasons for this that we’ll highlight in the next section.
That brings us to our next part of the solution: Extracting the content.
Nokogiri
 Tag! You’re it.
Tag! You’re it.
The first step is we need to get the header tags out of the HTML we’re given. For that, we can leverage Nokogiri and the css selector:
**require 'nokogiri'**
Nokogiri('<h1>title</h1>')
.css('h1, h2, h3, h4, h5, h6')
# => [#<Nokogiri::XML::Element:0x3fd76d0be044 name="h1" children=[#<Nokogiri::XML::Text:0x3fd76c96944c "title">]>]
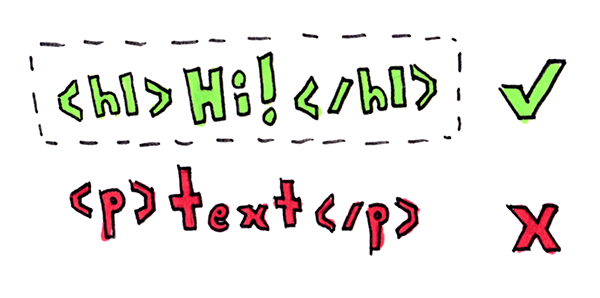 We only want to grab the header tags, everything else can be ignored
We only want to grab the header tags, everything else can be ignored
Problem is, this doesn’t work so hot with fragments:
Nokogiri('<h1>title</h1><h2>test</h2><h2>test2</h2>')
.css('h1, h2, h3, h4, h5, h6')
# => [#<Nokogiri::XML::Element:0x3fd76c9719a8 name="h1" children=[#<Nokogiri::XML::Text:0x3fd76c970e40 "title">]>]
So we can cheat a bit:
html = '<h1>title</h1><h2>test</h2><h2>test2</h2>'
Nokogiri("**<html>**#{html}**</html>**")
.css('h1, h2, h3, h4, h5, h6')
# => [#<Nokogiri::XML::Element:0x3fd76dcd40cc name="h1" children=[#<Nokogiri::XML::Text:0x3fd76e40bee4 "title">]>, #<Nokogiri::XML::Element:0x3fd76e40bac0 name="h2" children=[#<Nokogiri::XML::Text:0x3fd76e40b8f4 "test">]>, #<Nokogiri::XML::Element:0x3fd76e40b73c name="h2" children=[#<Nokogiri::XML::Text:0x3fd76e40b570 "test2">]>]
That gets us all of our headers, which means we can go to the next section: the header extractor.
Header Extractor
 Descending the nodes
Descending the nodes
Now that we have a way to get our headers, let’s combine it with the earlier TreeNode:
def header_extractor(html_partial, header_levels: %w(h1 h2 h3))
root_node = TreeNode.new('h0', 'ROOT')
Nokogiri("<html>#{html_partial}</html>")
.css(header_levels.join(', '))
.reduce(root_node) do |current_tree, tag|
current_tree = current_tree.parent until current_tree.descendant?(tag.name)
current_tree.add_child(tag.name, tag.text)
end
root_node
end
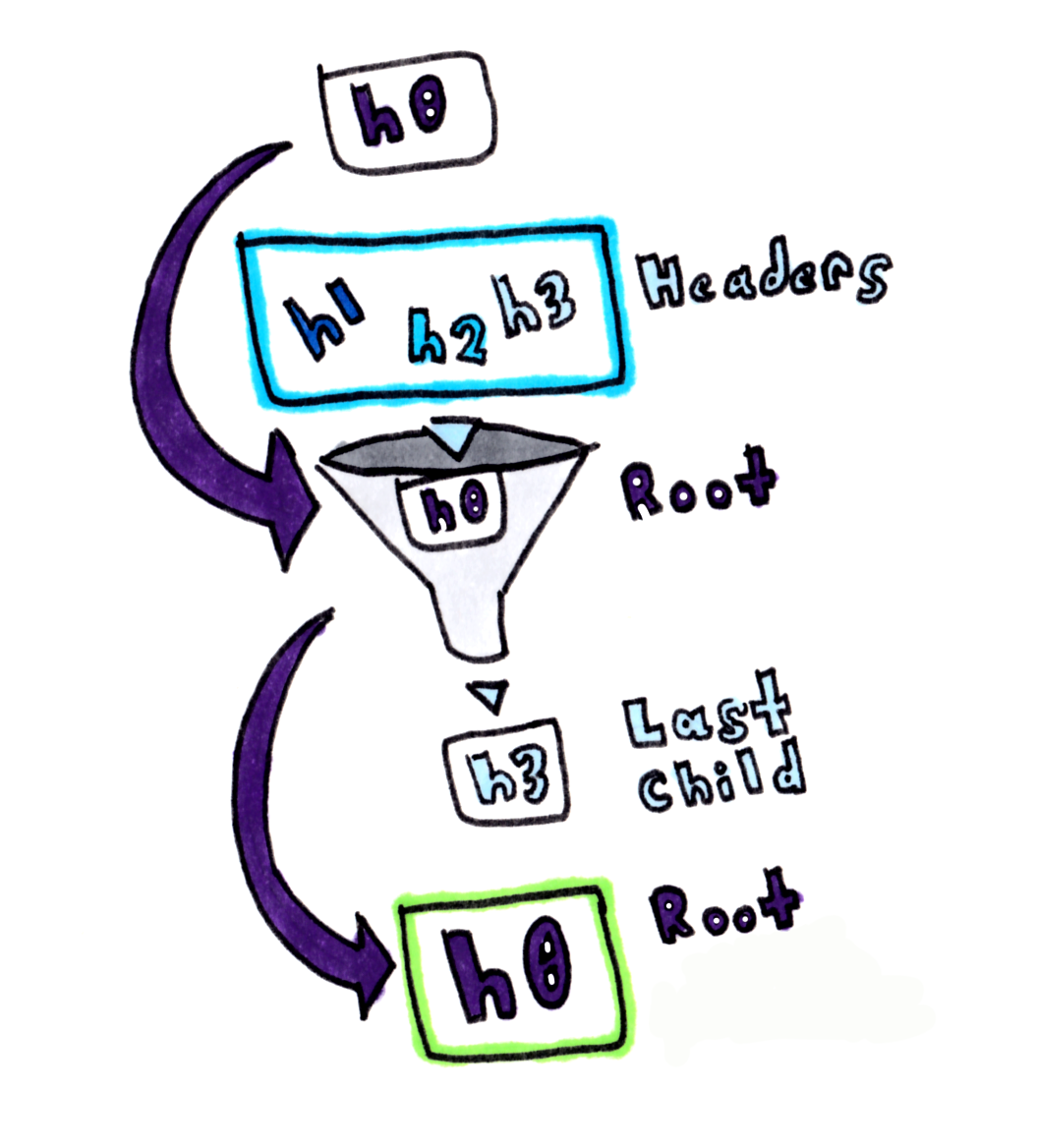 Root node goes in, children get added, and we return the root node afterwards
Root node goes in, children get added, and we return the root node afterwards
Now this one can be quite dense. Let’s break it down!
Root Node
 It’s rooting for you
It’s rooting for you
The first section defines a “root node” which we can use to capture any level of headers. There *are *cases in which there are multiple h1 tags on a page, or maybe none at all, which makes it quite difficult to make a tree. There could even be an h3 first, which makes it even more fun.
This means we have to ignore it when we’re iterating, but it affords us a lot of flexibility in relative depth. Granted it’s unusual to have an h3 take precedence over an h1 in terms of order, but that’s an exercise left to the reader and hopefully to the HTML writer doing it that way.
Nokogiri CSS
Oi, no tag backs
We’ve already seen this one, the only difference is that we’re passing the headers in as an optional argument and trimming it down to only digging down to h3.
Reducing to the Root
This is where it can get a bit interesting.
The first element is the ascent:
current_tree = current_tree.parent **until
**current_tree.descendant?(tag.name)
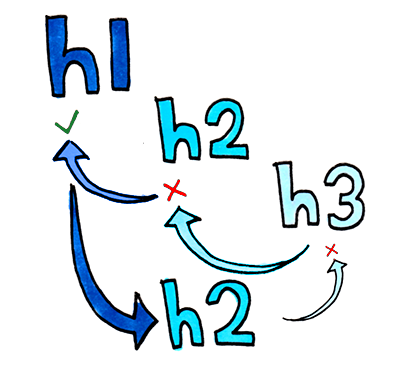 Ascending nodes until we find one which has a higher hierarchy than the tag
Ascending nodes until we find one which has a higher hierarchy than the tag
What we’re doing is going back up the tree step by step until we find a point where it’s a descendant. With the root node being the top parent, we’re assured to always have a top level that can take any tag as a descendant.
After we get to the tree we want, we add a child to it:
current_tree.**add_child**(tag.name, tag.text)
If we look back at the earlier implementation we’ll notice it returns the child, meaning that’s now our new tree. Say we have an h2 and then another h2, that means it ascends once and then adds to the parent of the first h2.
Back to the Root
…and then there was a tree! Fancy that!
Now that we’ve gone through all the headers, we just need to return the root node with all the children intact.
Given our earlier to_h methods and our earlier to_s method we could give it a try! Let’s take a look at jquery.com:
require 'net/http'
html = Net::HTTP.get(URI('https://jquery.com'))
puts header_extractor(html)
[h0] ROOT
[h2] jQuery
[h3] Lightweight Footprint
[h3] CSS3 Compliant
[h3] Cross-Browser
[h2] What is jQuery?
[h2] Other Related Projects
[h3] Resources
[h2] A Brief Look
[h3] DOM Traversal and Manipulation
[h3] Event Handling
[h3] Ajax
[h3] Books
We can see the potential fun from earlier with multiple top level nodes. This type of issue is especially prevalent when dealing with multiple fragments.
The Full Solution
 Tu too rooooo! Victory! You got 15 exp. Whimsy leveled up!
Tu too rooooo! Victory! You got 15 exp. Whimsy leveled up!
That leaves us with our full solution:
require 'rspec/autorun'
require 'nokogiri'
class TreeNode
attr_reader :parent
def initialize(tag_name, tag_text, parent = nil)
@tag_name = tag_name
@tag_text = tag_text
@parent = parent
@children = []
end
def descendant?(tag_name)
@tag_name < tag_name
end
def add_child(tag_name, tag_text)
TreeNode.new(tag_name, tag_text, self).tap do |new_child|
@children << new_child
end
end
def to_h
{ 'name' => @tag_text, 'children' => @children.map(&:to_h) }
end
def to_s(indent_level = 0)
indent = ' ' * indent_level
tag = "#{indent}[#{@tag_name}] #{@tag_text}\n"
tag + @children.map { |c| c.to_s(indent_level + 2) }.join
end
def to_html
child_html = @children.empty? ?
'' :
tag('ul', content: @children.map(&:to_html).join)
return child_html if @tag_name == 'h0'
tag('li', content: "#{@tag_text}#{child_html}")
end
private def tag(name, content:)
%(<#{name}>#{content}</#{name}>)
end
end
def header_extractor(html_partial, header_levels: %w(h1 h2 h3))
root_node = TreeNode.new('h0', 'ROOT')
Nokogiri("<html>#{html_partial}</html>")
.css(header_levels.join(', '))
.reduce(root_node) do |current_tree, tag|
current_tree = current_tree.parent until current_tree.descendant?(tag.name)
current_tree.add_child(tag.name, tag.text)
end
root_node
end
def header_hierarchy(html)
header_extractor(html).to_html
end
describe '#header_hierarchy' do
context 'EASY' do
it 'can extract a single header' do
fragment = "<h1>Foo</h1>"
result = '<ul><li>Foo</li></ul>'
expect(header_hierarchy(fragment)).to eq(result)
end
it 'can extract one nested level of header' do
fragment = "<h1>Foo</h1><h2>Bar</h2>"
result = '<ul><li>Foo<ul><li>Bar</li></ul></li></ul>'
expect(header_hierarchy(fragment)).to eq(result)
end
end
context 'MEDIUM' do
it 'can extract multiple levels of nested headers' do
fragment = "<h1>Foo</h1><h2>Bar</h2><h3>Baz</h3><h4>Bam</h4>"
result = '<ul><li>Foo<ul><li>Bar<ul><li>Baz</li></ul></li></ul></li></ul>'
expect(header_hierarchy(fragment)).to eq(result)
end
end
context 'HARD' do
it 'can extract multiple nested headers in multiple branches' do
fragment = "<h1>Foo</h1><h2>Bar</h2><h3>Baz</h3><h2>Bam</h2><h3>Ba</h3>"
result =
'<ul><li>Foo<ul><li>Bar<ul><li>Baz</li></ul></li><li>Bam<ul>' +
'<li>Ba</li></ul></li></ul></li></ul>'
expect(header_hierarchy(fragment)).to eq(result)
end
end
context 'LIVE - Integration' do
it 'can parse an entire document' do
require 'net/http'
fragment = Net::HTTP.get(URI("https://jquery.com/"))
result =
'<ul><li>jQuery<ul><li>Lightweight Footprint</li><li>CSS3 Compliant</li>' +
'<li>Cross-Browser</li></ul></li><li>What is jQuery?</li>' +
'<li>Other Related Projects<ul><li>Resources</li></ul></li>' +
'<li>A Brief Look<ul><li>DOM Traversal and Manipulation</li>' +
'<li>Event Handling</li><li>Ajax</li><li>Books</li></ul></li></ul>'
expect(header_hierarchy(fragment)).to eq(result)
end
end
end
…and the tests?
Finished in 0.44593 seconds (files took 0.21331 seconds to load)
5 examples, 0 failures
Awesome!
Have a Solution?
We’d love to see your solutions! Send us a tweet over at @SquareDev and we’ll highlight the best solutions at the start of our next challenge.
Until next time.
Want more? Sign up for your monthly developer newsletter or drop by the Square dev Slack channel and say “hi!”


